Библиотеки: Библиотека JSON для LLM
Зачем нужен этот цикл?
long FastAtoi(int ptr, int n_len) { long val = 0; int sign = 1; int i = 0; if (buffer[ptr] == '-') { sign = -1; i++; } for (; i <= n_len - 4; i += 4) { val = val * 10000 + (buffer[ptr + i] - '0') * 1000 + (buffer[ptr + i + 1] - '0') * 100 + (buffer[ptr + i + 2] - '0') * 10 + (buffer[ptr + i + 3] - '0'); } for (; i < n_len; i++) val = val * 10 + (buffer[ptr + i] - '0'); return val * sign; }
Это 4-кратное разворачивание цикла на парсере целых чисел ( FastAtoi ). Вместо того чтобы преобразовывать одну цифру за итерацию:
// Naive: 1 digit per iteration, serial dependency chain
for (int i = 0; i < n_len; i++)
val = val * 10 + (buffer[ptr + i] - '0'); Мы обрабатываем сразу четыре цифры:
// Unrolled: 4 digits per iteration, parallel-friendly
for (; i <= n_len - 4; i += 4) {
val = val * 10000 + (buffer[ptr + i] - '0') * 1000 +
(buffer[ptr + i + 1] - '0') * 100 +
(buffer[ptr + i + 2] - '0') * 10 +
(buffer[ptr + i + 3] - '0');
} Почему это важно - Параллелизм уровня инструкций (ILP):
В наивном цикле каждая итерация зависит от результата предыдущей - вы не можете вычислить val * 10, пока не завершится предыдущая val * 10 + digit. Это создает последовательную цепочку зависимостей, которая тормозит конвейер процессора.
В развернутой версии четыре вычитания ( - '0' ) и три умножения констант ( * 1000 , * 100 , * 10 ) являются полностью независимыми операциями. Современный процессор, работающий не по порядку (например, i7 или Xeon), может выполнять их все одновременно с помощью своих суперскалярных блоков исполнения. Единственная оставшаяся последовательная зависимость - одно умножение на 10000 на четыре цифры вместо четырех последовательных умножений на 10.
Это называется параллелизмом на уровне инструкций (Instruction-Level Parallelism, ILP) - мы реструктурируем вычисления таким образом, чтобы несколько ALU процессора использовались параллельно, а не простаивали в ожидании разрешения одной цепочки зависимостей. В результате на пути разбора целого числа происходит примерно в 2-3 раза меньше остановок конвейера.
Кроме того, условие цикла ( i <= n_len - 4 ) оценивается раз в четыре разряда, а не раз на разряд, что сокращает накладные расходы на предсказание ветвлений в 4 раза.
В MQL5 не применяются агрессивные оптимизации компилятора, как в GCC ( -O2 ) или MSVC ( /O2 ), поэтому мы применяем эти классические приемы вручную. Точно такую же схему вы найдете в simdjson, rapidjson и большинстве парсеров продакшн-класса.
Оставшиеся цифры (когда длина числа не кратна 4) обрабатываются стандартным циклом возврата сразу после:
// Tail: handles remaining 0-3 digits
for (; i < n_len; i++)
val = val * 10 + (buffer[ptr + i] - '0'); Ничего экзотического. Просто инженерия.
В развернутой версии четыре вычитания ( - '0' ) и три умножения констант ( * 1000 , * 100 , * 10 ) являются полностью независимыми операциями. Современный процессор, работающий не по порядку (например, i7 или Xeon), может выполнять их все одновременно с помощью своих суперскалярных блоков исполнения. Единственная оставшаяся последовательная зависимость - одно умножение на 10000 на четыре цифры, вместо четырех последовательных умножений на 10.
Торговый форум, автоматические торговые системы и тестирование торговых стратегий
Библиотеки: JSON библиотека для LLM
Джонатан Перейра, 2026.02.17 14:27
// Unrolled: 4 digits per iteration, parallel-friendly
for (; i <= n_len - 4; i += 4) {
val = val * 10000 + (buffer[ptr + i] - '0') * 1000 +
(buffer[ptr + i + 1] - '0') * 100 +
(buffer[ptr + i + 2] - '0') * 10 +
(buffer[ptr + i + 3] - '0');
} Почему бы и нет?
val = val * 10000 + buffer[ptr + i] * 1000 + buffer[ptr + i + 1] * 100 + buffer[ptr + i + 2] * 10 + buffer[ptr + i + 3] - '0' * 1111;
Вы правы. Алгебраическая факторизация верна:
// Current (4 subtractions at runtime): (buf[i] - '0') * 1000 + (buf[i+1] - '0') * 100 + (buf[i+2] - '0') * 10 + (buf[i+3] - '0') // Your suggestion (1 subtraction, compile-time constant): buf[i] * 1000 + buf[i+1] * 100 + buf[i+2] * 10 + buf[i+3] - '0' * 1111
Поскольку '0' * 1111 равно 53328, что является константой времени компиляции, это устраняет три вычитания времени выполнения. Это правильная микрооптимизация, и я приму ее в следующем патче. Хорошая находка.
Это ожидаемо при текущей полезной нагрузке бенчмарка. Тестовые числа небольшие - 12345 , 1 , 2 , 0.0005 - в большинстве из них меньше 4 целых цифр, поэтому развёрнутый путь выполняется редко, и всё обрабатывает резервный цикл. Оптимизация нацелена на полезную нагрузку с плотными числовыми массивами, большими временными метками (13+ цифр) или высокоточными финансовыми данными, где целочисленная часть имеет большое значение.
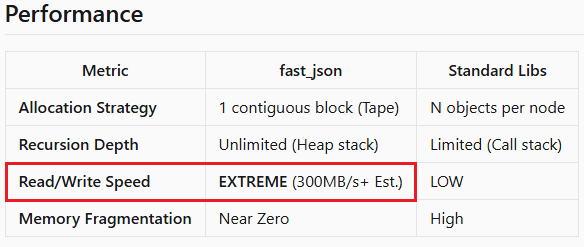
Тем не менее, в данном контексте преимущество ILP реально, но незначительно. Основное преимущество производительности fast_json связано с архитектурой нулевого распределения на ленте и сканированием строк SWAR, а не с FastAtoi. Развернутый цикл является вторичной оптимизацией - правильной, но не главной.
Оптимизация нацелена на полезную нагрузку с плотными числовыми массивами, большими временными метками (13+ цифр) или высокоточными финансовыми данными, в которых важна целочисленная часть.
Форум о трейдинге, автоматизированных торговых системах и тестировании торговых стратегий
Alain Verleyen, 2025.12.20 17:53
Сравнение этой библиотеки со старым JASon, с файлом данных размером 100 МБ
Форум о трейдинге, автоматизированных торговых системах и тестировании торговых стратегий
Обсуждение статьи "Mastering JSON: Create Your Own JSON Reader from Scratch in MQL5"
trader6_1, 2025.10.29 16:31
https://fapi.binance.com/fapi/v1/exchangeInfo
https://eapi.binance.com/eapi/v1/exchangeInfo
778 КБ (796,729 байт).
Вы создаете промежуточную сущность - строку.
case J_INT: PutRaw(IntegerToString(GetInt(idx)), out, pos, cap); break; case J_DBL: PutRaw(DoubleToString(GetDouble(idx)), out, pos, cap); break;
void PutRaw(string s, uchar &out[], int &pos, int &cap) { int l = StringLen(s); CheckCap(l, pos, cap, out); String ToCharArray(s, out, pos, l); pos += l; }
Прямая десятичная нотация должна быть более эффективной.
case J_INT: PutRawInteger(GetInt(idx), out, pos, cap); break; case J_DBL: PutRawDouble(GetDouble(idx), out, pos, cap); break;
Я обязательно добавлю набор данных Binance в набор тестов. В настоящее время моя "реальная жизнь" состоит из ответов API LLM (OpenAI/Anthropic), которые представляют собой глубоко вложенные JSON-структуры, отражающие контекст разговора и вызов функций, а не просто большие плоские массивы данных о тиках. Архитектура парсера (ленточная, нерекурсивная) была оптимизирована специально для этой рекурсивной сложности.
Вы создаете промежуточную сущность - строку. Прямая десятичная нотация должна быть более эффективной.
Вы снова абсолютно правы. IntegerToString создает временный строковый объект MQL, который требует выделения кучи (и последующего давления GC) только для копирования байтов в буфер. PutRawInteger, который записывает цифры непосредственно в поток uchar[], будет иметь нулевое выделение.
Единственная оговорка - реализация собственного itoa в MQL5-скрипте, который выигрывает у нативного (внутреннего для C++) IntegerToString по скорости, но отсутствие выделения определенно делает его стоящим для высокопроизводительной сериализации.
Я реализую пользовательские i64toa и dtoa для устранения этих промежуточных строк в следующем обновлении. Спасибо за обзор кода, острые глаза!
И наконец, поскольку этот проект полностью открыт, для меня будет честью получить ваш вклад.
Если вы хотите отправить Pull Request с этими оптимизациями (или другими, которые вы можете найти), я буду более чем счастлив рассмотреть и объединить их. Всегда приятно сотрудничать с человеком, который глубоко разбирается в технических нюансах.
Не стесняйтесь проверять/собирать репо: https://forge.mql5.io/14134597/fast_json.git

- 14134597
- forge.mql5.io
Это из-за MQL5 такое большое отставание в производительности по сравнению с другими реализациями?
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Библиотека JSON для LLM:
Библиотека JSON, предназначенная для массового использования LLM и снижения задержек.
Автор: Jonathan Pereira