Bibliotecas: JSON Library for LLMs
Why is this cycle needed?
long FastAtoi(int ptr, int n_len) { long val = 0; int sign = 1; int i = 0; if (buffer[ptr] == '-') { sign = -1; i++; } for (; i <= n_len - 4; i += 4) { val = val * 10000 + (buffer[ptr + i] - '0') * 1000 + (buffer[ptr + i + 1] - '0') * 100 + (buffer[ptr + i + 2] - '0') * 10 + (buffer[ptr + i + 3] - '0'); } for (; i < n_len; i++) val = val * 10 + (buffer[ptr + i] - '0'); return val * sign; }
That's a 4x loop unrolling on the integer parser ( FastAtoi ). Instead of converting one digit per iteration:
// Naive: 1 digit per iteration, serial dependency chain
for (int i = 0; i < n_len; i++)
val = val * 10 + (buffer[ptr + i] - '0'); We process four digits at once:
// Unrolled: 4 digits per iteration, parallel-friendly
for (; i <= n_len - 4; i += 4) {
val = val * 10000 + (buffer[ptr + i] - '0') * 1000 +
(buffer[ptr + i + 1] - '0') * 100 +
(buffer[ptr + i + 2] - '0') * 10 +
(buffer[ptr + i + 3] - '0');
} Why it matters — Instruction-Level Parallelism (ILP):
In the naive loop, every iteration depends on the result of the previous one — you cannot compute val * 10 until the prior val * 10 + digit completes. This creates a serial dependency chain that stalls the CPU pipeline.
In the unrolled version, the four subtractions ( - '0' ) and the three constant multiplications ( * 1000 , * 100 , * 10 ) are completely independent operations. A modern out-of-order CPU (like the i7 or Xeon) can dispatch all of them simultaneously through its superscalar execution units. The only remaining serial dependency is one multiplication by 10000 per four digits, instead of four sequential multiplications by 10.
This is called Instruction-Level Parallelism (ILP) — we restructure the computation so that the CPU's multiple ALUs are utilized in parallel rather than sitting idle waiting for a single dependency chain to resolve. The result is roughly 2-3x fewer pipeline stalls on the integer parsing path.
Additionally, the loop condition ( i <= n_len - 4 ) is evaluated once every four digits instead of once per digit, reducing branch prediction overhead by 4x.
MQL5 does not apply aggressive compiler optimizations like GCC ( -O2 ) or MSVC ( /O2 ) would, so we apply these classical techniques by hand. You will find the exact same pattern in simdjson, rapidjson, and most production-grade parsers.
The remaining digits (when the number length is not a multiple of 4) are handled by the standard fallback loop immediately after:
// Tail: handles remaining 0-3 digits
for (; i < n_len; i++)
val = val * 10 + (buffer[ptr + i] - '0'); Nothing exotic. Just engineering.
In the unrolled version, the four subtractions ( - '0' ) and the three constant multiplications ( * 1000 , * 100 , * 10 ) are completely independent operations. A modern out-of-order CPU (like the i7 or Xeon) can dispatch all of them simultaneously through its superscalar execution units. The only remaining serial dependency is one multiplication by 10000 per four digits, instead of four sequential multiplications by 10.
Fórum de negociação, sistemas de negociação automatizados e testes de estratégias de negociação
Bibliotecas: JSON Library for LLMs
Jonathan Pereira, 2026.02.17 14:27
// Unrolled: 4 digits per iteration, parallel-friendly
for (; i <= n_len - 4; i += 4) {
val = val * 10000 + (buffer[ptr + i] - '0') * 1000 +
(buffer[ptr + i + 1] - '0') * 100 +
(buffer[ptr + i + 2] - '0') * 10 +
(buffer[ptr + i + 3] - '0');
} Why not?
val = val * 10000 + buffer[ptr + i] * 1000 + buffer[ptr + i + 1] * 100 + buffer[ptr + i + 2] * 10 + buffer[ptr + i + 3] - '0' * 1111;
You are correct. The algebraic factoring is valid:
// Current (4 subtractions at runtime): (buf[i] - '0') * 1000 + (buf[i+1] - '0') * 100 + (buf[i+2] - '0') * 10 + (buf[i+3] - '0') // Your suggestion (1 subtraction, compile-time constant): buf[i] * 1000 + buf[i+1] * 100 + buf[i+2] * 10 + buf[i+3] - '0' * 1111
Since '0' * 1111 equals 53328 , which is a compile-time constant, this eliminates three runtime subtractions. It is a valid micro-optimization and I will adopt it in the next patch. Good catch.
That is expected with the current benchmark payload. The test numbers are small — 12345 , 1 , 2 , 0.0005 — most have fewer than 4 integer digits, so the unrolled path rarely executes and the fallback loop handles everything. The optimization targets payloads with dense numeric arrays, large timestamps (13+ digits), or high-precision financial data where the integer portion is significant.
That said, the ILP benefit is real but marginal in this context. The primary performance advantage of fast_json comes from the tape-based zero-allocation architecture and SWAR string scanning, not from FastAtoi . The unrolled loop is a secondary optimization — correct, but not the main story.
The optimization targets payloads with dense numeric arrays, large timestamps (13+ digits), or high-precision financial data where the integer portion is significant.
Forum on trading, automated trading systems and testing trading strategies
Alain Verleyen, 2025.12.20 17:53
Comparison of this library with the old JASon, with a data file of 100 MB
Forum on trading, automated trading systems and testing trading strategies
Discussing the article: "Mastering JSON: Create Your Own JSON Reader from Scratch in MQL5"
trader6_1, 2025.10.29 16:31
https://fapi.binance.com/fapi/v1/exchangeInfo
https://eapi.binance.com/eapi/v1/exchangeInfo
778 KB (796,729 bytes).
You create an intermediate entity - a string.
case J_INT: PutRaw(IntegerToString(GetInt(idx)), out, pos, cap); break; case J_DBL: PutRaw(DoubleToString(GetDouble(idx)), out, pos, cap); break;
void PutRaw(string s, uchar &out[], int &pos, int &cap) { int l = StringLen(s); CheckCap(l, pos, cap, out); StringToCharArray(s, out, pos, l); pos += l; }
Direct decimal notation should be more efficient.
case J_INT: PutRawInteger(GetInt(idx), out, pos, cap); break; case J_DBL: PutRawDouble(GetDouble(idx), out, pos, cap); break;
I will certainly add the Binance dataset to the test suite. Currently, my "real life" workload consists of LLM API Responses (OpenAI/Anthropic), which are deeply nested JSON structures representing conversational context and function calling, rather than just large flat arrays of tick data. The parser's architecture (tape-based, non-recursive) was optimized specifically for that recursive complexity.
You create an intermediate entity - a string. Direct decimal notation should be more efficient.
You are absolutely correct again. IntegerToString creates a temporary MQL string object, which incurs a heap allocation (and subsequent GC pressure) just to copy bytes into the buffer. A PutRawInteger that writes digits directly to the uchar[] stream would be zero-allocation.
The only caveat is implementing a custom itoa in MQL5 script that beats the native (C++ internal) IntegerToString in raw speed, but avoiding the allocation definitely makes it worth it for high-throughput serialization.
I will implement a custom i64toa and dtoa to eliminate these intermediate strings in the next update. Thanks for the code review, sharp eyes!
And finally, since this project is fully open-source, I would be honored to have your contribution.
If you'd like to submit a Pull Request with these optimizations (or others you might find), I'd be more than happy to review and merge them. It's always great to collaborate with someone who deeply understands the technical nuances.
Feel free to check/fork the repo: https://forge.mql5.io/14134597/fast_json.git

- 14134597
- forge.mql5.io
Is it because of MQL5 that there is such a big performance lag compared to other implementations?
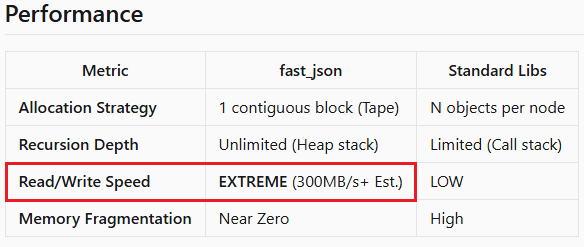
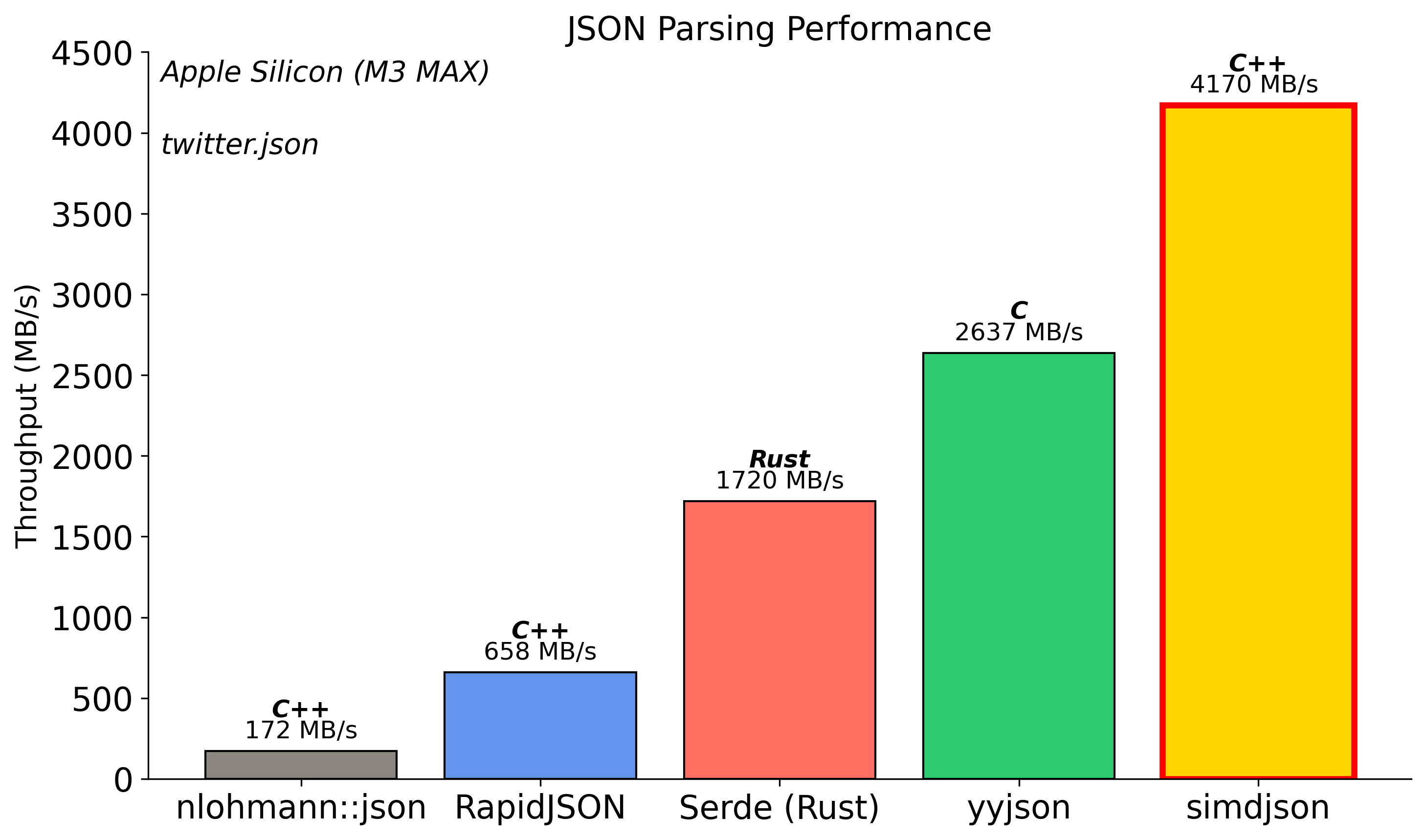
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
JSON Library for LLMs:
Uma biblioteca JSON projetada para uso massivo de LLMs e menor latência.
Autor: Jonathan Pereira