"New Neural" es un proyecto de motor de red neuronal de código abierto para la plataforma MetaTrader 5. - página 9
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
No puede ser así. Diferentes tipos en diferentes capas. Te digo que incluso podrías hacer de cada neurona una capa independiente.
Sobre el buffer, déjame darte un ejemplo. Déjame llegar a casa.
Una capa es una unión de neuronas independientes entre sí en una iteración.
Quién dice que no puede ser, pero yo quiero, pero me cortas las alas :o)
Nunca se sabe lo que la gente puede inventar, y decirles que todas las neuronas de una capa deben tener el mismo número de entradas.
Todos ellos deben ser diferentes incluso para las neuronas de la misma capa, de lo contrario sólo obtendremos un montón de algoritmos (montones de ellos en Internet), que requerirán alguna edición con el fin de atar algo.
SZY ¿Cuánto más difícil sería el algoritmo si cada neurona tuviera una capa independiente?
¿Quién puede aconsejarme sobre algún software de dibujo online para diagramas y demás?
Google Docs tiene dibujos, puedes compartirlos.
Puedo hacer algún trabajo de dibujo a tiempo parcial, siempre que no sea más de 1 hora al día.
Bien, para mí, 4 de las redes implementadas son de interés
1. Redes de Kohonen, incluyendo SOM. Es bueno utilizarlo para la partición de clústeres cuando no está claro lo que hay que buscar. Creo que la topología es bien conocida: vector como entrada, vector como salida o bien salidas agrupadas. El aprendizaje puede ser con o sin profesor.
2. MLP , en su forma más general, es decir, con un conjunto arbitrario de capas organizadas como un gráfico con retroalimentación. Se utiliza mucho.
3. Red de recirculación. Francamente, nunca he visto una buena implementación no lineal que funcione. Se utiliza para la compresión de información y la extracción de componentes principales (PCA). En su forma lineal más sencilla, se representa como una red lineal de dos capas en la que la señal puede propagarse desde ambos lados (o de tres capas en su forma desplegada).
4. Red Eco. En principio, similar a la MLP, aplicada también allí. Pero totalmente diferente en la organización y tiene un tiempo de aprendizaje bien definido (bueno, y siempre produce un mínimo global, a diferencia).
5. PNN... no lo he usado, no sé cómo. Pero creo que encontraré a alguien que lo haga.
6. Modelos de lógica difusa (no confundir con las redes probabilísticas). No se ha aplicado. Pero puede ser útil. Si alguien encuentra información que arroje plz. Casi todos los modelos son de autoría japonesa. Casi todos se construyen manualmente, pero si fuera posible automatizar la construcción de la topología por medio de una expresión lógica(si lo recuerdo bien), sería increíblemente genial.
+ redes con aumento evolutivo del número de neuronas o viceversa.
+ aloritmos genéticos + métodos de aceleración del aprendizaje.
Encontré una pequeña clasificación como esta
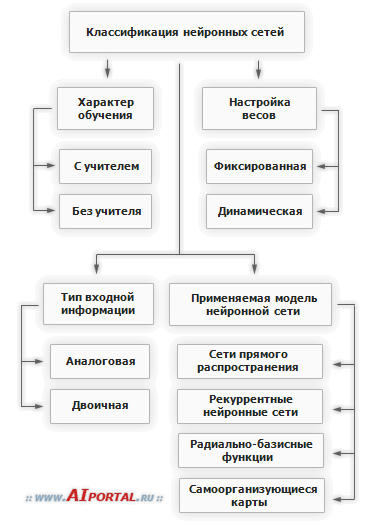
+ aloritmos genéticos
La genética consume muchos recursos adicionales. Los algoritmos de gradiente son mejores.
¿Por qué decidir por los usuarios lo que necesitan? Hay que darles la posibilidad de elegir. La PNN, por ejemplo, también consume muchos recursos.
La biblioteca debe ser universal y vasta, lo que permite encontrar variantes de soluciones y no en el conjunto de backpropagation estándar, que se puede encontrar en la web.
Una capa es una unión de neuronas independientes entre sí en una iteración.
¿Qué sentido tiene eso?
Nunca se sabe lo que la gente puede inventar, y decirles que todas las neuronas de la capa deben tener el mismo número de entradas.
Cada neurona tiene una entrada y una salida.
Todos los tipos y conexiones pueden ser diferentes incluso para las neuronas de la misma capa, esto debe tenerse en cuenta, de lo contrario sólo obtendremos un montón de algoritmos (muchos de ellos en Internet), que necesitan ser moldeados con el fin de conectar algo.
En primer lugar, no he terminado. En segundo lugar, ver las reglas. Críticas después. No ves el modelo en su conjunto y empiezas a criticar. Eso no es bueno.
SZY ¿Cuánto más difícil sería el algoritmo si cada neurona tuviera una capa independiente?
¿Un algoritmo para qué? Sólo retrasaría el aprendizaje y el funcionamiento.
¿Y qué es exactamente una entidad "amortiguadora"?
El amortiguador es la entidad a través de la cual se comunican las sinapsis y las neuronas. Una vez más, mi modelo es muy diferente al biológico.
_____________________
Siento no haberlo terminado ayer. Se olvidó de pagar el internet, se cortó :)
Una capa es una unión de neuronas independientes entre sí en una sola iteración.
Quién dice que no puede ser, pero yo quiero, pero me cortas las alas :o)
No sé qué se le puede ocurrir a la gente, se puede decir que todas las neuronas de una capa deben tener el mismo número de entradas.
Y los tipos y las conexiones pueden ser todos diferentes incluso para las neuronas de una capa, de esto tenemos que depender, de lo contrario sólo obtendremos un montón de algoritmos (muchos de ellos en Internet) de los cuales tenemos que buscar algo para conectar.
SZY ¿Cuánto más difícil sería el algoritmo si cada neurona tuviera una capa independiente?
Teóricamente es posible, en la práctica no me he encontrado con algo así. Incluso con la idea por primera vez.
Creo que, con fines puramente experimentales, se puede pensar en su aplicación, en el marco del proyecto de aplicación de una capa "abigarrada" no es probablemente la mejor idea en términos de costos de mano de obra y la eficiencia de la aplicación.
Aunque a mí personalmente me gusta la idea, al menos esa posibilidad podría merecer ser discutida.
¿Por qué decidir por los usuarios lo que necesitan?
? La genética es un método de aprendizaje. Lo correcto, en mi opinión, es ocultar los algoritmos de aprendizaje, eligiendo primero el mejor.
? La genética es un método de aprendizaje. Lo más correcto es enterrar los algoritmos de aprendizaje, preseleccionando el óptimo.
¿Trabajar con el NS es sólo elegir su topología? El método de entrenamiento también juega un papel importante. La topología y el aprendizaje están estrechamente relacionados.
Todos los usuarios tienen su propio imho, así que no puedes quitarles la mitad de la toma de decisiones.
Tenemos que crearun constructor de redes que no esté limitado por ningún preajuste. Y lo más universal posible.
sargazo:
La biblioteca debe ser universal y vasta, abriendo la puerta a variantes de soluciones, no en el conjunto estándar de retropropagación, que se puede encontrar en la web de todos modos.
¿Trabajar con el NS es sólo elegir su topología? El método de entrenamiento también juega un papel importante. La topología y el aprendizaje están estrechamente relacionados.
Todos los usuarios tienen su propio imho, así que no puedes tomar la mitad de la decisión por ti mismo.
Tenemos que crearun constructor de redes que no se limite a ningún preajuste. Y lo más universal posible.