What to feed to the input of the neural network? Your ideas... - page 75
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
Search paradigm: ...
Any trading strategy is that such-and-such trading action is taken only under such-and-such circumstance (or set of circumstances).
If this is not honoured, it is not a strategy.
Hence the following hypothesis (assumption) is inevitable:
If a certain trading result was obtained under a certain circumstance, then there is an expectation that under the same (or very similar) circumstance the same result will be obtained.
The formula of error back propagation is designed in such a way that in the process of its application, the "circumstance on the inputs X" is moved (summarised/summarised) to the "weight values W".
In other words, the weight values are simply the sum of many circumstances, each of which has been summed with its own coefficient-value.
Where the coefficient figure is the result of a given trade action taken under a given circumstance.
So, in general terms, although the formula is a bit more complicated ...
1. If under two similar circumstances two contradictory trading results are obtained, then during the procedure of reverse propagation of error these circumstances mutually extinguish each other (moving from X to W).
2. If under two antisimilar (mirror) circumstances two similar (in value and in sign) trade results were obtained, then under the procedure of the reverse propagation of the error these circumstances also cancel each other out.
3. if two similar (in value and in sign) trading results have been obtained under two similar circumstances, then these circumstances add up with each other during the procedure of error back propagation.
And here it is obvious that the neural network simply catches the relationship between circumstances and their trading results, i.e. detects patterns.
And not only detects, but also refreshes them in the process of receiving new history.
If, of course, there is something in item 3, against item 1 and item 2 ...
Well, and fiddling with the neural network can be started only with the unambiguous acceptance of the above hypothesis.
And it may turn out to be wrong. ))
As for the removal of a single trading result as an estimation of a single circumstance under which this result was obtained, I believe that for different circumstances the estimations should be equal.
That is, the same so-called "other equal condition" must be met for different circumstances.
Only one factor can be such a condition, the time interval of the transaction retention.
...
Hence the following hypothesis (assumption) is inevitable :
...
You are right: I have hypotheses, assumptions and fantasies.
This thread is basically about the same thing. What to think up, how to wrap up.
And if there is some explanation, reason, motive - it is even more interesting.
As for NS, my attitude to them is as follows: it is a box with a set of "if, else" rules. Not otherwise. Even if the system is adaptive, the very process of adaptation is an "if this, then that" rule. Otherwise, it is a random process.
And considering that the market is striving or completely unique, my head is drowning in paradoxes: any attempt to explain the existence of eternal regularities (including regularities in adaptation mechanisms - i.e., change/re-optimisation/re-learning) is bogged down in impossibility and wandering in chaos .
As a result: I simply dig into simple systems in spite of them. Peeking at the results of complex ones, if articles appear.
As to the removal of a trading result as an assessment of the circumstance in which that result was obtained, I believe that for different circumstances the assessments should be equal.
That is, the same so-called "other equal condition" should be observed for different circumstances.
Only one factor can act as such a condition, the time interval of the transaction retention.
The essence of using the strategy is receiving a signal in similar market conditions (global pattern), so the indicators of predictors describe this moment of the event, not the whole market, which, in theory, reduces the contradictions within them with the target. In the end, learning is concerned with finding rule elements that reinforce or reduce the original pattern. The minus in this approach is the significant reduction of examples in the sample.
As for the markup for time, it is also doubtful, as we are interested in the vector of price movement in trading, or better even the trajectory, so ideally the markup should take into account not only where the price will be in n bars, but also how it will get there.
so ideally the markup should take into account not only where the price will be in n bars, but also how it will get there.
" The downside of this approach is a significant reduction of examples in the sample."
I agree, it does.
But otherwise it's "mush".
"... so ideally the markup should take into account not only where the price will be in n bars, but also how it will get there."
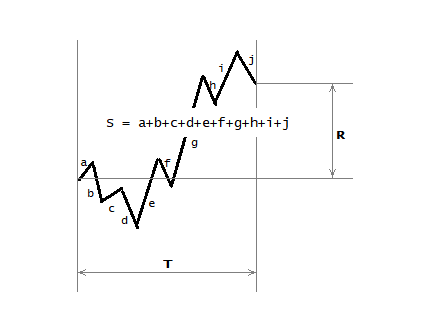
Hence we get the so-called R/S score, whose value ranges from -1 to +1, where :
- S is the total path, i.e. the length of the trajectory,
- R is the net path, as the distance between the start point of the trajectory and the end point of the trajectory, which can be negative.
But in order for the set of estimates obtained in this way to be equal to each other, the time interval T applied to obtain each estimate must be taken equal.
And I must say that such an estimation is still not self-sufficient.
" The minus in this approach is a significant reduction of examples in the sample."
I agree, it does.
But otherwise it's "mush."
"... so ideally the markup should take into account not only where the price will be in n bars, but also how it will get there."
Hence we get the so-called R/S score, whose value ranges from -1 to +1, where :
- S is the full path, i.e. the length of the trajectory,
- R is the net path as the distance between the starting point of the trajectory and the end point of the trajectory, which can be negative.
But, in order for the set of estimates obtained in this way to be equal to each other, the time interval T applied to obtain each estimate must be taken equal.
And I must say that such an estimation is still not self-sufficient.
As for NS, my attitude to them is that they are a box with a set of "if, else" rules. That's the way it is.
Not really.
Rather not even quite like that at all.
))
Not really.
It's more like not at all.
))
And when I asked the question: "If after training the input is 1 and the output is 2, does it correspond to the rule "if the input is 1, the output is 2" - even Dipsic had to agree".
It is rather about the essence of the box.
Try to answer the same question.
Hence we obtain the so-called R/S score, whose value ranges from -1 to +1, where :
- S is the total path, i.e. the length of the trajectory,
- R is the net path as the distance between the starting point of the trajectory and the end point of the trajectory, which can be negative.
The option is an interesting one. I haven't tried it. It turns out you need a regression model for it. You can try metric and R square then, or a modification - to estimate the scatter of deviation from a straight line....
I consider the problem differently - I put a question for classification - whether the price will reach the SL or TP point, and a variant - whether the price will reach the SL before the market goes to a different state (the beginning of the trend) or not. It is important to put SL on something similar to the reference points, not just in pips.
But, in order for the set of estimates obtained in this way to be equal to each other, the time interval T used to obtain each estimate should be taken the same.
The minus here is that the price may move in the right direction for a third of time in the beginning, and then slip in flat to the starting point. If we consider that the price moves from level to level, then this approach looks strange, the models should be understood at once:
1. whether a significant level will be reached in the time interval
2. How long it will take to reach the level
3. What will happen after reaching it (it depends on the answer to the second question - enough time for a pullback or a breakdown after flat).
While when reaching a significant level, it is important to evaluate the movement up to this level.
In general - a different paradigm, which one is more correct - can be determined through experimentation.
What time interval do you use?
I would also note the disadvantage of using continuous sampling - obtaining similar examples on neighbouring bars, which can quantitatively outweigh in one or another direction, giving an incorrect probability shift, if you trade not on every bar later on.
Chat told me the same thing
And when I asked the question: "If after training the input is 1 and the output is 2, does it correspond to the rule "if the input is 1, the output is 2" - even Dipsic had to agree".
It's more about the essence of the box.
Try to answer the same question.
Far be it from me to "chat gpt", much less "dipsic".
To be honest, I've never once interacted with them (hmmm... maybe I should start...).
Then again, I'm far from a professional in this case.
Let's say, on the example of a perseptron (single neuron) :
The concept is not "if else", but "similar" or "dissimilar".
The output of the perseptron is the sum of the products of the values of X by the values of W element by element.
And if the image X is identical or very similar to the image W (which was previously formed during training), then the output is the maximum possible value in the context of "the sum of products of X on W".
Provided, of course, that in the process of training the images X were previously normalised to the range from 0 to +1, or to the range from -1 to +1.
And without such normalisation, there will be no adequate result.
(However, there are other ways to normalise.)
In other words, if the perseptron "saw" (on inputs X) what it was taught (and its learning is stored on W), it will produce the highest result on the sum of products.
However, it is always possible to SELECT such an image X, at presentation of which the perseptron will produce an even higher result.
It should be noted here that the presented image must also be pre-normalised to the range from 0 to +1, or to the range from -1 to +1.
And here the questions arise :
- what exactly should be this "highest result", on the basis of the highness of which we could conclude that the perseptron saw exactly what it was taught ?
- and should some corridor of highness be applied, a lower level of highness and an upper level of highness, or is only the lower one sufficient?
In general, these questions are valid both with and without the activation function.