Hearst-Index - Seite 20
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Es besteht auch die Möglichkeit, das Segment dauerhaft in zwei Hälften zu unterteilen.
Hm, und die Punkte, für die die Differenz Close[i+1]-Close[i] = 0 und die Standardabweichung 0 ist, werden bei der Konstruktion einer Geraden einfach nicht berücksichtigt?
Es gibt auch die Meinung, dass man zur Berechnung des Hurst-Koeffizienten das sogenannte RANSAC( http://en.wikipedia.org/wiki/RANSAC ) anstelle des üblichen ISC verwenden sollte, weil die Punkte "aus der Gesamtzahl", d.h. die am weitesten von der Gesamtmasse entfernten, den Steigungskoeffizienten der Geraden mit dem üblichen ISC beeinflussen können.
понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи.
Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей.
Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе.
Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(Close[i+1]-Close[i]) = 0 => log(d[i]/d[i-1]) = INF - Ich verstehe nicht, was ich damit anfangen soll. RS = R/S - und wie berechnet man, wenn S = 0 ist, dass auch R = 0 ist? dann wiederum log(R) = INF und wieder verstehe ich nicht, was zu tun ist. Gut. Hier ein einfaches Beispiel: Wie lautet der Koeffizient H
und wenn (Close[i+1]-Close[i]) = const für alle i in einem bestimmten Intervall?
Ich habe keine Ahnung, auf der Grundlage welchen Modells entschieden werden kann, dass einige Erträge aus der Stichprobe herausgenommen werden sollen? -Wenn z.B. mehrere Werte im Bestandsdatenstrom fehlerhaft sind (54,5 statt 14,4)
Funktion RS nimmt als Eingabe ein Array von Close[i]-Close[i-1] und die Anzahl der Elemente des Arrays
1. S[i-1] = Close[i]-Close[i-1] Für alle i von 0 bis N
2. h[i] = log(S[i]/S[i-1])
3. hn = Summe von h[i] h_cp = arith. Hn
4. r = max(h[i] - h_cp) - min( h[i] - h_cp ) s = 1/n * (h[i] - h_cp) RS = r / s
5. Dann stehe ich m-n Punkte mit Wert von log RS(i) und log i für i von n_min bis einige N und MNCs stehen eine gerade Linie
В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива
1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N
2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений.
3. Hn = Сумма h[i] h_cp = ср.ариф. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
Soweit ich weiß, macht es keinen Sinn, den Koeffizienten für 78 Werte zu berechnen - d.h. für einen Tagesbalken? Ich verstehe auch immer noch nicht, was zu tun ist, wenn einige Werte gleich Null sind. Wenn ich zum Beispiel die Preisdifferenz eingebe, ist es klar, dass die Differenz in 5 Minuten kleiner oder gleich 0 sein kann, aber dann wird kein Protokoll erstellt. Ich habe die Idee, den Modulus des Wertes zu nehmen, wenn er negativ ist (d. h. die absolute Differenz), und im Fall von 0 diesen Wert nicht in die Reihe h einzugeben.
Die Testdatei selbst. H~0.72
Ihr Indikator zHursttExponent.mq4 ergibt 0,1647 in Ihrer Testdatei brown72.txt. Worum geht es hier?
Soweit ich verstanden habe, berechnet dieser Indikator den Hurst-Wert für jeden Tick der letzten 2520 Balken und gibt ihn aus. Ist das so?
Was bedeuten dann 4 Bins dieses Indikators und wozu werden sie in einem separaten Fenster benötigt?
Und noch eine Frage.
for(int i=0; i<limit; i++)
{
}
//---- done
Welche Bedeutung hat diese Stelle im Code des Indikators?
Ваш индикатор zHursttExponent.mq4 на вашем же тестовом файле brown72.txt выдает 0.1647. К чему бы это ?
Насколько я понял, этот индикатор считает показатель Херста на каждом тике для последних 2520 баров и выдает значение на печать. Так ?
А что тогда означают 4 буфера этого индикатора и зачем они нужны в отдельном окне ?
И еще один вопрос.
for(int i=0; i<limit; i++)
{
}
//---- done
Какой смысл имеет этот кусок в коде индикатора ?
1. Kann Ihr Ergebnis = 0,1647 nicht wiederholen. Bei mir sieht das so aus (=0,7241):
2) Ja, dieser Indikator berücksichtigt den Hurst-Index bei jedem Tick für die letzten 2520 Balken und druckt den Wert aus und zeichnet r/s-Punkte (weiße Linie), auf denen die Näherungsgerade (rote Linie) gezeichnet wird, deren Steigung der gesuchte Index ist - für die Klarheit, aber für mich - für eine qualitative visuelle Einschätzung der Korrektheit des Algorithmus. All dies gilt, wenn cRSGraphic = true ist, andernfalls berücksichtigt der Indikator den Hurst-Index für die letzten 250 Balken.
3. 4 Puffer sind eine offensichtliche Redundanz, ein Überbleibsel aus der Zeit der Fehlersuche und des Testens.
4. Leere Schleife - das gleiche Problem wie in Punkt 3.
Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин.
Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
Hier ist eine Variante, bei der der Fehler gezählt wird. Leider kann ich nicht finden, wo ich die C-Quelle dieses Wunders gestohlen habe, aber sie behauptet, von Feder E. Fractals zu stammen. Für ihn Test H=0,6807 für die gleiche Datei. Es scheint nicht schlecht zu sein.
Für 78 Werte ist es am schwierigsten. Es wird viel darüber nachgedacht, wie man Hurst bei einem halben Hundert Beobachtungen schätzen kann. Selbst wenn man die Berechnungen nicht versteht, erhält man von einem Autor zum anderen sehr unterschiedliche Ergebnisse. Das ist nicht weiter verwunderlich. So viele Algorithmen, wie es Indikatoren gibt :). Oh, und noch ein Problem - in der angehängten Version mit 1000 Beobachtungen und unter Berücksichtigung des Fehlers können wir nichts über den Preis sagen - ist er nun konsistent oder nicht, denn 0.5 liegt genau zwischen dem Fehlerkanal (rote Linien bei cRSGraphic=false).
Die Eingabe sollte entweder die Preisdifferenz oder der Logarithmus des Preisverhältnisses sein.
1. Kann Ihr Ergebnis = 0,1647 nicht wiederholen. Bei mir sieht das so aus (=0,7241):
Sie haben die Datei brown72.txt beigefügt. Ihr Indikator testet jedoch auf die Datei brown72.csv. In Ermangelung anderer Anleitungen habe ich es einfach umbenannt und in den Ordner \experts\files gelegt. Hier ist das Ergebnis:
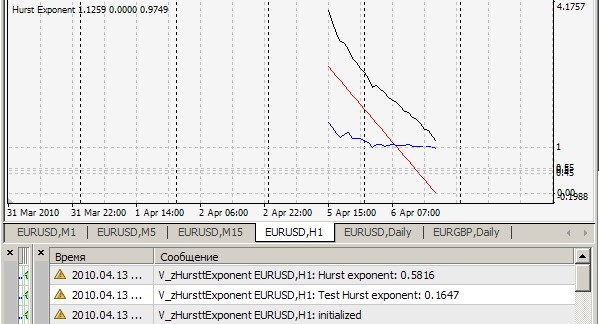
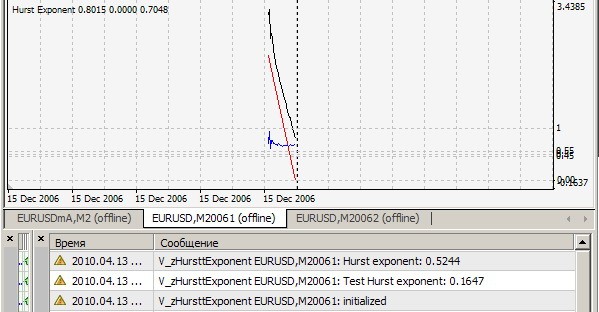
Auf H1:
Über Zecken:
Ihre Datei enthält 1024 Werte. Hier sind die ersten 4 von ihnen:
45.47422
42.55601
46.5188
41.61502