Discusión sobre el artículo "Redes neuronales: así de sencillo (Parte 2): Entrenamiento y prueba de la red"
Este artículo es interesante. Ni siquiera he intentado mirar a las redes neuronales antes, creyendo que son un "bosque oscuro" y todo lo que leí sobre este tema antes me repugnaba por la abundancia de palabras incomprensibles, pero en este artículo, de hecho, la teoría es bastante simple y comprensible, ¡gracias al autor por ello!
Y me gustaría aclarar esta frase:"Ambos EAs mostraron resultados similares con una tasa de acierto de poco más del 6%." ¿Estoy en lo cierto al entender que después de la primera "pasada" de entrenamiento, el pronóstico de la red neuronal se justificó sólo en un 6%.
Y después de 35 épocas de entrenamiento - sólo el 12% ???
Un resultado tan bajo no motiva a estudiar el tema más a fondo.
¿Cuáles son los métodos para mejorar la precisión de la predicción?
Buenas tardes, Dimitri.
El tema es muy interesante y necesario. Gracias por estos artículos).
1. Tengo una pregunta sobre el código del método Traine(... ):
TempData.Clear(); bool sell=(High.GetData(i+2)<High.GetData(i+1) && High.GetData(i)<High.GetData(i+1)); //в строчке ниже скорее всего не верно определяется Low фрактал bool buy=(Low.GetData(i+2)<Low.GetData(i+1) && Low.GetData(i)<Low.GetData(i+1)); //знаки сравнения нужно поменять наоборот buy=(Low.GetData(i+2)>Low.GetData(i+1) && Low.GetData(i)>Low.GetData(i+1));/
Cuando ejecuté la versión modificada en el entrenamiento los resultados mejoraron:
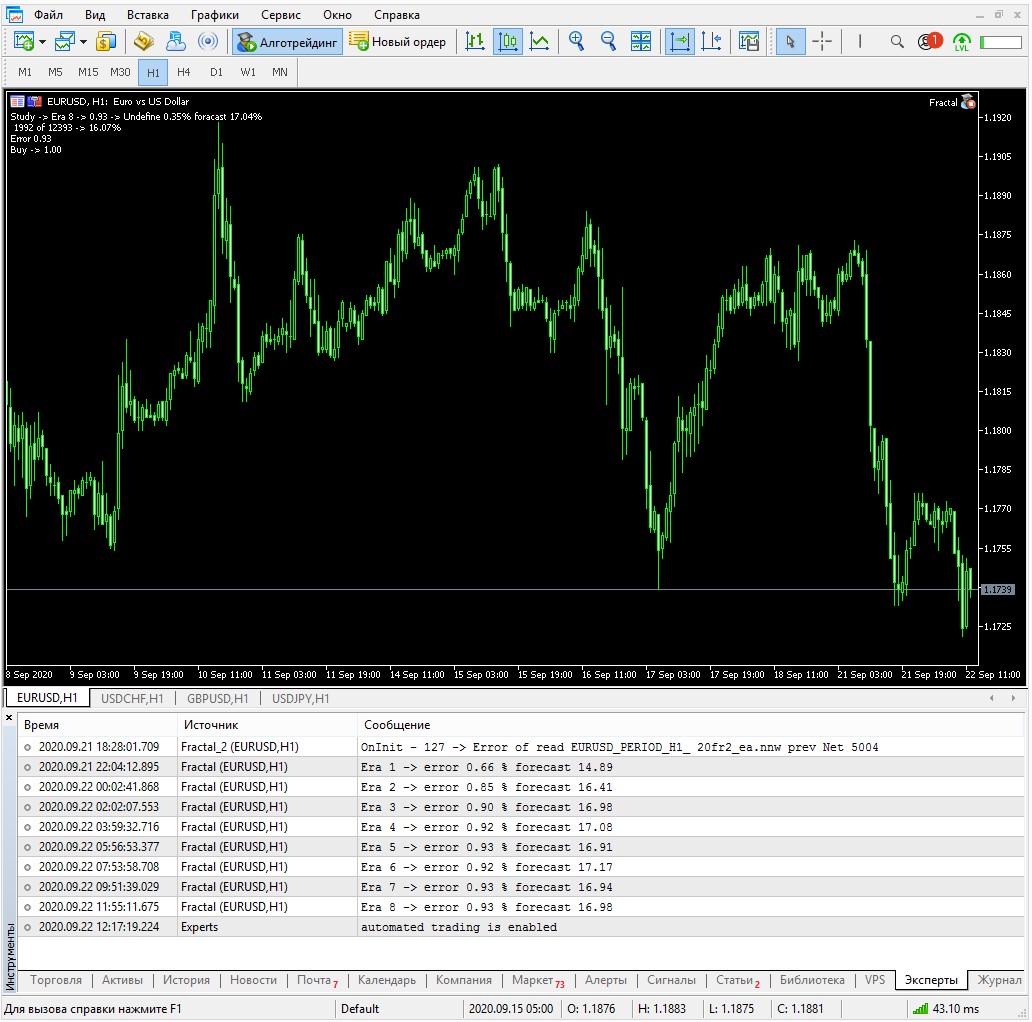
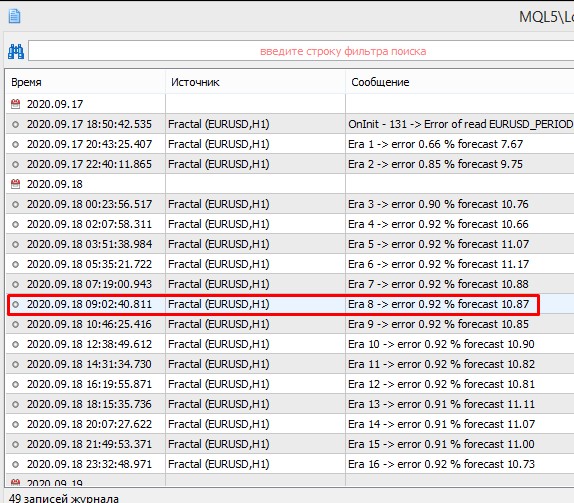
Ya en epoch 8 la precisión fue de 16,98% contra la antigua variante en la misma epoch 10,87%
2. ¿Por qué la red neuronal multicapa tiene un % de precisión tan bajo, no llega al 50%?
Buenas tardes, Dimitri.
El tema es muy interesante y necesario. Gracias por estos artículos).
1. Tengo una pregunta sobre el código del método Traine(... ):
Cuando ejecuté la versión modificada en el entrenamiento los resultados mejoraron:
Ya en epoch 8 la precisión fue de 16,98% frente a la antigua variante en la misma epoch 10,87%.
Gracias por el comentario, Alexander. Un desafortunado error de copypaste.
Buenas tardes, Dimitri.
2. ¿Por qué la red neuronal multicapa tiene un % de precisión tan bajo, no llega al 50%?
Escribí en el primer artículo que tomé indicadores aleatorios de los estándar con parámetros estándar. Una red neuronal es una buena herramienta, pero no algo sobrenatural. Busca patrones donde los hay. Pero si no hay patrones en los datos brutos, no los encontrará por sí sola. Dar exactamente con un fractal es una tarea bastante difícil y, para ser sincero, no esperaba dar con un resultado exacto. Pero lo que conseguí da pie para seguir trabajando.
Gracias por el comentario, Alexander. Un desafortunado error de copypaste.
Suele ocurrir)
En el primer artículo escribí que tomé indicadores aleatorios de los estándar con parámetros estándar. Una red neuronal es una buena herramienta, pero no algo sobrenatural. Busca patrones donde los hay. Pero si no hay patrones en los datos brutos, no se le ocurrirán por sí sola. Dar exactamente con un fractal es una tarea bastante difícil y, para ser sincero, no esperaba dar con un resultado exacto. Pero lo que conseguí da pie para seguir trabajando.
Tiene sentido).
Gracias, tu trabajo es genial en cualquier caso )
Dmitry, ¡buenas tardes!
Muy interesante la serie de artículos sobre redes neuronales. En este momento estoy experimentando con diferentes conjuntos de indicadores y tareas para la red. Decidí establecer una tarea para la red para determinar la probabilidad de ocurrencia de la siguiente barra, ya sea con el nivel Hight mayor que el nivel Open de la barra actual en 100 puntos, o con el nivel Low menor que el nivel Open de la barra actual en 100 puntos.
if(add_loop && i<(int)(bars-MathMax(HistoryBars,0)-1) && i>1 && Time.GetData(i)>dtStudied && dPrevSignal!=-2) { TempData.Clear(); double DiffMin=100; double DiffLow=Open.GetData(i+1)-Low.GetData(i); double DiffHigh=High.GetData(i)-Open.GetData(i+1); bool sell=(DiffLow>=DiffMin); bool buy=(DiffHigh>=DiffMin); TempData.Add((double)buy); TempData.Add((double)sell); TempData.Add((double)(!buy && !sell)); Net.backProp(TempData); ... }
Al probar el Asesor Experto, las etiquetas de los fractales predichos se muestran en el gráfico, pero la estadística de fractales predichos correctamente y no encontrados no se actualiza y siempre es igual a 0,00%. ¿Puede indicarme el error que cometí?
if(DoubleToSignal(dPrevSignal)!=Undefine) { if(DoubleToSignal(dPrevSignal)==DoubleToSignal(TempData.At(0))) dForecast+=(100-dForecast)/Net.recentAverageSmoothingFactor; else dForecast-=dForecast/Net.recentAverageSmoothingFactor; dUndefine-=dUndefine/Net.recentAverageSmoothingFactor; } else { if(sell || buy) dUndefine+=(100-dUndefine)/Net.recentAverageSmoothingFactor; }

- www.mql5.com
Dimitri, ¡buenas tardes!
Muy interesante la serie de artículos sobre redes neuronales. En este momento estoy experimentando con diferentes conjuntos de indicadores y tareas para la red. Decidí establecer una tarea para la red para determinar la probabilidad de ocurrencia de la siguiente barra, ya sea con el nivel Hight mayor que el nivel de apertura de la barra actual en 100 puntos, o con el nivel Low menor que el nivel de apertura de la barra actual en 100 puntos.
Al probar el Asesor Experto, las etiquetas de los fractales predichos se muestran en el gráfico, pero la estadística de fractales predichos correctamente y no encontrados no se actualiza y siempre es igual a 0,00%. ¿Puede indicarme el error que cometí?
Buenas tardes,
has especificado Diff=100, por lo que tengo entendido es en pips. Y la diferencia se calcula por precio. Es decir, para EURUSD se calcula como 1,16715-1,15615=0,01. Como resultado, usted no tiene datos comparables y vender y comprar siempre será falso.
Buenos días,
has especificado Diff=100, por lo que tengo entendido es en puntos. Y la diferencia se calcula por precio. Es decir, para EURUSD se calculará como 1.16715-1.15615=0.01. Como resultado, usted no tiene datos comparables y vender y comprar siempre será falso.
Tengo una pregunta: ¿Por qué diablos estudiar el tema de toda una serie de artículos mega abstruso si esta red neuronal tiene una precisión insignificante ... Creo que el tema debe ser interrumpido o la EA debe ser mejorado.
Me gustaría añadir que mi red neuronal es mucho más "compleja" que la tuya, pero está garantizada para dar un 70-80% de entradas correctas y al mismo tiempo es mucho más simple en su estructura ....
y añadiría que hay muchas otras redes neuronales con mucha más precisión que la tuya.
En general, tengo la impresión de que te pagan dinero por tus artículos, pero no sirven para nada .... Lo siento.
Tampoco estoy de acuerdo con el título "Las redes neuronales son fáciles", los que se dedican al aprendizaje automático en big data saben - no es fácil ... :-)
>Para evaluar el rendimiento de la red se puede utilizar el error cuadrático medio de predicción, el porcentaje de fractales correctos predichos, el porcentaje de fractales perdidos.
No estoy de acuerdo con esto en absoluto - el resultado es sólo el balance final, el beneficio neto y sólo y nada más ... nada de nada, no es ciencia por ciencia, es ciencia por beneficio.
Incluso te diré por qué: hay Asesores Expertos con un 60% de precisión ... pero gracias a un sistema inteligente dan más beneficios que los asesores con 80% de precisión ...
y usted debe comenzar con el gráfico de las estadísticas finales de comercio de su EA o no tiene sentido leerlo, inmediatamente me vuelvo hacia abajo si no hay estadísticas o no cumple con mis requisitos, entonces no se puede leer en absoluto, a continuación se muestra la prueba de mi neuronka no muy inteligente

y usted debe comenzar con el gráfico del estado final de comercio de su EA o no tiene sentido leerlo, inmediatamente me vuelvo hacia abajo, si no hay estado o no cumple con mis requisitos, entonces usted no puede leer en absoluto, a continuación se muestra la prueba de mi neuronka no muy inteligente.
entonces usted no necesita la sección de artículos.
Para sus necesidades - un steith rentable, las secciones Codobase y Mercado son adecuados.
sí, por cierto, incluso su mensaje no se ajusta a sus necesidades, por lo que puede ser ignorado también? )))
usted necesita artículos, los necesita para probar correctamente un EA de trabajo sobre la base de la red neuronal, hay una alta probabilidad de que su estado es de un probador, no sólo de MT4, pero puede que no haya dividido la muestra de formación en tren / prueba / validación.
Necesitas artículos para aprender a escribir un buen código estructurado y legible - Creo que el código del autor en el artículo es perfecto para estos requisitos.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Redes neuronales: así de sencillo (Parte 2): Entrenamiento y prueba de la red:
En el presente artículo, proseguiremos nuestro estudio de las redes neuronales, iniciado en el artículo anterior, y analizaremos un ejemplo de uso en los asesores de la clase CNet que hemos creado. Asimismo, analizaremos dos modelos de red neuronal que han mostrado resultados semejantes tanto en su tiempo de entrenamiento, como en la precisión de sus predicciones.
La primera época depende al máximo de los pesos de la red neuronal elegidos al azar en la etapa inicial.
Tras 35 épocas de entrenamiento, la brecha en las estadísticas se amplió levemente a favor del modelo de regresión de la red neuronal:
Los resultados de la simulación muestran que ambas variantes de organización de la red neuronal ofrecen resultados semejantes tanto en su tiempo de entrenamiento, como en la precisión de sus predicciones. Asimismo, los indicadores obtenidos muestran la necesidad de gastar tiempo y recursos adicionales para el entrenamiento. Los lectores que deseen analizar la dinámica de aprendizaje de las redes neuronales, podrán estudiar las capturas de pantalla de cada época de entrenamiento en el archivo adjunto.
Autor: Dmitriy Gizlyk