Aprendizado de máquina no trading: teoria, prática, negociação e não só - página 1489
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Se alguém entender HMM, por favor me ajude a resolver o problema, se o problema for resolúvel, então eu vou compartilhar o graal)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Se alguém entender HMM, por favor me ajude a resolver o problema, se o problema for resolúvel, então eu vou compartilhar o graal)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Bem, o estado é Markovian, mas qual é o modelo?
significa que você precisa de mais pontos para a janela quadrada, pelo menos
e se uma série aleatória é alimentada, de que tipo de previsão, além de 50\50, podemos falar?significa que você precisa de mais pontos para a janela ao quadrado, no mínimo
Eu disse-te, até levei vários milhares de pontos
e se uma série aleatória é inserida, então que tipo de previsão, além de 50/50, podemos falar?
Que diferença isso faz, os dados são os mesmos, o modelo é o mesmo
Prevejo novos dados usando toda a função no pacote (como em todos os exemplos na rede ...) os resultados são ótimos
Eu uso o mesmo modelo para prever os mesmos dados , mas com janela deslizante e o resultado é inaceitável.
Essa é a questão - qual é o problema?Eu disse-te que até tirei vários milhares de pontos.
que diferença faz, os dados são os mesmos, o modelo é o mesmo
Prevejo novos dados usando toda a função no pacote (como em todos os exemplos na web ...) os resultados são ótimos
Prevejo os mesmos dados com o mesmo modelo mas com uma janela deslizante e o resultado é diferente, inaceitável.
Essa é a verdadeira questão - qual é o problema?Eu não sei que tipo de modelo e de onde estás a tirar os estados. sem nenhum pacote, qual é o objectivo?
Talvez haja um gcf que não dê nenhum estado aleatório, é por isso que é previsto no 1º caso. Tente mudar a semente tanto para o comboio como para o teste para ver que no 1º caso é impossível prever algo, caso contrário não sei como ajudar a ideia não está clara.
As partições são feitas de acordo com a probabilidade de classificação. Mais precisamente, não por probabilidade, mas por erro de classificação. Porque tudo é conhecido no exercício de treinamento, e não temos probabilidade, mas uma estimativa exata.
Embora existam fi ries de separação diferentes, ou seja, medidas de impureza (amostragem à esquerda ou à direita).
Eu estava me referindo à distribuição da precisão da classificação pela amostra, não ao total como é feito agora.
não está claro qual é o modelo e de onde se obtém os estados. Sem nenhum pacote, conceitualmente, qual é o objetivo?
Talvez haja um gcp que não dê nenhuma randomização, é por isso que está previsto no 1º caso. Tente mudar a semente tanto para o trem quanto para o teste para ver se é impossível prever no primeiro caso também, caso contrário não sei como ajudar a idéia.
Aqui está o arquivo, há preços e duas colunas com preditores "data1" e "data2".
Você treina HMM com apenas dois estados(em uma pista de dados sem um professor) para essas duas colunas ("data1" e "data2") em Python ou o que você quiser. Você não toca no preço de forma alguma, apenas o faz para visualização
Então você pega o algoritmo de Viterbi e vem com um (teste de dados).
temos dois estados, deve parecer assim.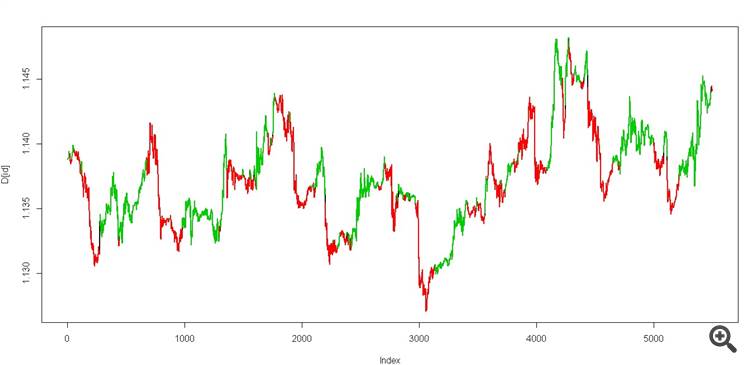
é um verdadeiro graal))
E depois tente calcular o mesmo Viterbi na janela deslizante usando os mesmos dados
Aqui está um arquivo com preços e duas colunas com os preditores "data1" e "data2".
Você treina HMM com apenas dois estados(em uma pista de dados) usando essas duas colunas ("data1" e "data2") em Python ou o que você quiser. Você não toca no preço de forma alguma, apenas o usa para visualização.
Em seguida, você faz o algoritmo de Viterbi e (teste de dados)
temos dois estados, deve parecer assim.
É um verdadeiro graal).
E depois tente o mesmo cálculo de Viterbi na janela deslizante sobre os mesmos dados.
Senk, vou ver mais tarde, aviso-te, porque estou a trabalhar com um Markovian.
Senk, vou verificar mais tarde e aviso-te, já que eu próprio estou a trabalhar com o Markov.
Alguma sorte?
Alguma sorte?
Ainda não estou a olhar, dia de folga ) Eu aviso-te quando tiver tempo, no final da semana, quero dizer.
a olhar para os pacotes até agora. Acho que se encaixa emhttps://hmmlearn.readthedocs.io/en/latest/tutorial.html