Уже практически все современные персональные компьютеры умеют выполнять несколько задач одновременно – за счет наличия в процессоре нескольких ядер. Их число с каждым годом растет – 2, 3, 4, 6 ядер… Компания Intel недавно продемонстрировала работающий экспериментальный 80-ядерный процессор (да-да, это не опечатка - восемьдесят ядер, - жаль, в...
你说的 "小说/预言家的时期 "是什么意思?)
例如,RSI的周期从5到30,或1条或50条的增量日志。
重要的是要关注超射中的多重共线性,这样模型才不会停滞不前,因为有时它们开始强烈相关。
如果价格随着新的数据开始下跌怎么办?该模型预计它将上升。在这种情况下,我使用的模型开始变得有点沉闷,在交易中坐了很长时间,超额完成任务。
人们也一样愚蠢,当一个趋势期被平坦或反向趋势取代时,就试图坐视不理......希望这是一次浅层的回调。
我遇到过这样一句话:"一个趋势更有可能持续下去而不是结束",但另一方面,它不可能无限期地持续下去。
因此,模型和人一样好)
显然,当大趋势发生变化时,我们需要等待,积累新的数据并重新训练。
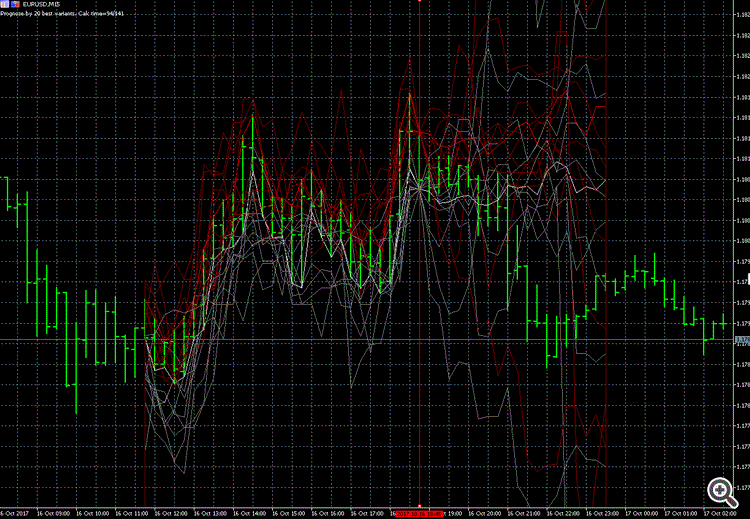
我的印象是,NS根本没有什么可教的,因为市场上几乎没有典型的情况。 要么是受过专门训练的机器人拿着大钱,故意打破模式。
我的模式搜索器无法检测到典型的双顶,因为在去年的20个最类似的案例中,价格刚刚解决了双顶模式,并进一步向上飞去。
预测由粗体红色(高)和白色(低)线表示,灰色和深红色的变体来自历史。
而最相似的变体却不那么相似。
而有时它预测的是一个方向,而价格却向相反的方向发展。
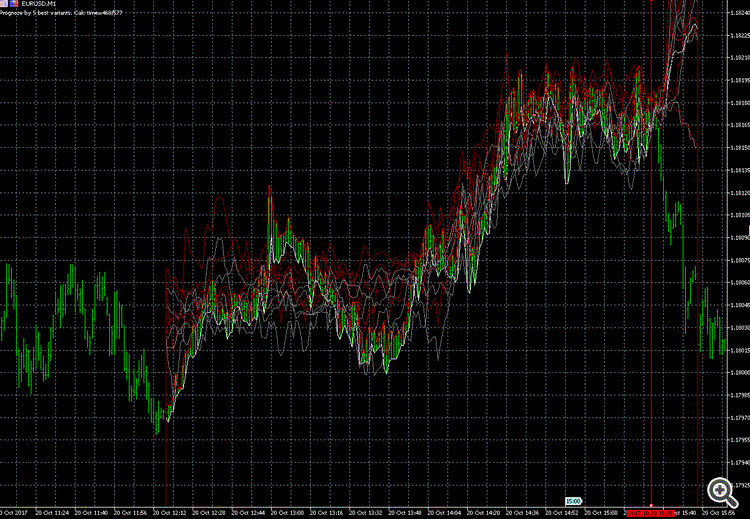
所以它是50/50,就像硬币一样
预测指标的时期
你知道吗,指标只在5%的情况下起作用,当市场随机同步到指标的时期,然后--哦,我的上帝,随机指标在一个平坦的地方起作用!你知道吗?:) ......而且是在每个单位)
我认为人们不应该通过一个有固定期限的指标来看待一个动态的、变化的系统,你同意吗?
我也是这么做的))顺便说一下,在某些条件下,价格更有可能与预测相反,而不是在预测后面。你如何衡量接近程度? 通过相关关系?
而你用什么来衡量接近程度?
只是总结了我要找的模式的每条杠上的差异,以及历史上所有其他的大块头长到该模式的差异。
总的来说,我已经敲定了文章中的代码 https://www.mql5.com/ru/articles/197
你知道,指标只在5%的情况下起作用,当市场随机同步到指标的周期,然后随机指标在平坦的地方起作用!你知道吗?:) ......而且是在每个单位)
我认为我们不能通过一个有固定期限的指标来看待一个动态的、变化的系统,你同意吗?
嗯,有很多指标,而且周期也不一样。我已经有一个系统,有固定周期的指标,根据同样的规则进行预测(也有周期)。
我也是这么做的))顺便说一下,在某些条件下,价格更有可能与预测相反,而不是在预测后面。你如何衡量接近程度? 通过相关关系?
如果在预后方面没有区别,那么为什么要在更复杂的事情上花费数倍的时间来处理简单的结果?
我在想,如果预测是50%左右,那么在MO上浪费时间是否有意义。在马什卡上,我认为同样的情况会发生。
如果预测没有差别,那么为什么要花数倍的时间在结果简单的更复杂的事情上?
我不知道,这是个哲学问题)。
就个人而言,我对清障者没有任何信心。
p.s. 至于你的小东西,你确实看起来不错,你可以用它来做预测,但你需要了解市场的机制,以了解在哪里以及从什么角度看。我不知道,这是个哲学问题)。
就个人而言,我对清障车没有信心。
p.s. 至于你的手艺,你还是会喜欢的,你可以进行预测,但你需要了解市场的机制,以了解从哪里、从什么角度看。计算的时间太长了。每1巴0.1-0.5秒(取决于模板的长度)。它已经优化 了24小时,只通过了1400次。显然,我需要一个星期的时间。(
)而且最初的结果不是很好:2个月内达到50%,缩水30%。
我还有一个想法是如何改进它,如果失败了,我可能会回到mashcats。
向那些为NS解决了回归 问题的人提问。
你用什么作为训练值(然后预测什么)?
有一些变种。
1) 1个输出,包括下一个柱状体的价格增量(对我来说似乎并不有趣,因为一个柱状体的价格增量通常并不重要)
2)10-20条的输出,10-20条的价格增量(似乎很耗费资源和时间,但能提供更好的准确性。)
3) 输出1个沿 "之 "字形的极值的增量价格(例如,在15个条形中会有一个沿 "之 "字形的极值,给出其价格)。
在您看来,哪个方案更好?也许有更好的东西?
如果预测的是未来的几个柱子(第2页和第3页),那么它们表现的概率显然会降低。什么数字才是最佳的?