Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 1180
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
А что тут не понятного, мост нужен для сквозной автоматизации работы с данными и моделями непосредственно из советника, включая создание, настройку, обучение и т.д.,
Понял, т.е. это в первую очередь возможность создания своего интерфейса по работе с библиотекой МО, правильно? Это равносильно тому, что сейчас я планирую делать такой же интерфейс но через активации exe файла и подачи в него команд. В общем, да интересно сделать это через питон, но у меня нет таких знаний, к сожалению.
а то, что CatBoost сбрасывает в файлы, это сериализация конкретно взятой модели, которая м.б. использована только для вычислений.
Можно конечно возиться с этими файлами в редакторе и создать на базе них советник, но он мало чем будет отличаться от обычного советника с жесткой логикой, а если в этом цель, то ИМХО, гораздо проще достигнуть ее через обучение с помощью шаблонов, которое я предлагал. https://www.mql5.com/ru/forum/270216
Если Вы поняли этот код, то быть может подскажите/расскажите, как его перевести в читаемый вид, к примеру дав каждому правило оконченное описание, к примеру как я это делаю для листьев после обработки моделей из R
я просто не могу понять алгоритм шифровки в этом коде - можете сделать его описание/интерпритатор (возможно за вознаграждение)?
а если в этом цель, то ИМХО, гораздо проще достигнуть ее через обучение с помощью шаблонов, которое я предлагал. https://www.mql5.com/ru/forum/270216
Поскольку там все обучается и генерируется автоматом, причем код каждого из деревьев конвертируется в отдельную, логическую функцию, что м.б. легче при анализе и быстрее при исполнении, если доделаете, можем потом сравнить.
Цель не просто в получении модели, а в получении листьев, их оценка, а уже по этим листья генерация новых моделей.
Тему ту я читал-читал и что-то не совсем понял, процесс автоматического построения сетей создан Вами на базе голых индикаторов и разметки, информация передается по шаблону, у меня же происходит постобработка индикаторов, плюс используются некоторые свои индикаторы, которые я не хотел бы светить, а значит получается что метод не доступен, и опять же - листьев из него не достать...
У меня два вопроса
1) Поясните пож. что это значит - связка индикаторов и их вписывание в ATR дневной
2) Почему кетбуст? Вы уверены что он лучше других бустов? или лесов
1. Это моё виденье рынка, т.е. у цены есть план на движение, который определен ATR на начало дня, далее в зависимости от препятствий (уровней сопротивления (уровней принятия/пересмотра торговых решений участниками рынка), которыми являются, в том числе индикаторы), этот план реализуется или нет. Предикторы описывают эти препятствия относительно плана движения. Ну вот примерно так это графически выглядит - сетка по диапазону ATR а внутри разные индикаторы
Скриншоты торговой платформы MetaTrader
Si-9.18, M1, 2018.08.30
АО ''Открытие Брокер'', MetaTrader 5, Real
На память
2. CatBoost - просто мне помогли его настроить. Плюс он явно работает быстрей, чем прежний мой подход по созданию моделей в R и при этом эффективней оказался, есть документация вменяемая, команды через DOS :) В сравнении с другими инструментами, к примеру Deductor Studio он оказался стабильней, и модели получше выходят, плюс последний платный, а тут все бесплатно.
может вам будет интересно, наткнулся
я хочу замутить систему на оптимизации деревьев, точнее через построения деревьев через оптимизатор.. интересная тема, но даже хз с чего начать :))
https://explained.ai/
Спасибо за заботу!
Языковой барьер делает чтение мучительным, а переводчики текст или тупым или смешным... увы.
переводите по 1 слову, через гугл переводчик плагин для chrome.
я в хроме пользуюсь плагином ImTranslator , норм работает, когда сразу абзац перевести, когда слов - выделил и правой мышей контекстное меню кликаешь
в гугле не надо кликать
А что за плагин? У меня в Хроме это раньше работало, потом перестало, и не знаю как настроить, чтобы было.
Понял, т.е. это в первую очередь возможность создания своего интерфейса по работе с библиотекой МО, правильно? Это равносильно тому, что сейчас я планирую делать такой же интерфейс но через активации exe файла и подачи в него команд. В общем, да интересно сделать это через питон, но у меня нет таких знаний, к сожалению.
Если Вы поняли этот код, то быть может подскажите/расскажите, как его перевести в читаемый вид, к примеру дав каждому правило оконченное описание, к примеру как я это делаю для листьев после обработки моделей из R
я просто не могу понять алгоритм шифровки в этом коде - можете сделать его описание/интерпритатор (возможно за вознаграждение)?
Цель не просто в получении модели, а в получении листьев, их оценка, а уже по этим листья генерация новых моделей.
Тему ту я читал-читал и что-то не совсем понял, процесс автоматического построения сетей создан Вами на базе голых индикаторов и разметки, информация передается по шаблону, у меня же происходит постобработка индикаторов, плюс используются некоторые свои индикаторы, которые я не хотел бы светить, а значит получается что метод не доступен, и опять же - листьев из него не достать...
Не понимаю зачем м.б. нужна ручная правка расщеплений и листьев решающих деревьев, да у меня автоматом все ветвления конвертируются в логические операторы, но честно говоря не помню, что бы я их сам когда то корректировал.
И вообще стоит ли копать код CatBoost, откуда уверенность.
Вот например, я выставлял выше тест на питоне своей нейросети с обучением по таблице умножения на два, а теперь взял его для проверки деревьев и лесов (DecisionTree, RandomForest, CatBoost)
а вот какой результат вышел - явно видно, что не в пользу CatBoost, как дважды два - ноль пять...:)
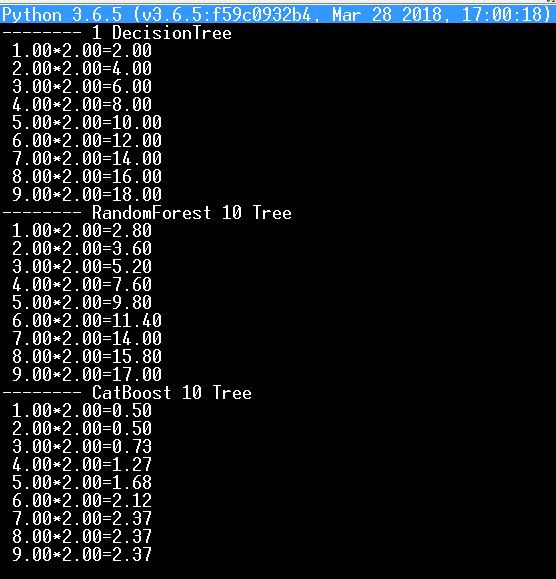
правда, если взять тысячи деревьев, то результаты улучшаются.Не понимаю зачем м.б. нужна ручная правка расщеплений и листьев решающих деревьев, да у меня автоматом все ветвления конвертируются в логические операторы, но чесно говоря не помню, что бы я их сам когда то корректировал.
И вообще стоит ли копать код CatBoost, откуда уверенность.
Вот например, я выставлял выше тест на питоне своей нейросети с обучением по таблице умножения на два, а теперь взял его для проверки деревьев и лесов (DecisionTree, RandomForest, CatBoost)
а вот какой результат вышел - явно видно, что не в пользу CatBoost, как дважды два - ноль пять...:)
да ну нафиг, не может такого быть что бы лес или бустинг не справился с таблицей умножения
да ну нафиг, не может такого быть что бы лес или бустинг не справился с таблицей умножения
гугл тоже не работает? :)
https://chrome.google.com/webstore/detail/google-translate/aapbdbdomjkkjkaonfhkkikfgjllcleb?hl=ru
Переводчик работает. Либо переводит страницу целиком, либо копировать - вставить в переводчик.
А вот слово или абзац - вообще никак.
там настроек всяких слишком дофига, надо много бутылок что бы разобраться.. :) может выборка маленькая т.к. древовидные в основном на большие рассчитаны, подтюнить что-то нужно
конечно, наверняка можно подшаманить, я даже догадываюсь что там процент выборки идет на каждое дерево уменьшенный по умолчанию, но дважды два - это показатель...)