Is there a pattern to the chaos? Let's try to find it! Machine learning on the example of a specific sample. - page 11
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
That's the point, it's better by a factor of 2 than on 5000+ features.
It turns out that all the other 5000+ chips only worsen the result. Though if you select them, you will surely find some improving ones.
It is interesting to compare what your model will show on these 2.
I have mat. expectation a little more than one, profit within 5 thousand, the accuracy writes 51% - ie the results are clearly worse.
Yes, and on the test sample I got a loss in all 100 models.I have mat. expectation a little more than one, profit within 5 thousand, the accuracy says 51% - that is, the results are clearly worse.
Yes, and on the test sample there was a loss in all 100 models.But on the first one, it's also losing.
On the second H1 sample? I'm improving on that one.
And on the first one, I'm losing too.
Yes, I'm talking about the H1 sample. I am initially trained on train.csv, stop on test.csv, and independent check on exam.csv, so the variant with two columns fails on test.csv. Yesterday's variants were also shedding, but there were also those that made a little bit of money.
So what kind of miracle charts have you got?And this is how valving forward with training on 20000 lines in 10000 lines. That is, the chart shows not 2 years, but 5. 2 years of them will have to sit in drawdown, then another year without profit, due to which the average winnings again dropped to 0.00002 per trade. Also not good for trading.
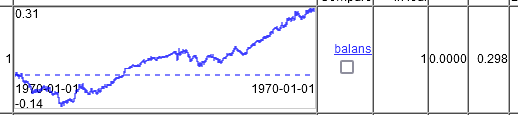
Only on 2 time columns.
The same settings on all 5000+ columns. Slightly better. 0.00003 per trade.
Profit 0.20600, on average 0.00004 per trade. Commensurate with the spread
Yes, the figure is already impressive. However, the target is marked to sell, and there the whole period on a large TF is selling, I think it also artificially improves the result.
It is more than 0.00002 on all columns, but as I said earlier " Spread, slippages, etc. will eat up all the gain". Teriminal shows the minimum spread per bar (i.e. during the whole hour), but at the moment of a trade it can be 5 - 10 pts, and on news it can be 20 and higher.
So the markup I have is taken on minute bars, spreads widen usually over a period of time, i.e. within a minute there will probably be a large spread all the time, or is it not so now? I haven't even figured out how the spread works in 5 - I find it more convenient for tests in 4.
You should look for models with average winnings of at least 0.00020 per trade. Then in real trading you may get 0.00010. This is for EURUSD, on other pairs like AUD NZD even 50 pts will not be enough, there spreads are 20-30 pts.
I agree. The first sample in this thread gives a mat expectation of 30 pips. That's why I still stick to the opinion that the markup should be smart.
Well again this is the best chart on the exam sample. How by trayne to choose settings that will then give the best balance on the exam one is a question without a solution. You choose by test. I trained on traine+test. Basically, what you have an exam, I have a test.
I think you should start by getting the majority of the sample to pass the selection threshold. Further, it might make sense to choose the least trained model of all - it has less fitting.
And this is how the roll forward with training on 20000 rows in 10000 rows. I.e. on the graph not 2 years, but 5. 2 years of them will have to sit in drawdown, then another year without profit, due to this the average winnings again dropped to 0.00002 per trade. Also not good for trading.
Only on 2 time columns.
The same settings on all 5000+ columns. Slightly better. 0.00003 per trade.
Still, it turns out that the other predictors can be useful as well. You can try to add them in groups, you can first sift for correlation and slightly reduce them.
Regarding the expectation matrix, maybe in this strategy it is more profitable to enter not by candle opening, but by the same 30 pips from the opening price - candles without tails are rare.
So the markup I have is taken on minute bars, spreads widen usually over a period of time, i.e. within a minute there will probably be a big spread all the time, or is it not so now? I haven't even figured out how the spread works in 5 - for me it's more convenient for tests in 4.
And on M1, too, the minimum spread for the bar time is kept. On ECH accounts almost all M1 bars have 0.00001...0.00002 rarely more. All senior bars are built from M1, i.e. the same minimum spread will be. You have to add 4 pts. commission per round (other brokerage centres may have other commission).
And yet, it turns out that the other predictors can also be useful. You can try to add them in groups, you can first sift for correlation and slightly reduce them.
Perhaps we should select them. But if adding 5000+ to 2 adds a small improvement, it may be faster to select 10 pieces by full brute force with model training. I think it will be faster than waiting for correlation for 24 hours. Only it is necessary to automate re-training in a loop directly from the terminal.
Doesn't katbusta have a DLL version? DLL can be called directly from the terminal. There was an article with examples here. https://www.mql5.com/ru/articles/18 and https://www.mql5.com/ru/articles/5798.
Perhaps we should select. But if adding 5000+ to the 2s gives a small improvement, it might be faster to select 10 pieces by full brute force with model training. I think it would be faster than waiting for correlation for 24 hours.
Yes, it is better to do it in groups at the beginning - you can do, say, 10 groups and train with their combinations, evaluate the models, eliminate the most unsuccessful groups, and regroup the remaining ones, i.e. reduce the number of predictors in the group and train again. I have used this method before - the effect is there, but again not fast.
Only you need to automate re-training in a loop directly from the terminal.
Doesn't catbust have a DLL version? DLL can be called directly from the terminal. There was an article with examples here. https://www.mql5.com/ru/articles/18 and https://www.mql5.com/ru/articles/5798.
Heh, it would be nice to get full learning control via terminal, but as I understand there is no ready solution. There is a library catboostmodel.dll that only applies the model, but I don't know how to implement it in MQL5. In theory, of course, it is possible to make an interface in the form of a library for training - the code is open, but I can't afford it.
Yes, it is better to start with groups - you can make, say, 10 groups and train them in combinations, evaluate the models, eliminate the most unsuccessful groups, and regroup the remaining ones, i.e. reduce the number of predictors in the group and train them again. I have used this method before - the effect is there, but again not fast.
I propose something else. We add features to the model one by one. And select the best ones.
1) Train 5000+ models on one feature: each of 5000+ features. Take the best one from the test.
2) Train (5000+ -1) models on 2 features: the 1st best feature and( 5000+ -1) the remaining ones. Find the second best one.
3) Train (5000+ -2) models on 3 features: on 1st, 2nd best feature and( 5000+ -2) remaining. Find the third best.
Repeat until the model improves.
I usually stopped improving the model after 6-10 added features. You can also just go up to 10-20 or as many features as you want to add.
But I think that selecting features by test is fitting the model to the test section of the data. There is a variant of selection by trayne with weight 0.3 and test with weight 0.7. But I think that is also a fit.
I wanted to do the roll forward, then the fitting will be for many test sections, it will take longer to count, but it seems to me that this is the best option.
Although you don't have automation for running catbusters.... 50+ thousand times it will be hard to retrain models manually to get 10 features.That's roughly why I prefer my craft over catbust. Even though it works 5-10 times slower than Cutbust. You had one model for 3 min, I had 22.
That's not what I'm suggesting. We add features to the model one by one. And select the best ones.
1) Train 5000+ models on one feature: each of 5000+ features. Take the best one from the test.
2) Train (5000+ -1) models on 2 features: the 1st best feature and( 5000+ -1) the remaining ones. Find the second best one.
3) Train (5000+ -2) models on 3 features: on 1st, 2nd best feature and( 5000+ -2) remaining. Find the third best.
Repeat until the model improves.
I usually stopped improving the model after 6-10 added features. You can also just go up to 10-20 or as many features as you want to add.
Approaches can be different - their essence is the same in general, but the disadvantage is of course common - too high computational costs.
But I think that feature selection by test is a fitting of the model to the test section of the data. There is a variant of selection by trayne with weight 0.3 and test with weight 0.7. But I think that is also a fit.
I would like to make valving forward, then the fitting will be for many test sections, it will take longer to calculate, but it seems to me that this is the best option.
That's why I'm looking for some rational grain inside the feature to justify its selection. So far I have settled on the frequency of recurrence of events and shifting the class probability. On average, the effect is positive, but this method evaluates actually by the first split, without taking into account the correlating predictors. But I think you should also try the same method for the second split, by removing from the sample the rows on predictor scores with strong negative predisposition.
Although you don't have automation to run catbusters.... 50+ thousand times it would be hard to retrain models manually to get 10 traits.
That's roughly why I prefer my craft over catbust. Even though it works 5-10 times slower than Cutbust. You had one model that took 3 min to count, I had 22.
Still, read my article.... Now everything works in the form of semi-automatic - the tasks are generated and the bootnik is launched (including tasks for the number of features to be used in training, i.e. you can generate all variants at once and launch them). In essence it is necessary to teach the terminal to run the bat file, which is possible I think, and control the end of training, then analyse the result, and run another task based on the results.
Only by changing the learning rate was it able to get two models out of 100 that met the criterion set.
The first one.
The second.
It turns out that, yes, CatBoost can do a lot, but it seems necessary to tune the settings more aggressively.
Do you select these models by the best on the test?
Or among a set of the best on the test - the best on the exam?