O "New Neural" é um projecto de motor de rede neural Open Source para a plataforma MetaTrader 5. - página 9
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Não pode ser assim. Diferentes tipos em diferentes camadas. Estou a dizer-te, até podias fazer de cada neurónio uma camada separada.
Sobre o amortecedor, deixe-me dar-lhe um exemplo. Deixa-me ir para casa.
Uma camada é uma união de neurônios independentes uns dos outros em uma iteração.
Quem diz que não pode ser, mas eu quero, mas tu estás a cortar-me as asas :o)
Nunca se sabe o que as pessoas podem inventar, e dizer-lhes que todos os neurónios de uma camada devem ter o mesmo número de inputs.
Todos eles devem ser diferentes, mesmo para neurónios da mesma camada, caso contrário, vamos obter apenas um monte de algoritmos (muitos deles na Internet) que precisam de ser sombreados a fim de ligar algo.
SZY Quão mais difícil seria o algoritmo se cada neurónio tivesse uma camada separada?
Quem pode aconselhar algum software de desenho online para diagramas e merdas assim?
O Google Docs tem desenhos, você pode compartilhá-los.
Posso fazer algum trabalho de desenho em part-time, desde que não seja mais do que uma hora por dia.
OK, para mim, 4 das redes implementadas são de interesse
1. Redes Kohonen, incluindo a SOM. Bom de usar para partições em cluster onde não é claro o que procurar. Eu acho que a topologia é bem conhecida: vetor como entrada, vetor como saída ou saídas agrupadas de outra forma. A aprendizagem pode ser com ou sem um professor.
2. MLP , na sua forma mais geral, ou seja, com um conjunto arbitrário de camadas organizadas como um gráfico com feedbacks. Usado muito amplamente.
3. Rede de recirculação. Francamente falando, eu nunca vi uma boa implementação não linear a funcionar. É utilizado para compressão de informação e extração de componentes principais (PCA). Na sua forma linear mais simples, é representada como uma rede linear de duas camadas na qual o sinal pode ser propagado de ambos os lados (ou de três camadas na sua forma desdobrada).
4.Echo rede. Similar em princípio ao MLP, aplicado lá também. Mas totalmente diferente na organização e tem um tempo de aprendizagem bem definido (bem, e sempre produz um mínimo global, ao contrário).
5. PNN -- Eu não o usei, não sei. Mas acho que vou encontrar alguém que o faça.
6. Modelos para lógica fuzzy (não confundir com redes probabilísticas). Não implementado. Mas pode ser útil. Se alguém encontrar informações, atira o plz. Quase todos os modelos têm autoria japonesa. Quase todos são construídos manualmente, mas se fosse possível automatizar a construção da topologia por expressão lógica(se me lembro de tudo corretamente), seria irrealisticamente legal.
+ redes com aumento evolutivo do número de neurónios ou vice versa.
+ aloritmos genéticos + métodos de aceleração de aprendizagem.
Encontrei uma pequena classificação como esta.
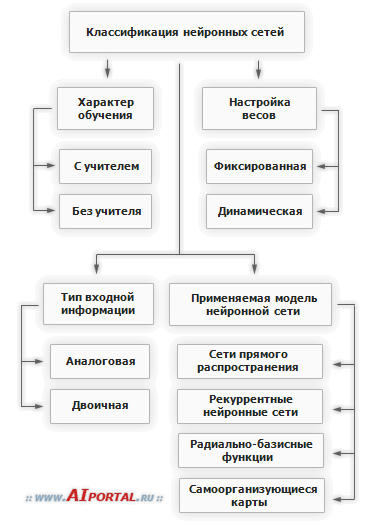
+ aloritmos genéticos
A genética devora muitos recursos extra. Algoritmos gradientes são melhores.
Porquê decidir para os utilizadores o que eles precisam? Tens de lhes dar uma escolha. O PNN, por exemplo, também come muitos recursos.
A biblioteca deve ser universal e vasta, permitindo encontrar variantes de soluções e não em conjunto padrão de retropropagação, que você pode encontrar na web.
Uma camada é uma união de neurônios independentes uns dos outros em uma iteração.
Qual é o objectivo disso?
Nunca se sabe o que as pessoas podem inventar, e dizer-lhes que todos os neurónios da camada devem ter o mesmo número de inputs.
Hmm. Cada neurónio tem uma entrada e uma saída.
Todos os tipos e conexões podem ser diferentes mesmo para neurônios da mesma camada, isso deve ser levado em conta, caso contrário, vamos obter apenas um monte de algoritmos (muitos deles na Internet), que precisam ser moldados a fim de conectar algo.
Primeiro que tudo, ainda não acabei. Segundo, veja as regras. Críticas mais tarde. Não se vê o modelo como um todo e começa-se a criticar. Isso não é bom.
SZY Quão mais difícil seria o algoritmo se cada neurónio tivesse uma camada separada?
Algoritmo para quê? Só iria atrasar a aprendizagem e o funcionamento.
E o que é exactamente uma entidade "tampão"?
Buffer é a entidade através da qual as sinapses e os neurónios comunicam. Mais uma vez, o meu modelo é muito diferente de um modelo biológico.
_____________________
Desculpa não o ter terminado ontem. Esqueci-me de pagar pela internet, fui cortado :)
Uma camada é uma união de neurônios independentes uns dos outros em uma iteração.
Quem diz que não pode ser, mas eu quero, mas tu estás a cortar-me as asas :o)
Eu não sei o que as pessoas podem inventar, você pode dizer que todos os neurônios de uma camada devem ter o mesmo número de entradas.
E tipos e conexões podem ser todos diferentes mesmo para neurônios de uma camada, a partir disso temos que confiar, caso contrário vamos obter apenas um monte de algoritmos (muitos deles na Internet) dos quais temos que procurar algo para conectar.
SZY Quão mais difícil seria o algoritmo se cada neurónio tivesse uma camada separada?
Teoricamente é provavelmente possível, na prática eu não encontrei tal coisa. Mesmo com a ideia pela primeira vez.
Penso que, puramente para fins experimentais, pode-se pensar na sua implementação, no âmbito da implementação do projecto de uma camada "motley" provavelmente não é a melhor ideia em termos de custos de mão-de-obra e eficiência de implementação.
Embora eu pessoalmente goste da idéia, pelo menos essa possibilidade pode valer a pena discutir.
Porquê decidir para os utilizadores o que eles precisam?
? A genética é um método de aprendizagem. A coisa certa a fazer, imho, é esconder os algoritmos de aprendizagem, escolhendo primeiro o melhor.
? A genética é um método de aprendizagem. O mais correto imho para enterrar os algoritmos de aprendizagem, pré-selecionando o ótimo.
Trabalhar com os NS é apenas escolher a sua topologia? O método de treinamento também desempenha um papel importante. Topologia e aprendizagem estão intimamente ligados.
Todos os utilizadores têm o seu próprio imho, por isso não se pode tirar-lhes metade da tomada de decisões.
Precisamos de criarum construtor de redes que não seja limitado por nenhuma predefinição. E tão universal quanto possível.
Sergeev:
A biblioteca deve ser universal e vasta, abrindo a porta para variantes de soluções, e não no conjunto padrão de retropropagação, que você pode encontrar na web de qualquer maneira.
Trabalhar com os NS é apenas escolher a sua topologia? O método de treinamento também desempenha um papel importante. Topologia e aprendizagem estão intimamente ligados.
Todos os usuários têm seu próprio imho, então você não pode tomar metade da decisão sobre si mesmo.
Precisamos de criarum construtor de rede que não se limite a qualquer predefinição. E tão universal quanto possível.