Diskussion zum Artikel "Schätzung der Kerndichte einer unbekannten Wahrscheinlichkeitsverteilung"
An den Autor. Noch bessere Ergebnisse erhält man, wenn man nicht die Verteilungsdichte, sondern die Verteilungsfunktion, d.h. das Integral der Dichte, schätzt: Erstens ist es einfacher, sie aus den Daten zu bilden, und da sie immer nicht abnehmend und zwischen 0 und 1 begrenzt ist, ist die Empfindlichkeit gegenüber der Wahl des Glättungsalgorithmus, sei es Kernel, Spline, Regression oder etwas anderes, viel geringer. Die Anforderungen an die Menge der verfügbaren Daten sind ebenfalls geringer, und zwar um eine Größenordnung.
Die Dichte kann, falls erforderlich, leicht durch numerische Differenzierung ermittelt werden.
Nun, die Dichte kann leicht durch numerische Differenzierung ermittelt werden, falls erforderlich.
Das mag sein. Ich kann dazu nichts sagen. Ich habe nicht einmal versucht, pdf über cdf zu bewerten. Wahrscheinlich hat sich das Vorurteil bewahrheitet, dass die Verwendung der Differenzierung eine erhebliche Steigerung der Genauigkeit der cdf-Schätzung erfordern würde. Darüber hinaus habe ich keine Veröffentlichungen gefunden, in denen die Methode cdf->pdf bewertet oder mit anderen Methoden verglichen wird. Wenn Sie Links zur Verfügung stellen können, wäre ich Ihnen sehr dankbar.
Die ursprüngliche Idee war, keine externen Tools zu verwenden, d. h. es wurde davon ausgegangen, dass alles nur mit MQL5-Tools implementiert werden sollte.
Das ist die Idee ausnahmslos aller Erfinder von Fahrrädern.
Schauen Sie sich an, was die entsprechenden Pakete in dieser Hinsicht bieten, und vergleichen Sie es mit dem, was Sie zur Verfügung gestellt haben - eine verschwindend geringe Menge dessen, was bei der Anwendung von Mathematik und Ökonometrie im Handel benötigt wird.
Vielleicht. Ich kann dazu nichts sagen. Ich habe nicht einmal versucht, pdf über cdf zu schätzen. Wahrscheinlich hat sich das Vorurteil bewahrheitet, dass die Verwendung der Differenzierung eine erhebliche Steigerung der Genauigkeit der cdf-Schätzung erfordern würde. Darüber hinaus habe ich keine Veröffentlichungen gefunden, in denen die Methode cdf->pdf bewertet oder mit anderen Methoden verglichen wird. Ich wäre Ihnen dankbar, wenn Sie mir Links nennen könnten.
Ich kann keine Referenzen angeben, weil ich sie nicht habe. Ich werde stattdessen diese Überlegungen anstellen.
Wenn wir ein pdf direkt auswerten, müssen wir den Definitionsbereich vorab in Intervalle unterteilen, und dabei gibt es zwei Probleme: Erstens wissen wir nicht, in wie viele Intervalle wir den Bereich besser unterteilen sollten, und zweitens wissen wir nicht, welche Art von Raster(einheitlich, ... ?) am besten wäre. Und wenn man bei der zweiten Frage noch irgendwie versucht hat, sie zu lösen, z. B. mit der Quantilpartitionierung, dann gibt es für die erste Frage meiner Meinung nach überhaupt keine universellen Methoden: alle mir bekannten haben Einschränkungen, die sie für Automatisierungsaufgaben wenig nützlich machen, wenn wir uns die Methode des Stocherns nicht leisten können.
Die cdf-Schätzung ist frei von diesen Nachteilen. In diesem Fall liegen die Schritte der Funktion genau dort, wo die Eingabedaten fallen, und so verschwindet das Problem der Wahl eines Gitters für den Interpolanten von selbst. Sobald das Gitter erstellt ist, ist es nicht schwierig, die Anzahl der Intervalle zu wählen: Wir kennen bereits die maximale Anzahl der Intervalle (und ihre Lage!!!), daher können wir durch Ausdünnen jede gewünschte Genauigkeit einstellen, und zwar jedes Mal auf einem natürlichen Gitter, das der Struktur der Eingabedaten am besten entspricht.
In der Praxis habe ich diese Technik verwendet, um nach lokalen Modi empirischer Verteilungen zu suchen, wenn die Anzahl der Datenproben 100 nicht übersteigt, und ich habe sehr glatte Ergebnisse erhalten, und visuell wird die Genauigkeit der Suche als ziemlich qualitativ definiert, mindestens 2-4 Hauptmodi werden fast ohne Abweichungen gefunden. Ich verwende jedoch einen anderen Glättungsalgorithmus, da ich die Kernel-Algorithmen aus verschiedenen Gründen nicht mag.
Alles völlig fair. Aber wie es mir scheint, bis auf einen Punkt, den Sie offenbar einfach nicht beachtet haben.
Ein bekannter Ausdruck für Kernelglätter ist "Kernel smooth".
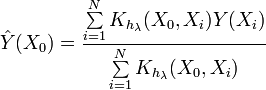
Eine auf einer solchen Glättung basierende Methode zur Schätzung von pdf könnte wie folgt aussehen (vereinfacht):
- Wir partitionieren die Eingabesequenz in Intervalle (Clustering, Binning)
- Glätten Sie das resultierende Histogramm.
Wenn Sie die Kernel-Glättung nicht mögen, können Sie z. B. p-spline verwenden. (Es ist wahrscheinlich besser, gleich p-spline zu wählen).
Mit diesem Ansatz zur Schätzung von pdf wird alles, was Sie gesagt haben, absolut richtig. Aber selbst in diesem Fall liefert diese Schätzmethode für Sequenzen mit großer Länge (>1000000) hervorragende Ergebnisse. Mit abnehmender Länge der Eingabesequenz kommen all die von Ihnen erwähnten Reize immer stärker zum Tragen.
Schauen wir uns nun den Ausdruck der Kernel-Dichte-Schätzung (KDE) an
![]()
Dieser Ausdruck unterscheidet sich von dem zuvor genannten. Wie wir sehen können, bestimmt dieser Ausdruck direkt den Wert der Wahrscheinlichkeitsdichtefunktion an einem bestimmten Punkt. Und was in diesem Fall wichtig ist, es gibt keine Unterteilung in Intervalle. Es werden direkt die Werte der Eingabesequenz verwendet.
Zumindest sehe ich die Situation bei KDE so. Der im Artikel beschriebene Algorithmus der pdf Schätzung kommt auf den ersten Blick mit Sequenzen von 20-30 Elementen Länge ganz gut zurecht. Manchmal möchten Sie vielleicht den Grad der Glättung verringern. Das kann man leicht tun, indem man im Code ersetzt
h=0.9*a/MathPow(N,0.2); // Silverman's Faustregeldurch
h=0.7*a/MathPow(N,0.2); // Silverman's Faustregel
Die ursprüngliche Idee war, keine externen Tools zu verwenden, d. h. es wurde davon ausgegangen, dass alles nur mit MQL5-Tools implementiert werden sollte.
Das ist die Idee ausnahmslos aller Erfinder von Fahrrädern.
Schauen Sie sich an, was die entsprechenden Pakete in dieser Hinsicht haben, und vergleichen Sie es mit dem, was Sie zur Verfügung gestellt haben - eine verschwindend geringe Menge dessen, was bei der Anwendung von Statistik und Ökonometrie im Handel benötigt wird.
Lieber Alex,
Es ist leicht für dich, aus der Höhe deines Fluges heraus zu argumentieren. Aber denk doch einmal über Folgendes nach:
Diese Ressource heißt"www.mql5.com - Automated Trading and Testing of Trading Strategies". Wie Sie sehen können, heißt die Seite mql5, nicht EViews oder gar MQ oder MT5. Es ist daher leicht anzunehmen, dass sich diese Website in erster Linie auf die Popularisierung, das Debugging und die Entwicklung der Programmiersprache MQL5 konzentriert. Dies wird durch das Vorhandensein der Servicedesk und die Platzierung von MQL5-Referenzinformationen auf der Site bestätigt.
Wenn diese Website zum Beispiel "eine Sammlung von Handelsstrategien" hieße und nicht zu MQ gehören würde . In diesem Fall würde man erwarten, dass Veröffentlichungen, die Lösungen in Exel, R, EVievs, Gauss, Stata und so weiter beschreiben , auf einer solchen Seite erscheinen.
Hätte ich diesen Artikel auf der EViews-Seite veröffentlicht, hätte ich vielleicht versucht, den Kern Ihres Vorwurfs zu verstehen. Aber Sie und ich sind im Moment nicht auf EViews.
Diese Seite wird von Menschen mit sehr unterschiedlichem Hintergrund besucht. Es sind Menschen unterschiedlichen Alters, mit unterschiedlichem Bildungshintergrund und unterschiedlichen Fachgebieten. Ich denke, die meisten von ihnen haben wenig oder gar keine Erfahrung mit ökonometrischen Paketen. Sind Sie der Meinung, dass all diese Leute von dieser Website verbannt werden sollten, z. B. indem man sie zuerst EViews lernen lässt?
Da Sie selbst einen Artikel veröffentlicht haben, sollten Sie mit dem Verfahren zur Veröffentlichung von Artikeln auf dieser Website vertraut sein. Es ist nicht möglich, einen Artikel im Selbstverlag zu veröffentlichen. Sie können nur einen Artikel zur Prüfung einreichen. Die Verwaltung der Website selbst wählt Artikel aus, die in ihr allgemeines Konzept passen. Und in einigen Fällen gibt die Verwaltung selbst Artikel zu Themen in Auftrag, die für sie von Interesse sind. Wie ich bereits sagte, hat die Verwaltung ein allgemeines Konzept und Statistiken über die Anzahl der Anfragen für diese oder jene Veröffentlichung. In dieser Situation halte ich es für nicht ganz richtig, mich mit Behauptungen über das Thema des Artikels anzusprechen. Vielleicht sollten Sie diese Fragen mit Vertretern von MQ besprechen ?
Es gibt auf dieser Website veröffentlichte Artikel, die für mich nicht interessant sind. Ich betone, keine schlechten Artikel, sondern einfach uninteressant für mich. Ich lese sie normalerweise nicht und schreibe auch keine Kommentare dazu. Vielleicht sollten Sie für sich selbst ein ähnliches Verhalten wählen? Obwohl ich es nicht wage, Ratschläge zu erteilen, tun Sie, was Ihnen lieber ist.
Lieber Alex,
Es ist leicht für dich, aus der Höhe deines Fluges heraus zu argumentieren. Aber denk doch mal kurz über Folgendes nach:
Diese Ressource heißt"www.mql5.com - Automated Trading and Testing of Trading Strategies". Wie Sie sehen können, heißt die Seite mql5, nicht EViews oder gar MQ oder MT5. Es ist daher leicht anzunehmen, dass sich diese Website in erster Linie auf die Popularisierung, das Debugging und die Entwicklung der Programmiersprache MQL5 konzentriert. Dies wird durch das Vorhandensein der Servicedesk und die Platzierung von MQL5-Referenzinformationen auf der Site bestätigt.
Wenn diese Website zum Beispiel "eine Sammlung von Handelsstrategien" hieße und nicht zu MQ gehören würde . In diesem Fall würde man erwarten, dass Veröffentlichungen, die Lösungen in Exel, R, EVievs, Gauss, Stata und so weiter beschreiben , auf einer solchen Seite erscheinen.
Hätte ich diesen Artikel auf der EViews-Seite veröffentlicht, hätte ich vielleicht versucht, den Kern Ihres Vorwurfs zu verstehen. Aber Sie und ich sind im Moment nicht auf EViews.
Diese Seite wird von Menschen mit sehr unterschiedlichem Hintergrund besucht. Es sind Menschen unterschiedlichen Alters, mit unterschiedlichem Bildungshintergrund und unterschiedlichen Fachgebieten. Ich denke, die meisten von ihnen haben wenig oder gar keine Erfahrung mit ökonometrischen Paketen. Sind Sie der Meinung, dass all diese Leute von dieser Website verbannt werden sollten, z. B. indem man sie zuerst EViews lernen lässt?
Da Sie selbst einen Artikel veröffentlicht haben, sollten Sie mit dem Verfahren zur Veröffentlichung von Artikeln auf dieser Website vertraut sein. Es ist nicht möglich, einen Artikel im Selbstverlag zu veröffentlichen. Sie können nur einen Artikel zur Prüfung einreichen. Die Verwaltung der Website selbst wählt Artikel aus, die in ihr allgemeines Konzept passen. Und in einigen Fällen gibt die Verwaltung selbst Artikel zu Themen in Auftrag, die für sie von Interesse sind. Wie ich bereits sagte, hat die Verwaltung ein allgemeines Konzept und Statistiken über die Anzahl der Anfragen für diese oder jene Veröffentlichung. In dieser Situation halte ich es für nicht ganz richtig, mich mit Behauptungen über das Thema des Artikels anzusprechen. Vielleicht sollten Sie diese Fragen mit Vertretern von MQ besprechen ?
Es gibt auf dieser Website veröffentlichte Artikel, die für mich nicht interessant sind. Ich betone, keine schlechten Artikel, sondern einfach uninteressant für mich. Ich lese sie normalerweise nicht und schreibe auch keine Kommentare dazu. Vielleicht sollten Sie für sich selbst ein ähnliches Verhalten wählen? Auch wenn ich es nicht wage, Ratschläge zu erteilen, tun Sie, was Sie für richtig halten.
Ich kann Ihre Antwort nicht akzeptieren, da sie überhaupt nicht auf den Kern meines Beitrags eingeht. Ich werde versuchen, meinen Standpunkt zu erklären.
1. Metaquotes hat überhaupt nichts damit zu tun - sie haben ein sehr anständiges Tool zur Verfügung gestellt und tun es auch.
2. Mir ist nicht bekannt, dass es irgendwelche Einschränkungen bei den Themen der Artikel gibt. Natürlich innerhalb der Grenzen des Handels. Diese Seite hat einen Abschnitt "Statistik", d.h. sie verstehen das Thema der Seite viel weiter als Sie, in voller Übereinstimmung mit dem Inhalt und den Problemen des Handels. Lassen Sie uns nicht auf Metaquotes verweisen und zum Inhalt übergehen.
3. In meinem Beitrag geht es nicht darum, WAS man entwickelt, sondern WIE man entwickelt. Das ist für mich das Wesentliche im Zusammenhang mit Ihrem Artikel. Ich habe nicht für EViews geworben, von dem ich eine schlechte Meinung habe - es ist gut für Demonstrations- und Schulungszwecke, aber ich glaube nicht, dass man damit handeln kann. Ich habe auf Pakete verwiesen, um die Breite des Problems zu demonstrieren.
4. Ich beschäftige mich schon lange mit der Programmierung. Vor 40 Jahren erschienen die ersten Programmbibliotheken und sofort, vor 40 Jahren, wurden Amateure kritisiert, die ein Programm aus einem bestehenden Paket umschrieben. Sie sind nicht der Erste. Aber diese Seite ist voll von Amateuren, die gerne wieder ein Fahrrad bauen - daher meine hypertrophe Reaktion.
5. Die Frage der nuklearen Bewertung ist ein wiedergekautes Thema. Und wenn Sie die Bibliothek von jemand anderem nehmen würden, hätten Sie die Möglichkeit, sich über die technischen Schwierigkeiten, die Sie in Ihrer Arbeit gelöst haben, zu erheben und vielleicht eine Lösung für die von Praktiker alsu aufgeworfenen Fragen anzubieten, oder sich daran zu erinnern, dass die visuelle Bewertung von Verteilungen eine sehr wichtige Rolle bei ihrer formalen Bewertung spielt, oder sich funktional zu erweitern, usw. - In jedem Fall wären Sie einen Schritt weiter.
Ich hatte nicht die Absicht, Ihnen gegenüber irgendetwas Beleidigendes zu äußern. Ihr Artikel und Ihre Entwicklung werden respektiert, aber ich kann mit dem methodischen Schwerpunkt der Technik zur Umsetzung Ihrer Ideen nicht einverstanden sein.
Mein Beitrag zu Ihrem Artikel ist von der Hoffnung bestimmt, dass jemand das Metaquotes-Terminal systematisch mit Mitteln der Statistik und Ökonometrie ergänzt. Ich verweise Sie an solche Leute.
Äußerst interessant. Sehr interessant.
Nehmen Sie Anfragen an?
Nicht nur Open-Source-Code, sondern auch statistikorientierter Code ist erwünscht. Bitte achten Sie auf R.
Äußerst interessant. Sehr interessant.
Nehmen Sie Anfragen an?
Nicht nur Open-Source-Code, sondern auch statistikorientierter Code ist erwünscht. Bitte achten Sie auf R.
Anfragen werden hier angenommen: https://www.mql5.com/ru/forum/6505. Schreiben Sie, was Sie wollen. :)
- www.mql5.com
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Schätzung der Kerndichte einer unbekannten Wahrscheinlichkeitsverteilung :
Die aufgeführten Beispiele veranschaulichen den Umstand, dass ein und dieselbe Erscheinung auf unterschiedliche Weise dargestellt werden kann. Was zweifelsohne unser mathematisches Arsenal bereichert, mitunter jedoch bei der Erörterung mit diesem Thema verbundener Fragen auch zu Verwirrung führen kann.
Obwohl bei der Kerndichteschätzung dieselben Prinzipien zur Anwendung kommen, die wir bereits von der Kernglättung kennen, weist ihr Algorithmus gewisse Besonderheiten auf.
Wir wenden uns dem Ausdruck zu, der das Vorgehen bei der Dichteschätzung in einem Punkt bestimmt.
mit
Autor: Victor