ZigZags Schäferhunde - Seite 14
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Ach du meine Güte. Ich hätte nicht gedacht, dass es so kommen würde.))
Ach du meine Güte. Ich hätte nicht gedacht, dass es so kommen würde)))
Nein, ich glaube nicht an diese Indikatoren.
Sie lügen.
Glauben Sie den Indikatoren nicht. Vertrauen Sie mir.
Nein. Ich traue diesen Indikatoren nicht.
Sie lügen.
Glauben Sie den Indikatoren nicht. Vertrauen Sie mir.
Das ist nicht das, was Müller gesagt hat: Man kann niemandem trauen... Ich schon.)
So hat es Müller nicht ausgedrückt: Man kann niemandem trauen... Ich schon.)
Sie haben es geschafft, mich heute zum elften Mal zum Lachen zu bringen.)) Zehnmal beim Lesen des nächsten Threads.
Aber man kann mir durchaus vertrauen. Ich bin nicht Mueller))
Dies ist das Ergebnis der Bestimmung der Differenz zwischen den Extremen in Abhängigkeit von der Änderung des Schwellenwerts für Kagis ZZ. Abbildung b) - kumulative Kurve.
Dasselbe gilt für Renkos ZZ.
Mir fällt ein interessantes Merkmal auf: die Chi-Quadrat-Verteilung:
Sehen Sie, bei k=1 gibt es eine Ähnlichkeit mit Kagis ZZ, bei k=2 einen Exponenten, genau wie in Renkos ZZ-Diagramm.
Die Chi-Quadrat-Verteilung tendiert mit zunehmendem k zur Normalverteilung.
Nun, ich weiß nicht...
Die Funktion ist interessant, aber wie kann sie genutzt werden? Es ist schwer, etwas vorzuschlagen, da ich weder Kagi noch Renko vom Wort "überhaupt" her gut kenne.
Aber ich werde es probieren.
1. Man muss den Wunsch nach einer Normalverteilung aufgeben und jahrhundertelang suchen, um sie zu finden. Die Arbeit mit den bereits gefundenen Mustern ist bereits eine sehr, sehr große Sache.
2.https://en.wikipedia.org/wiki/Generalized_normal_distribution
3. Einfach ausgedrückt ist xy-quadratisch mit k=1 die Summe der Quadrate normalverteilter NAs, xy-quadratisch mit k=2 ist die Summe der NAs mit Laplace-Verteilung
4. Ich habe mich für den Fall k=2 interessiert, weil Studien zeigen, dass der Markt von der Laplace-Verteilung dominiert wird (doppelt geometrisch, um genau zu sein)
5. Es ist hier nicht klar - was zählt bei diesen Renko's? Die Summe der Differenzen (Hoch-Tief)?
6. Wenn ja - dann ist die Differenz (High-Low) in Renko SV, die zur Laplace-Verteilung gehört - dies sollte experimentell bestätigt werden.
7. Dann bildet die Summe der Differenzen (High-Low) im gleitenden Fenster (für ein bestimmtes Probenvolumen) ein xy-Quadrat mit k=2 mit bekannter Quantilsfunktion
https://keisan.casio.com/exec/system/1180573197
8. Wir warten auf den Ausgang (High-Low) im gleitenden Fenster jenseits der Grenzen eines Konfidenzintervalls für ein bestimmtes Quantil und steigen in den Handel ein.
Nun, dies ist nur eine grobe Skizze des Algorithmus, nur um das Thema zu entwickeln und nichts weiter :)))
5. Hier ist es nicht klar - was zählt bei diesen Renko's? Die Summe der Differenzen (Hoch-Tief)?
7. Dann bildet die Summe der Differenzen (High-Low) im Schiebefenster (für einen bestimmten Stichprobenumfang) ein xy-Quadrat mit k=2 mit bekannter Quantilsfunktion
https://keisan.casio.com/exec/system/1180573197
8. Warten auf den Ausstieg (High-Low) im gleitenden Fenster jenseits der Grenzen des Konfidenzintervalls für ein bestimmtes Quantil und Einstieg in den Handel.
5. Renko betrachtet den Durchbruch durch den von "Renko brick" festgelegten Bereich auf dem Wert von 1 "brick", außerdem sollte der Durchbruch auf dem Wert von "brick" sein, d.h. "brick" 10 Punkte, um einen neuen Renko brick zu zeichnen, sollte der Preis über dem bereits gebildeten Renko bar 10п+1п (oder unter auf 10п+1п) passieren und dann wird ein neuer "brick" gezeichnet. D.h. im Wesentlichen wird der Preis ohne Zeit durch den Wert des "Renko-Bausteins" diskretisiert. Renko entfernt die Rauschkomponenten des Preises, aber wie bei jedem Filter gibt es eine Verzögerung, um einen neuen Renko-Balken zu zeichnen, sollte der Preis 2 Bereiche = 2 Höhen des Renko-Steins durchlaufen
7,8 ist ein ATR-Indikator, was Sie schreiben, ist in der Regel eine Volatilität Aufschlüsselung genannt, aber es gibt ein ewiges Problem - der Zeitraum der ATR, wenn der Zeitraum klein ist, wird es Lärm, wenn der Zeitraum lang ist, wird es lag
Hier
Forum zum Thema Handel, automatisierte Handelssysteme und Testen von Handelsstrategien
ZigZags Schäferhunde
Novaja, 2018.08.26 23:22
Dies ist das Ergebnis der Bestimmung der Differenz zwischen den Extremen in Abhängigkeit von der Änderung des Schwellenwerts für ZZ Kagi. Abbildung b) - kumulative Kurve.
Dasselbe gilt für Renko ZZ.
Mir fällt ein interessantes Merkmal auf: die Chi-Quadrat-Verteilung:
Sehen Sie, bei k=1 gibt es eine Ähnlichkeit mit Kagis ZZ, bei k=2 ist der Exponent genau derselbe wie im ZZ-Diagramm von Renko.
Die Chi-Quadrat-Verteilung tendiert mit zunehmendem k zur Normalverteilung.
Novaja spricht von einigen Unterschieden zwischen den Extremen... Über den Spread (High-Low) oder so? Ich kann es nicht verstehen... Es ist zu trocken und prägnant geschrieben...
Aber es sieht aus wie ein xy-Quadrat - deshalb bin ich daran interessiert. Klare Muster sind sehr selten zu finden.
Ich weiß es nicht...
Die Funktion ist interessant, aber wie kann man sie nutzen? Es ist schwer, irgendetwas vorzuschlagen, da ich weder in Kagi noch in Renko vom Wort "überhaupt" her gut bin.
Aber ich werde es probieren.
1. Man muss den Wunsch nach einer Normalverteilung aufgeben und jahrhundertelang suchen, um sie zu finden. Die Arbeit mit den bereits gefundenen Mustern ist bereits eine sehr, sehr große Sache.
2.https://en.wikipedia.org/wiki/Generalized_normal_distribution
3. Einfach ausgedrückt ist xy-quadratisch mit k=1 die Summe der Quadrate normalverteilter NAs, xy-quadratisch mit k=2 ist die Summe der NAs mit Laplace-Verteilung
4. Ich habe mich für den Fall k=2 interessiert, weil Studien zeigen, dass der Markt von der Laplace-Verteilung dominiert wird (doppelt geometrisch, um genau zu sein)
5. Es ist hier nicht klar - was zählt bei diesen Renko's? Die Summe der Differenzen (Hoch-Tief)?
6. Wenn ja - dann ist die Differenz (High-Low) in Renko SV, die zur Laplace-Verteilung gehört - dies sollte experimentell bestätigt werden.
7. Dann bildet die Summe der Differenzen (High-Low) im gleitenden Fenster (für ein bestimmtes Probenvolumen) ein xy-Quadrat mit k=2 mit bekannter Quantilsfunktion
https://keisan.casio.com/exec/system/1180573197
8. Wir warten auf den Ausgang (High-Low) im gleitenden Fenster jenseits der Grenzen eines Konfidenzintervalls für ein bestimmtes Quantil und steigen in den Handel ein.
Nun, dies ist nur ein grober Algorithmus, nur um das Thema zu entwickeln und nichts weiter :)Cgfcb,j
Vielen Dank, toller Kommentar.
Ein paar Worte zum Aufbau der zz. Kagis Variante.
Blau zeigt das Tick-Chart, die Schwelle liegt bei 3p. Wenn der Gegensatz größer als 3 Pips ist, wird ein Extremum gezogen, wenn nicht, gehen wir weiter. D.h. Schwankungen können 2,66; 3,66; n Anzahl solcher Schwellenwerte (Segmente) mit gebrochenen Werten enthalten. Bei der Konstruktion des Renko-Typs wird dieser Teilwert verworfen, aber das Prinzip ist dasselbe. D.h. ganze Werte 2,3, usw. Wir sehen also, dass gebrochene Scheitelpunkte bei der Konstruktion nicht berücksichtigt werden. Im Bild unten sehen Sie eine Variante von Renko.
Ich denke, der Unterschied ist jetzt klar. Die Häufigkeit des Auftretens des Verhältnisses der Schwunglänge zum Schwellenwert (Segment von 3p) für Kagi: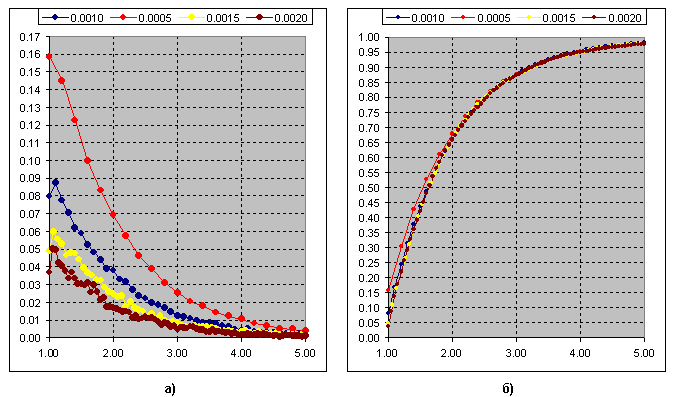
Abb.b) Kumulative Summe der Kurven. Die Chi-Quadrat-Verteilung bei k=1 passt zu dieser Kurve.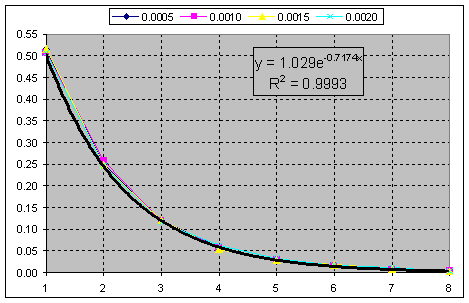
Und dies ist die kumulative Summe der Häufigkeit des Auftretens des Swing Ratio zum Schwellenwert (Segment) für die Renko-Konstruktion. Chi-Quadrat bei k=2.
D.h. wir müssen nur die Nachkommastellen weglassen und erhalten einen reinen Exponenten.
Vielen Dank für den tollen Kommentar.
Ein paar Worte zum Aufbau der zz. Kagis Variante.
Blau zeigt das Tick-Chart, Schwelle - 3p. Wenn der Gegensatz größer als 3 Pips ist, wird ein Extremum gezogen, wenn nicht, gehen wir weiter. D.h. Schwankungen können 2,66; 3,66; n Anzahl solcher Schwellenwerte (Segmente) mit gebrochenen Werten enthalten. Bei der Konstruktion des Renko-Typs wird dieser Teilwert verworfen, aber das Prinzip ist dasselbe. D.h. ganze Werte 2,3, usw. Wir sehen also, dass gebrochene Scheitelpunkte bei der Konstruktion nicht berücksichtigt werden. Im Bild unten sehen Sie eine Variante von Renko.
Ich denke, der Unterschied ist jetzt klar. Die Häufigkeit des Auftretens des Verhältnisses der Schwunglänge zum Schwellenwert (Segment von 3p) für Kagi:
Abb.b) Kumulative Summe der Kurven. Die Chi-Quadrat-Verteilung bei k=1 passt zu dieser Kurve.
Und dies ist die kumulative Summe der Häufigkeit des Auftretens des Swing Ratio zum Schwellenwert (Segment) für die Renko-Konstruktion. Chi-Quadrat bei k=2.
D.h. Sie müssen nur die Nachkommastellen verwerfen, da Sie einen reinen Exponenten erhalten.
Schaukeln... Eh-mah... :)))
GUT. Ich werde mich nicht näher mit der Terminologie befassen. Keine Zeit.
Wir haben den reinsten Exponenten in allen Bereichen.
Die Summe dieser Komponenten wird eine negative Binomialverteilung sein (die Erlang-Verteilung für kontinuierliche NE), wiederum, wie ich betonen möchte, mit der berühmten Dispersion. Der Grenzwert ist die gesuchte Normalverteilung.