Discussão do artigo "O escore de propensão na inferência causalidade"
https://www.mql5.com/pt/code/48482
Um arquivo de modelos do artigo (exceto o primeiro da lista), para referência rápida sem instalar o Python.

- www.mql5.com
Olá, usei seu método: propensity_matching_naive.py nos parâmetros que defini para o treinamento de 25 modelos. Após o treinamento, apareceu na pasta do diretório python :
catboost_info .
O que eu tentei fazer? Carreguei as cotações h1 do AUDCAD e, em seguida, usei o arquivo:
propensity_matching_naive.py de sua publicação: https: //www.mql5.com/ru/articles/14360.
Não consigo entender o que fazer em seguida, o que salvar no formato ONNX, ou esse método funciona apenas como uma avaliação de qualidade de teste? :
catmodel propensity matching naive.onnx
catmodel_m propensity matching naive.onnx
Usei o pythom pela primeira vez na vida, instalei sem problemas, as bibliotecas também não são difíceis. Li suas publicações, a abordagem é séria, mas talvez não seja o método de cálculo mais fácil, posso estar errado, tudo é relativo.
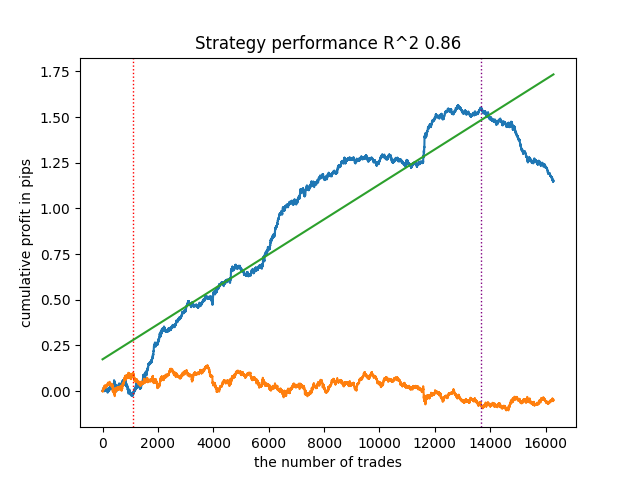
Anexei telas, o que obtive em meu treinamento.
 в причинно-следственном выводе")
- www.mql5.com
{kind=link}
{kind=link}
Olá, usei seu método: propensity_matching_naive.py nos parâmetros que defini para o treinamento de 25 modelos. Após o treinamento, apareceu na pasta do diretório python :
catboost_info .
O que eu tentei fazer? Carreguei as cotações h1 do AUDCAD e, em seguida, usei o arquivo:
propensity_matching_naive.py de sua publicação: https: //www.mql5.com/ru/articles/14360.
Não consigo entender o que fazer em seguida, o que salvar no formato ONNX, ou esse método funciona apenas como uma avaliação de qualidade de teste? :
catmodel propensity matching naive.onnx
catmodel_m propensity matching naive.onnx
Estou usando o pythom pela primeira vez na minha vida, instalei-o sem problemas, as bibliotecas também não são difíceis. Li suas publicações, a abordagem é séria, mas talvez não seja o método de cálculo mais fácil, posso estar errado, tudo é relativo.
Anexei telas, o que obtive em meu treinamento.
Bom. Em artigos anteriores, foram descritas duas maneiras de exportar.
1. a anterior, exportando o modelo para o código MQL nativo
2. exportar para o formato onnx em artigos posteriores.
Não me lembro se há uma função de exportação de modelo nos arquivos python deste artigo. "export_model_to_ONNX()". Se não houver, você pode usar as anteriores.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo O escore de propensão na inferência causalidade foi publicado:
O artigo examina o tema de pareamento na inferência causal. O pareamento é utilizado para comparar observações semelhantes em um conjunto de dados. Isso é necessário para determinar corretamente os efeitos causais e eliminar o viés. O autor explica como isso ajuda na construção de sistemas de negociação baseados em aprendizado de máquina, que se tornam mais estáveis em novos dados nos quais não foram treinados. O escore de propensão desempenha um papel central e é amplamente utilizado na inferência causal.
Neste artigo, abordarei o tema de pareamento mencionado brevemente no artigo anterior, ou melhor, uma de suas variedades - pareamento por escore de propensão.
Isso é importante porque temos um determinado conjunto de dados rotulados que é heterogêneo. Por exemplo, no Forex, cada exemplo individual de treinamento pode pertencer à área de alta ou baixa volatilidade. Além disso, alguns exemplos podem aparecer mais frequentemente na amostra, enquanto outros aparecem com menos frequência. Ao tentar determinar o efeito causal médio (ATE) em uma amostra assim, inevitavelmente encontraremos estimativas enviesadas se assumirmos que todos os exemplos na amostra têm a mesma propensão para produzir tratamento. Ao tentar obter um efeito médio de tratamento condicional (CATE), podemos encontrar um problema chamado "maldição da dimensionalidade".
O pareamento é uma família de métodos para estimar efeitos causais ao parear observações (ou unidades) semelhantes nos grupos de tratamento e controle. O objetivo do pareamento é fazer comparações entre unidades semelhantes para obter uma estimativa o mais precisa possível do verdadeiro efeito causal.
Autor: Maxim Dmitrievsky