Модель рынка: постоянная пропускная способность - страница 10
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
1. если взять за аксиому первоначальную идею, то для начала нужен идеальный архиватор, а нам до него пока то как до луны http://unseal.narod.ru/molekula_dnk.html,
Да, количество информации, содержащееся в данных очень трудно даже оценить. Существующие алгоритмы сжатия (с потерей и без) далеко не идеальны.
2. что бы проверить идею, я думаю нужно сделать модель рынка по типу моделирования тикового потока в тестере, но на приличном промежутке времени, построить на базе этого потока минутные бары, сжать и сравнить результаты с реальными. На каком то этапе может быть прокол в чистоте эксперимента.
Это было проделано выше. В результате видно, что цВР это совершенно не СБ.
Марковиц и не только он в своих рассуждениях построения оптимального портфеля все время ссылается на утверждение, что цена - случайность.
Главное, что меня здесь интересует, это минимальное количество нужных пар, необходимых для анализа рынка? Если hrenfx найдет эти пары, я буду ему очень благодарен. Ссылаясь на эту тему https://www.mql5.com/ru/forum/114579 хочу сказать, что этот вопрос поднимается неоднократно, достаточно ли использование мажоров, или необходимо максимальное кол-во инструментов в кластере.
Существует метод, который легко находит мажоры среди любого набора ВР. При этом наименования ВР ему не нужны. Все исходит из анализа самих ВР.
Метод показывает, что на FOREX вся информация содержится в мажорах. При этом мажоры не однозначно определены, т.е. есть несколько наборов мажоров срдержащих одинаковое количество информации. Например:
Да, количество информации, содержащееся в данных очень трудно даже оценить. Существующие алгоритмы сжатия (с потерей и без) далеко не идеальны.
Алгоритмы сжатия это не алгоритмы работы с информацией, это алгоритмы оптимального кодирования. Понятие информации из теории кодирования это совершенно другое, нежели обычное понятие информации. Алгоритмами сжатия ты не оцениваешь количество информации, ты оцениваешь всего лишь степень оптимальности кодирования, т.е. насколько эти данные соответствуют вот этому методу кодирования на этом участке времени. Сгенерированные тобой (псевдо)случайные данные с нормальным распределением лучше соответствуют выбранному способу кодирования (база - LZ) и соответственно кодируется с меньшим объемом итогового кода, информация тут даже в стопятидесяти километрах рядом не лежала. И соответствующие у тебя выводы сравнения ВР и СБ неверны в корне.
Тебе уже несколько человек об этом другими словами написали. Даже Мишек тебе об этом же.
В итоге - туфта полная.
Если хочешь оценивать количество информации, так и надо это делать. Информацию оценивать. А не котировки сжимать.
Алгоритмы сжатия это не алгоритмы работы с информацией, это алгоритмы оптимального кодирования. Понятие информации из теории кодирования это совершенно другое, нежели обычное понятие информации. Алгоритмами сжатия ты не оцениваешь количество информации, ты оцениваешь всего лишь степень оптимальности кодирования, т.е. насколько эти данные соответствуют вот этому методу кодирования на этом участке времени. Сгенерированные тобой случайные данные с нормальным распределением лучше соответствуют выбранному способу кодирования (база - LZ) и соответственно кодируется с меньшим объемом итогового кода, информация тут даже в стопятидесяти километрах рядом не лежала. И соответствующие у тебя выводы сравнения ВР и СБ неверны в корне.
Тебе уже несколько человек об этом другими словами написали. Даже Мишек тебе об этом же.
В итоге - туфта полная.
Если хочешь оценивать количество информации, так и надо это делать. Информацию оценивать. А не котировки сжимать.
Да, количество информации, содержащееся в данных очень трудно даже оценить. Существующие алгоритмы сжатия (с потерей и без) далеко не идеальны.
А что, кстати, насчет факторного анализа?
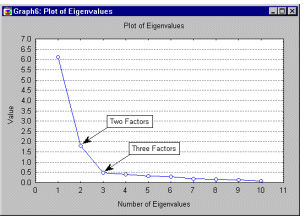
Помните вот эту схемку?
.
.
Она показывает степень влияния факторов на данные выборки.
Т.е. по схеме: если 1й, 2й и 3й факторы суммарно "весят" 8.5 единиц,
то все остальные- много меньше.
.
Возможно, я где-то видел еще другую диаграмму, на которой
слева была шкала в процентах. Та диаграмма показывала,
насколько N-ная точка на кривой факторов кумулятивно с предыдущими
объясняет происходящие колебания.
.
И скромный вопрос- что ж потом с этим делать...
И скромный вопрос- что ж потом с этим делать...
с электричеством тоже не знали что делать, однако...
И скромный вопрос- что ж потом с этим делать...
Креатив никто не оценит. Мало того, будут вопросы, типа: "А нафига это всё, какое отношение имеет решение задачи "О коммивояжере" непосредственно к FX?"
Рубите себе бабло по тихому, нафига Вам эта просветительская деятельность? - вопрос риторический.
Креатив креативу рознь. Конечно при желании и небольшой фантазии можно притянуть что-угодно к чему угодно ибо мир - это замкнутая и взаимосвязанная система.
Весь вопрос как отсеять малоконструктивный креатив, а попростому околонаучный флуд? Да очень просто. Для этого в большинстве случаев достаточно попытаться ответить на простой вопрос - какое отношение имеет решение данной задачи непосредственно к FX.
Ну а если разумного ответа никак не возникает, а вместо это возникают обвинения в зарубливании на корню околонаучного креатива, то тогда возникает другой естественный вопрос - кому такая просвятительская деятельность нужна и для чего? :)
народ!!! мы все здесь ради любви к искусству, или кто-то хочет с этим поспорить?