Fenômenos de mercado - página 33
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Não que isso esteja errado. Tão certo como a expressão "compre barato, venda caro". Não é apenas a exatidão que importa, mas também a formalidade. Não adianta construir construções filosóficas inteligentes e próximas ao mercado se elas (construções) são como leite para uma cabra.
Você acha que o tempo transcorrido após aceitar uma perda é difícil de formalizar? Ou o que é diferente?
Obrigado. Estarei pensando na SOM a meu bel-prazer.
O artigo no link fornece uma visão geral dos métodos de segmentação de séries temporais. Todos eles fazem a mesma coisa. Não que a SOM seja o melhor método para forex, mas também não é o pior, isso é um fato ))
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf
Meus colegas, infelizmente, não me permitem dar mais tempo para negociar, mas encontrei algum tempo e decidi pedir (para meu próprio interesse, então não vou esquecer :o, então voltarei mais tarde, quando tiver mais tempo livre)
A essência do fenômeno.
Deixe-me lembrar-lhe a essência deste fenômeno. Foi encontrado durante a análise da influência das "caudas longas" no desvio futuro dos preços. Se classificarmos caudas longas e observarmos as séries temporais sem elas, podemos observar alguns fenômenos curiosos, únicos para quase cada símbolo. A essência do fenômeno é uma classificação muito específica, baseada, de alguma forma, em uma abordagem "neural". Na verdade, esta classificação "decompõe" os dados brutos, ou seja, o próprio processo de citação em dois subprocessos, que são convencionalmente chamados de"alfa" e"betta". De modo geral, o processo inicial pode ser dividido em mais subprocessos.
Sistema com estrutura aleatória
Este fenômeno se aplica muito bem a sistemas com estrutura aleatória. O modelo em si vai parecer muito simples. Vejamos um exemplo. A série inicial EURUSD M15(precisamos de uma amostra longa, e o menor quadro possível), de algum "agora":
Etapa 1: Classificação
A classificação é feita e são obtidos dois processos"alfa" e"beta". Os parâmetros do processo de controle são definidos (o processo que trata da "montagem" final de uma cotação)
Etapa 2 Identificação
Para cada sub-processo, é definido um modelo baseado na rede Volterry:
Oh que dor identificá-los.
Passo 3 Previsão de sub-processo
Uma previsão é feita para 100 contagens para cada processo (por 15 minutos, ou seja, pouco mais de um dia).
Etapa 4: Modelagem de simulação
Um modelo de simulação é construído, o que irá gerar o número x.o. de implementações futuras. O esquema do sistema é simples:
Três aleatorizações: um erro para cada modelo e condições de transição de processo. Aqui estão as realizações em si (a partir do zero):
Passo 5: A solução comercial.
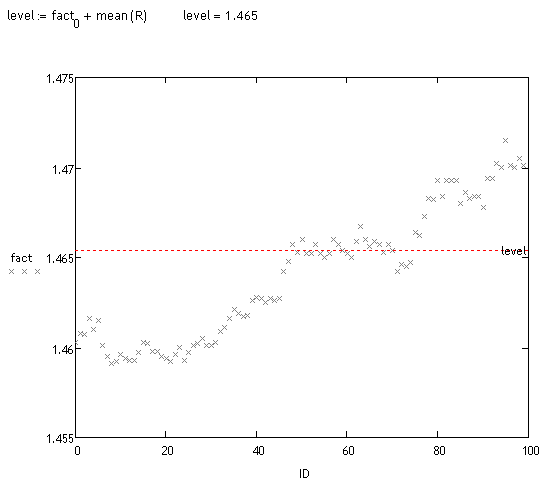
É feita uma análise tendenciosa dessas realizações. Isto pode ser feito de diferentes maneiras. Visualmente, você pode ver que uma grande massa de trajetórias é deslocada. Vejamos o fato:
<>
Testes preliminares
Levou cerca de 70 "medidas" ao acaso (leva muito tempo para contar). Cerca de 70% do sistema detectou o desvio correto, portanto ainda não está dizendo nada, mas espero voltar a esta pista em alguns meses, embora eu ainda não tenha terminado de trabalhar no projeto principal :o(.
para dizerfuji
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
Não, tudo está correto. Foi um dos temas de discussão em várias dezenas de páginas deste tópico. Tudo o que considerei necessário - escrevi. Infelizmente, não tenho tempo para desenvolver mais o tema. Além disso, este fenômeno em particular, embora interessante, não é muito promissor. O fenômeno das "caudas longas" aparece em horizontes longos, ou seja, onde há grandes desvios de trajetórias, mas para este fim é necessário prever longe os processos alfa e betta (e outros processos). E isto é impossível. Não existe tal tecnologia...
:о(
a todos
Colegas, acontece que há cargos aos quais eu não respondi. Perdoe-me, não vale a pena tentar mudar agora.
Prohwessor Fransfort, por favor, responda qual programa você usa para sua pesquisa.
E também...se alguém tiver um manual em russo ou um rústico para o programa http://originlab.com/ (OriginPro 8.5.1)
Um resultado interessante.
Este fenômeno pode ser devido ao fato de que os dados históricos são preços de licitação? (A Lambda na experiência é comparável à propagação).
Você não acha que faz mais sentido testar a qualidade do processo de "tendência" resultante usando a regressão linear com coeficientes constantes por partes quando visto como funções do tempo?
Você pode somar os incrementos filtrados e obter dois processos: