Discussão do artigo "Gás neural em desenvolvimento: Implementação em MQL5"
Parece legal :)
Mas ainda não descobri o que é e como usá-lo :)
Parece legal :)
Mas o que ele é e como usá-lo, precisamos descobrir mais :)
pode ser usado como a primeira camada oculta - para redução de dimensionalidade ou agrupamento em si, pode ser usado em redes probabilísticas e muitas outras opções.
Obrigado pelo material!
Tentarei aprendê-lo em meu tempo livre :)
Obrigado pelo novo artigo sobre um método de rede interessante. Se você analisar a literatura, verá que há dezenas, se não centenas deles. Mas o problema para os operadores não está na falta de ferramentas, mas em usá-las corretamente. O artigo seria ainda mais interessante se contivesse um exemplo de uso desse método em um Expert Advisor.

Obrigado pelo novo artigo sobre um método de rede interessante. Se você analisar a literatura, verá que há dezenas, se não centenas deles. Mas o problema para os operadores não está na falta de ferramentas, mas em usá-las corretamente. O artigo seria ainda mais interessante se contivesse um exemplo de uso desse método em um Expert Advisor.
1. O artigo é bom. Ele é apresentado de forma acessível e o código não é complicado.
2. As desvantagens do artigo incluem o fato de que nada é dito sobre os dados de entrada da rede. Você poderia ter escrito algumas palavras sobre o que é a entrada - vetor de cotações para o período/dados do indicador, vetor de desvios de preço, cotações normalizadas ou outra coisa. Para o uso prático do algoritmo, a questão dos dados de entrada e sua preparação são fundamentais. Recomendo usar um vetor de alterações de preços relativos para esses algoritmos: x[i]=preço[i+1]-preço[i].
Além disso, de antemão, o vetor de entrada pode ser normalizado (x_normal[i]=x[i]/M), para o qual o desvio máximo do preço para o período em consideração pode ser usado como M (aqui e abaixo, para fins de brevidade, não escrevo declarações de variáveis):
M=x[ArrayMaximum(x)]-x[ArrayMinimum(x)];
Nesse caso, todos os vetores de entrada ficarão em um hipercubo unitário com lado [-0,5,0,5], o que aumentará significativamente a qualidade do agrupamento. Você também pode usar o desvio normal padrão ou qualquer outra variável de média sobre os desvios relativos das cotações durante o período como M.
3. O documento sugere usar o quadrado da norma da diferença como a distância entre o vetor de pesos do neurônio e o vetor de entrada:
for(i=0, sum=0; i<m; i++, sum+=Pow(x[i]-w[i],2));
Em minha opinião, essa função de distância não é eficaz nessa tarefa de agrupamento. Mais eficaz é a função que calcula o produto escalar ou o produto escalar normalizado, ou seja, o cosseno do ângulo entre o vetor de peso e o vetor de entrada:
for(i=0, norma_x=0, norma_w=0; i<m; i++, norma_x+=x[i]*x[i], norma_w+=w[i]*w[i]); norma_x=sqrt(norma_x); norma_w=sqrt(norma_w); for(i=0, sum=0; i<m; i++, sum+=x[i]*w[i]); if(norma_x*norma_w!=0) sum=sum/(norma_x*norma_w);
Assim, em cada cluster serão agrupados vetores semelhantes entre si pelas direções das oscilações, mas não pela magnitude dessas oscilações, o que reduzirá significativamente a dimensionalidade do problema a ser resolvido e aumentará as características das distribuições de pesos da rede neural treinada.
4.Foi observado corretamente que é necessário definir um critério de parada para o treinamento da rede. O critério de parada deve determinar o número necessário de clusters da rede treinada. E ele (o número), por sua vez, depende do problema geral a ser resolvido. Se a tarefa for prever uma série temporal para 1-2 amostras à frente e, para isso, por exemplo, for usado um perseptron multicamadas, o número de clusters não deve ser muito diferente do número de neurônios da camada de entrada do perseptron.

Em geral, o número de barras no histórico não excede 5.300.000 no gráfico de minutos mais detalhado (10 anos*365 dias*24 horas*60 minutos). No gráfico horário, são 87.000 barras. Ou seja, a criação de um classificador com o número de clusters superior a 10000-20000 não se justifica devido ao efeito de "overtraining", quando cada vetor de cotações tem seu próprio cluster separado.
Peço desculpas por possíveis erros.
1. Obrigado, fiz o melhor que pude por você:)
2. Sim, eu concordo. Mas ainda assim os insumos - esse é um grande problema separado, sobre o qual você pode escrever dezenas de artigos.
3 - E aqui eu discordo completamente. No caso de entradas normalizadas, a comparação de produtos escalares é equivalente à comparação de normas euclidianas - expanda as fórmulas.
4. Já que o número máximo de clusters já é um dos parâmetros do algoritmo.
max_nodes
Eu procederia, por exemplo, da seguinte forma: meça o erro do vencedor nas últimas N etapas e avalie sua dinâmica de alguma forma (por exemplo, meça a inclinação da linha de regressão). Se o erro ainda estiver diminuindo e os dados de treinamento já tiverem se esgotado, vale a pena considerar a suavização deles para suprimir o ruído ou, de alguma forma, eliminar o déficit de exemplos.
3. não entendo onde está a equivalência das fórmulas. A fórmula para o cosseno do ângulo entre os vetores(x,w)/ (|x|||w|) é "não muito" semelhante a |x-w|^2. A normalização das entradas não altera as diferenças fundamentais entre essas medidas:
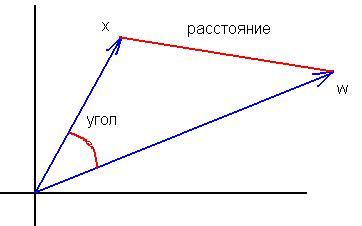
A equivalência é que o máximo da distância sempre corresponde ao mínimo do produto escalar e vice-versa. A relação no caso de vetores normalizados é mutuamente inequívoca e monotônica, de modo que não importa se é preciso calcular o quadrado da distância ou o ângulo.
Oi Alex,
Obrigado pela explicação clara sobre o assunto.
Seria possível compartilhar algum código prático para a reconstrução do preço futuro, por exemplo, a partir de sinais ótimos.
A ideia é:
1. Entrada (fonte): várias moedas (18)
2. Destino: Sinal ideal da moeda que gostaríamos de prever (figura: 2. Optimal_Signals)
3. Encontrar uma neuroconexão entre Source e Destination e explodi-la na negociação.

Outra pergunta sobre a reconstrução de NN:
É possível, em vez de amostras aleatórias, usar nossas amostras, como na figura 2:
Nosso cérebro pode reconstruir a imagem em menos de um segundo, vamos ver quanto tempo leva para a NN fazer o mesmo, apenas uma brincadeira, não é um desafio.

As amostras geradas aleatoriamente não são muito interessantes de se ver, pois não há nenhum significado por trás delas ou seu uso; no entanto, se pudermos desenhar nós mesmos os pontos com algum significado por trás deles, será muito mais divertido :-0).

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Gás neural em desenvolvimento: Implementação em MQL5 foi publicado:
Este artigo mostra um exemplo de como desenvolver um programa MQL5 implementando o algorítimo adaptável de fazer o cluster chamado gás neural em desenvolvimento (GNG). O artigo é destinado para usuários que tenham estudado a documentação de linguagem e têm determinadas habilidades de programação e conhecimento básico na área de neuroinformática.
Autor: Алексей