Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 3251
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Gracias, profesor.
Si hay muchas dimensiones (características), incluso más de 5, NO vale la pena buscar proximidad directa entre líneas, es mejor reducir la dimensionalidad.
Dos enemigos: el sobreentrenamiento y la visión de futuro.
Se ha escrito mucho sobre el sobreentrenamiento: el modelo es demasiado "similar" a la serie original. Todo el mundo está familiarizado con él, ya que el sobreentrenamiento es un resultado habitual de los probadores.
¿Qué es "mirar hacia delante"?
¿Es correcto decir que ésta es la principal tarea a la que se dedica el Ministerio de Defensa?
La situación es como en la física moderna, ¿quieres montar o conducir? La física solía intentar entender cómo funciona el mundo, pero ahora sólo extienden fórmulas sobre los datos, inventan entidades virtuales, nadie entiende nada, todo es muy complicado.
En el tratamiento de datos ocurre lo mismo. Antes, tomábamos un problema, intentábamos entenderlo, luego escribíamos un algoritmo a mano, optimizábamos los cálculos. Para simplificar la tarea, se descuidaban algunas relaciones, otras se reducían a una forma lineal. Cuando hubo suficiente potencia y datos, la solución del problema se trasladó a un optimizador (a grandes rasgos, como en MT tester), que selecciona los coeficientes de algún polinomio. Nadie entiende cómo se calcula, no hay plena confianza en el resultado, pero este enfoque es capaz de tener en cuenta las relaciones no lineales y no obvias, acelerar algunos cálculos científicos en órdenes de magnitud.
Cuando la solución es obvia, hay que utilizar el enfoque clásico. Pero en condiciones de gran incertidumbre, el MO no es una panacea (por eso añaden ruido a las imágenes en los captcha).
Si hay muchas dimensiones (atributos), incluso más de 5, NO vale la pena buscar la proximidad directa entre filas, es mejor reducir la dimensionalidad
1 valor de cada característica no es suficiente
.
¿dónde he dicho un valor?
¿y dónde he dicho yo un valor?
Digo
al reducir una dimensión, nadie reduce a una dimensión, es posible, pero no lo hacen.
He dicho
¿Utiliza la convolución o predictores básicos que giran a lo largo de la historia?
Dos enemigos: el sobreentrenamiento y mirar hacia delante.
Se ha escrito mucho sobre el sobreentrenamiento: el modelo es demasiado "similar" a la serie original. Todo el mundo está familiarizado con él, ya que el sobreentrenamiento es un resultado habitual de los probadores.
¿Qué es "mirar hacia delante"?
Obviamente, utilizar información en la toma de decisiones que no se conocía en ese momento.
En mi humilde opinión, la razón principal de la frecuente aparición de "mirar hacia delante" es que, por su propia naturaleza, la CT es un algoritmo en línea, y su creación es un algoritmo fuera de línea.
Par plano, centinelas
patrón encontrado en 15 segundos :) A partir de 2020, todo lo anterior es OOS
optimizado ligeramente los parámetros de 2019
upd
El mismo patrón funciona también en otro personaje
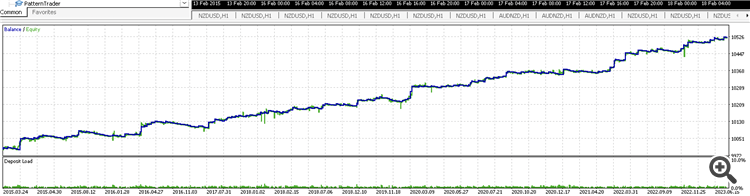
Es más rápido que MO