implements the Hidden Markov Models (HMMs). The HMM is a generative probabilistic model, in which a sequence of observable variables is generated by a sequence of internal hidden states . The hidden states are not observed directly. The transitions between hidden states are assumed to have the form of a (first-order) Markov chain. They can be...
如果有人了解HMM,那么请帮助我解决这个问题,如果这个问题可以解决,那么我将分享圣杯)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
如果有人了解HMM,那么请帮助我解决这个问题,如果这个问题可以解决,那么我将分享圣杯)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
好吧,状态是马尔科夫的,但模型是什么?
这意味着你需要更多的点,至少在平方的窗口上。
如果一个随机序列被输入,除了50/50之外,我们还能谈什么预测?这意味着你需要更多的点,至少在平方的窗口上。
我告诉你,我甚至拿了几千分
, 如果输入的是随机序列,那么除了50/50之外,我们还能谈什么预测?
这有什么区别呢,数据是一样的,模型也是一样的。
我使用软件包中的整个函数来预测新的数据(就像网络上的所有例子一样......),结果很好。
我使用相同的模型来 预测相同的数据 ,但使用滑动窗口,结果是不可接受的。
这就是问题所在--问题是什么?我告诉你,我甚至拿了几千个点
这有什么区别呢,数据是一样的,模型是一样的。
我使用软件包中的整个函数来预测新的数据(就像网络上的所有例子一样......),结果很好。
我用相同的模型 预测相同的数据 ,但用滑动窗口,结果是不同的,不可接受。
这就是真正的问题--问题是什么?我不知道你的模型是什么样的,也不知道你从哪里得到的状态。没有任何包裹,有什么意义?
也许有一个不发出任何随机状态的GCP,这就是为什么它在第一种情况下被预测到。试着改变训练和测试的种子,看看在第一种情况下,不可能预测任何东西,否则我不知道如何帮助,想法不清楚。
根据分类的概率进行拆分。更确切地说,不是通过概率,而是通过分类误差。因为在训练演习中一切都知道了,而且我们不是有概率,而是有确切的估计。
虽然有不同的分离方式,即对杂质的测量(左侧或右侧采样)。
我指的是分类准确率在样本上的分布,而不是现在这样的总量。
不清楚模式是什么,也不清楚你从哪里得到这些国家。没有任何包,从概念上讲有什么意义呢?
也许有一个gcp不给任何随机化,这就是为什么在第一种情况下预测到了。试着为训练和测试改变种子,看看是否在第一种情况下也无法预测,否则我不知道如何帮助这个想法。
这里是文件,有价格和两列预测器 "data1 "和 "data2"。
你用Python或任何你喜欢的方式为这两列("data1 "和 "data2")训练只有两个状态的HMM(在一个没有老师的数据轨道上)。 你根本不碰价格,只是为了可视化而做
然后你拿着维特比算法,想出一个(数据测试)。
我们得到两个状态,它应该看起来像这样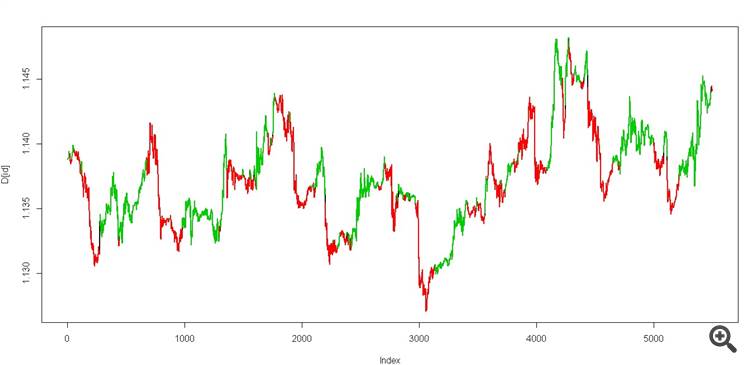
这是一个真正的圣杯))。
然后尝试用相同的数据在滑动窗口中计算相同的维泰尔比
这里是一个包含价格和两列预测因子 "data1 "和 "data2 "的文件。
你用Python或任何你喜欢的方式,用这两列("data1 "和 "data2")训练只有两个状态的HMM(在一个数据轨道上)。 你根本不碰价格,只是用它来进行可视化。
然后你采取维特比算法和(数据测试) 的方法
我们得到两个状态,它应该看起来像这样
这是一个真正的圣杯)。
然后在同一数据的滑动窗口中尝试同样的维特比计算
森克,我以后再看,我会告诉你的,因为我正在和一个马尔科夫人一起工作。
senk,我稍后会检查一下并告诉你,因为我自己正在处理马尔科夫的问题。
有什么收获吗?
有什么收获吗?
还没有看,今天休息)我有时间会告诉你,我是说在本周晚些时候。
到目前为止,看了这些包。我认为它适合https://hmmlearn.readthedocs.io/en/latest/tutorial.html