"Bilinmeyen Olasılık Yoğunluk Fonksiyonunun Çekirdek Yoğunluk Tahmini" makalesi için tartışma
Yazara. Dağılımın yoğunluğunu değil de dağılım fonksiyonunu, yani yoğunluğun integralini tahmin edersek daha da iyi sonuçlar elde ederiz: ilk olarak, bunu veriler üzerinde oluşturmak daha kolaydır ve her zaman azalmayan ve 0 ile 1 arasında sınırlı olduğundan, kernel, spline, regresyon veya başka bir şey olsun, yumuşatma algoritması seçimine duyarlılık çok daha düşüktür. Mevcut veri miktarına ilişkin gereksinimler de büyüklük sırasına göre azalır.
Yoğunluk, gerekirse sayısal türevlendirme ile kolayca elde edilebilir.
Gerekirse yoğunluk sayısal türevle kolayca elde edilebilir.
Belki de. Bu konuda bir şey söyleyemem. Pdf 'yi cdf üzerinden değerlendirmeyi denemedim bile. Büyük olasılıkla türev kullanmanın cdf kestiriminin doğruluğunda önemli bir artış gerektireceği önyargısı işe yaradı. Ayrıca cdf->pdf yöntemini değerlendiren veya diğer yöntemlerle karşılaştıran herhangi bir yayına da rastlamadım. Linkleri paylaşabilirseniz minnettar olurum.
Orijinal fikir herhangi bir harici araç kullanmamaktı, yani her şeyin yalnızca MQL5 araçları tarafından uygulanması gerektiği varsayılıyordu.
Bu, istisnasız tüm bisiklet mucitlerinin fikridir.
İlgili paketlerin bu konuda sahip olduklarına bakın ve sizin sağladıklarınızla karşılaştırın - ticarette matematiği ve ekonometriyi uygularken gerekenlerin çok küçük bir kısmı.
Olabilir. Bu konuda bir şey söyleyemem. Pdf 'yi cdf aracılığıyla tahmin etmeyi denemedim bile. Büyük olasılıkla, farklılaştırma kullanmanın cdf tahmininin doğruluğunda önemli bir artış gerektireceği önyargısı işe yaradı. Ayrıca cdf->pdf yöntemini değerlendiren veya diğer yöntemlerle karşılaştıran herhangi bir yayına rastlamadım. Linkleri paylaşırsanız minnettar olurum.
Elimde olmadığı için referans veremiyorum. Bunun yerine şu hususları belirteceğim.
Bir pdf'yi doğrudan değerlendirirken, tanımın alanını önceden aralıklara bölmek zorundayız ve iki sorun var: birincisi, alanı kaç aralığa bölmenin daha iyi olacağını bilmiyoruz ve ikincisi, hangi ızgara türünün(tekdüze, ... ?) en iyi olacağını bilmiyoruz. Ve eğer ikinci soruyu insanlar hala bir şekilde, örneğin kantil bölümleme kullanarak çözmeye çalışıyorsa, o zaman birincisi için, bence, hiçbir evrensel yöntem yoktur: benim bildiğim hepsinin, dürtme yöntemini karşılayamadığımızda, otomasyon görevlerinde çok az kullanılmalarını sağlayan sınırlamaları vardır.
Cdf tahmini bu dezavantajlardan yoksundur. Bu durumda, fonksiyonun adımları tam olarak girdi verilerinin düştüğü yere yerleştirilir ve böylece enterpolasyon için bir ızgara seçme sorunu kendiliğinden ortadan kalkar. Izgara oluşturulduktan sonra, aralıkların sayısını seçmek zor değildir: maksimum aralık sayısını (ve konumlarını!!!) zaten biliyoruz, bu nedenle, inceltme yoluyla gerekli herhangi bir doğruluğu ve her seferinde girdi verilerinin yapısına en iyi uyan doğal bir ızgarayı ayarlayabiliriz.
Uygulamada, veri örneklerinin sayısı 100'ü geçmediğinde ampirik dağılımların yerel modlarını aramak için bu tekniği kullandım ve çok düzgün sonuçlar elde ettim ve görsel olarak aramanın doğruluğu oldukça kalitatif olarak tanımlanıyor, en az 2-4 ana mod pratikte sapma olmadan bulunuyor. Ancak ben farklı bir yumuşatma algoritması kullanıyorum, çekirdek olanları birkaç nedenden dolayı sevmiyorum.
Hepsi tamamen adil. Ancak bana göründüğü kadarıyla, görünüşe göre dikkat etmediğiniz bir nokta dışında.
Kernel smoothother için iyi bilinen bir ifade "Kernel smooth" dur.
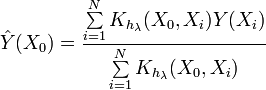
Pdf tahmini için bu tür yumuşatmaya dayalı bir yöntem şu şekilde görünebilir (basitleştirilmiş):
- Girdi dizisini aralıklara böleriz (kümeleme, Binning)
- Ortaya çıkan histogramı yumuşatın.
Kernel yumuşatmayı sevmiyorsanız, örneğin p-spline kullanabilirsiniz. (Muhtemelen hemen p-spline seçmek daha iyidir).
Pdf tahminine bu yaklaşımla, söylediğiniz her şeyin kesinlikle doğru olduğu ortaya çıkıyor. Ancak bu durumda bile büyük uzunluktaki (>1000000) diziler için bu tahmin yöntemi mükemmel sonuçlar verir. Girdi dizisinin uzunluğu azaldıkça, bahsettiğiniz tüm bu cazibeler giderek daha güçlü bir şekilde ortaya çıkmaya başlar.
Şimdi Kernel yoğunluk tahmini (KDE) ifadesine bakalım
![]()
Bu ifade daha önce verilen ifadeden farklıdır. Gördüğünüz gibi, bu ifade doğrudan belirli bir noktadaki olasılık yoğunluk fonksiyonunun değerini belirler. Ve bu durumda önemli olan, aralıklara bölme yoktur. Giriş dizisinin değerleri doğrudan kullanılır.
En azından ben KDE'de durumu bu şekilde görüyorum. Makalede verilen pdf tahmin algoritması ilk bakışta 20-30 eleman uzunluğundaki dizilerle oldukça iyi başa çıkıyor. Bazen yumuşatma derecesini azaltmak isteyebilirsiniz. Kodda değiştirerek bunu kolayca yapabilirsiniz
h=0.9*a/MathPow(N,0.2); // Silverman'ın temel kuralıtarafından
h=0.7*a/MathPow(N,0.2); // Silverman'ın temel kuralı
Orijinal fikir herhangi bir harici araç kullanmamaktı, yani her şeyin yalnızca MQL5 araçları tarafından uygulanması gerektiği varsayılıyordu.
Bu, istisnasız tüm bisiklet mucitlerinin fikridir.
İlgili paketlerin bu konuda sahip olduklarına bakın ve sizin sağladıklarınızla karşılaştırın - ticarette matematiği ve ekonometriyi uygularken gerekenlerin çok küçük bir kısmı.
Sevgili Alex,
Uçuşunuzun yüksekliğinden yola çıkarak mantık yürütmek sizin için kolay. Ancak aşağıdakiler hakkında bir saniye düşünün:
Bu kaynağın adı"www.mql5.com - Otomatik Ticaret ve Ticaret Stratejilerinin Test Edilmesi". Gördüğünüz gibi , sitenin adı EViews veya hatta MQ veya MT5 değil, mql5. Bu nedenle, bu sitenin öncelikle MQL5 programlama dilinin yaygınlaştırılması, hata ayıklama ve geliştirilmesine odaklandığını varsaymak kolaydır. Bu, servicedesk'in varlığı ve MQL5 referans bilgilerinin siteye yerleştirilmesi ile doğrulanmaktadır.
Bu sitenin adı örneğin "ticaret stratejileri koleksiyonu" olsaydı ve MQ 'ya ait olmasaydı . Bu durumda, Exel, R, EVievs, Gauss, Stata ve benzerlerindeki çözümleri açıklayan yayınların böyle bir sitede yer alması beklenirdi.
Bu yazıyı EViews sitesinde yayınlamış olsaydım, siteminizin özünü anlamaya çalışabilirdim. Ama siz ve ben şu anda EViews'de değiliz.
Bu site çok farklı geçmişlere sahip insanlar tarafından ziyaret ediliyor. Farklı yaşlarda, farklı eğitim geçmişlerine ve farklı uzmanlık alanlarına sahip insanlar. Sanırım çoğunun ekonometrik paketlerle ilgili deneyimi ya çok az ya da hiç yok. Sizce tüm bu insanlar bu siteden uzaklaştırılmalı mı, mesela önce EViews'i öğrensinler mi?
Kendi makalenizi yayınladığınıza göre, bu sitede makale yayınlama prosedürünü biliyor olmalısınız. Herhangi bir makaleyi kendi kendinize yayınlamanız mümkün değildir. Sadece değerlendirilmek üzere bir makale gönderebilirsiniz. Site yönetimi, genel konseptlerine uygun makaleleri kendisi seçer. Ve bazı durumlarda, yönetimin kendisi ilgilendikleri konularda makaleler sipariş eder. Daha önce de söylediğim gibi, yönetimin genel bir konsepti ve şu veya bu yayın için taleplerin sayısına ilişkin istatistikleri var. Bu durumda, makalenin konusuyla ilgili iddialarla bana hitap etmenin pek doğru olmadığını düşünüyorum. Belki de bu konuları MQ temsilcileri ile görüşmelisiniz ?
Bu sitede benim ilgimi çekmeyen yayınlanmış makaleler var. Altını çiziyorum, kötü makaleler değil, sadece benim için ilginç değil. Genelde onları okumam ya da haklarında yorum yazmam. Belki siz de kendiniz için benzer bir davranış biçimi seçmelisiniz? Tavsiye vermeye cesaret edemesem de, kendinizi nasıl daha rahat hissediyorsanız öyle yapın.
Sevgili Alex,
Uçuşunuzun yüksekliğinden yola çıkarak mantık yürütmek sizin için kolay. Ancak bir saniye için aşağıdakileri düşünün:
Bu kaynağın adı"www.mql5.com - Otomatik Ticaret ve Ticaret Stratejilerinin Test Edilmesi". Gördüğünüz gibi , sitenin adı EViews veya hatta MQ veya MT5 değil, mql5. Bu nedenle, bu sitenin öncelikle MQL5 programlama dilinin yaygınlaştırılması, hata ayıklama ve geliştirilmesine odaklandığını varsaymak kolaydır. Bu, servicedesk'in varlığı ve MQL5 referans bilgilerinin siteye yerleştirilmesi ile doğrulanmaktadır.
Bu sitenin adı örneğin "ticaret stratejileri koleksiyonu" olsaydı ve MQ 'ya ait olmasaydı . Bu durumda, Exel, R, EVievs, Gauss, Stata ve benzerlerindeki çözümleri açıklayan yayınların böyle bir sitede yer alması beklenirdi.
Bu yazıyı EViews sitesinde yayınlamış olsaydım, siteminizin özünü anlamaya çalışabilirdim. Ama siz ve ben şu anda EViews'de değiliz.
Bu site çok farklı geçmişlere sahip insanlar tarafından ziyaret ediliyor. Farklı yaşlarda, farklı eğitim geçmişlerine ve farklı uzmanlık alanlarına sahip insanlar. Sanırım çoğunun ekonometrik paketlerle ilgili deneyimi ya çok az ya da hiç yok. Sizce tüm bu insanlar bu siteden uzaklaştırılmalı mı, mesela önce EViews'i öğrensinler mi?
Kendi makalenizi yayınladığınıza göre, bu sitede makale yayınlama prosedürünü biliyor olmalısınız. Herhangi bir makaleyi kendi kendinize yayınlamanız mümkün değildir. Sadece değerlendirilmek üzere bir makale gönderebilirsiniz. Site yönetimi, genel konseptlerine uygun makaleleri kendisi seçer. Ve bazı durumlarda, yönetimin kendisi ilgilendikleri konularda makaleler sipariş eder. Daha önce de söylediğim gibi, yönetimin genel bir konsepti ve şu veya bu yayın için taleplerin sayısına ilişkin istatistikleri var. Bu durumda, makalenin konusuyla ilgili iddialarla bana hitap etmenin pek doğru olmadığını düşünüyorum. Belki de bu konuları MQ temsilcileri ile görüşmelisiniz ?
Bu sitede benim ilgimi çekmeyen yayınlanmış makaleler var. Altını çiziyorum, kötü makaleler değil, sadece benim için ilginç değil. Genelde onları okumam ya da haklarında yorum yazmam. Belki siz de kendiniz için benzer bir davranış biçimi seçmelisiniz? Tavsiye vermeye cesaret edemesem de, kendinizi nasıl daha rahat hissediyorsanız öyle yapın.
Cevabınızı kabul edemem, çünkü yazımın özüne hiç uymuyor. Kendi bakış açımı açıklamaya çalışacağım.
1. Metaquotes'un bununla hiçbir ilgisi yok - çok iyi bir araç sağladılar ve bunu yapıyorlar.
2. Makalelerin konularıyla ilgili herhangi bir kısıtlamanın farkında değilim. Tabii ki, ticaret sınırları dahilinde. Bu sitede "İstatistikler" bölümü var, yani sitenin konusunu sizden çok daha geniş bir şekilde, ticaretin içeriğine ve sorunlarına tam olarak uygun olarak anlıyorlar. Metaquotes'a atıfta bulunmayalım ve öze geçelim.
3. Benim yazım NE geliştirileceği ile ilgili değil, NASIL geliştirileceği ile ilgili. Benim için, makalenizle bağlantılı olarak temel olan budur. EViews için kampanya yürütmüyordum, ki bu konuda düşük bir görüşe sahibim - gösterim ve eğitim amaçları için iyidir, ancak onunla ticaret yapabileceğinizi sanmıyorum. Bağlantım, sorunun genişliğini göstermek için paketlere yöneliktir.
4. Uzun zamandır programlama ile uğraşıyorum. 40 yıl önce ilk program kütüphaneleri ortaya çıktı ve hemen, 40 yıl önce, mevcut bir paketten bazı programları yeniden yazan amatörler eleştirildi. Siz ilk değilsiniz. Ama bu site yeniden bisiklet yapmayı seven amatörlerle dolu - dolayısıyla benim hipertrofik tepkim.
5. Nükleer değerlendirme konusu çiğnenmiş ve çiğnendikçe çiğnenmiş bir konudur. Başka birinin kütüphanesini alsaydınız, makalenizde çözdüğünüz teknik zorlukların üzerine çıkma ve belki de uygulayıcı alsu tarafından gündeme getirilen sorunlara bir çözüm sunma veya dağılımların görsel değerlendirmesinin resmi değerlendirmelerinde çok önemli bir rol oynadığını hatırlama veya işlevsel olarak genişleme vb. fırsatınız olurdu. - Her iki durumda da bir basamak daha yükselmiş olursunuz.
Size karşı kırıcı bir şey ifade etmek istemedim. Makalenize ve gelişiminize saygı duyuyorum, ancak fikirlerinizi uygulama tekniğinin metodolojik odağına katılamıyorum.
Makalenizle ilgili yazım, birilerinin Metaquot terminalini istatistik ve ekonometri araçlarıyla sistematik olarak tamamlayacağı umuduyla yazılmıştır. Sizi bu tür insanlara yönlendiriyorum.
Son derece ilginç. Çok ilginç.
İstekleri kabul ediyor musunuz?
Sadece açık kaynak kodu değil, istatistik odaklı kod da arzu edilir. Lütfen R'ye dikkat edin.
Son derece ilginç. Çok ilginç.
İstekleri kabul ediyor musunuz?
Sadece açık kaynak kodu değil, istatistik odaklı kod da arzu edilir. Lütfen R'ye dikkat edin.
İstekler buradan kabul edilir: https://www.mql5.com/ru/forum/6505. Ne isterseniz yazın. :)
- www.mql5.com
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Yeni makale Bilinmeyen Olasılık Yoğunluk Fonksiyonunun Çekirdek Yoğunluk Tahmini yayınlandı:
Makale, bilinmeyen olasılık yoğunluk fonksiyonunun çekirdek yoğunluğunu tahmin etmeye olanak tanıyan bir programın oluşturulması ile ilgilidir. Görevin yürütülmesi için Çekirdek Yoğunluk Tahmin yöntemi seçilmiştir. Makale, yöntem yazılımı uygulamasının kaynak kodlarını, kullanım örneklerini ve çizimlerini içermektedir.
Şek. 1'de, normal dağılım yasasına ve çeşitli h aralığı değerlerine sahip dizi için yoğunluk tahmini grafikleri gösterilmiştir.
Tahminler, yukarıda açıklanan CDens sınıfı kullanılarak yapılır. Grafikler HTML sayfaları şeklinde oluşturulmuştur. Bu tür grafikleri oluşturma yöntemi makalenin sonunda sunulacaktır. Grafiklerin ve diyagramların HTML biçiminde oluşturulması [9]'da bulunabilir.
Şek. 1. Çeşitli h aralığı değerleri için yoğunluk tahmini
Şek. 1'de ayrıca üç yoğunluk tahminiyle birlikte gerçek normal dağılım yoğunluk eğrisi (Gauss dağılımı) gösterilmiştir. Bu durumda, en uygun tahmin sonucunun h=0,22 ile elde edildiği rahatlıkla görülebilir. Diğer iki durumda, kesin "fazla yumuşama" ve "az yumuşama" gözlemleyebiliriz.
Yazar: Victor