Ricordando i veterani: Box e Jenkins
Bisogna iniziare dalla fonte
Non linkare, o ci sarà un altro thread di Econometria 2 dove quasi nessuno capisce davvero cosa stai cercando di ottenere. Con le tue stesse parole, faa!
Recentemente ho letto un articolo secondo cui le code spesse sono causate da outlier, spesso singoli outlier. Ricordo che lei aveva un'opinione diversa. Potrei sbagliarmi però.
Come arrivarci? Da niente da fare, combattendo la palese ignoranza tra i forumer. Don Chisciotte. Ci sono molte persone qui che sono orgogliose del fatto che non leggono nulla. È semplicemente terribile! Ed ecco due link in una volta sola.
No. Solo l'originale può essere discusso. Nessuna "dichiarazione moderna" è accettabile
Forse non l'ho detto con precisione. Il collegamento è completamente in linea con l'originale e può essere più ampio. Ma non è questo il punto.
Facciamo una digressione.
Qual è la semantica di un operatore del linguaggio di programmazione? È il programma, il codice che esegue quell'operatore.
Cos'è un modello ARMA? Questo è il codice che esegue quel modello.
Se ci allontaniamo da questa interpretazione, siamo destinati ad affogare in diverse interpretazioni da parte di persone alfabetizzate e in sovra-interpretazioni a livello di termini degli ignoranti.
In questo forum - un programma (codice eseguibile) è semantica. Quindi la semantica del libro di Box è un programma, come la STATISTICA, che dà un significato prezioso alle formule di trading, alle parole.
Cominciamo.
Un modello ARIMA è scritto nella forma: ARIMA (p,d,q) o AR(p) I(d) MA(q), dove p e q sono il numero di ritardi nell'equazione di regressione e d è il numero di volte che la serie originale è stata differenziata.
Per prima cosa prendiamo l'ARMA e selezioniamo il numero di ritardi. Prendiamo EURUSD da 2011.11.28 00:00 a 2011.12.23 21:00. Questo è un numero intero di settimane, ogni settimana ha 118 barre orarie - tutte le 472 barre.
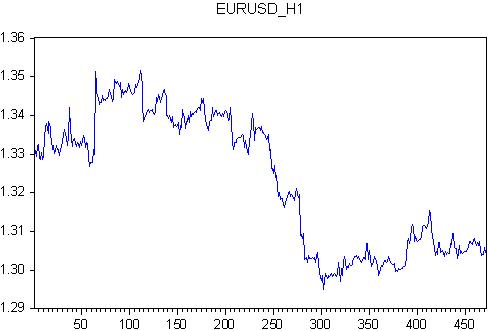
Per questa citazione scriviamo l'equazione regex
eurusd ar(1) ma(1) c @trend
cioè definiamo il quoziente EURUSD attraverso autoregressione, errore, spostamento (costante) e tendenza lineare
Stimiamo i coefficienti di questa regressione.

Abbiamo ottenuto un risultato decente su due parametri e un risultato piatto sugli altri due parametri: @trend ma(1) hanno valori di errore molto grandi nella stima dei coefficienti.
Qual è il risultato pratico di questo esercizio?
(1) Abbiamo un'equazione che può essere programmata come un indicatore con caratteristiche in forma numerica.
(2) Il nostro indicatore prende in considerazione solo il valore precedente del quoziente e la differenza tra il quoziente e il valore di regressione. Quindi il nostro indicatore è più preciso.
(3) Risultato completamente nuovo per l'AT: i coefficienti di un indicatore sono variabili casuali. Almeno una conclusione: gli indicatori senza adattare i coefficienti alla quotazione attuale non hanno senso.
.....
(2) Il nostro indicatore prende in considerazione solo il valore precedente del quoziente e la differenza tra il quoziente e il valore di regressione. Quindi il nostro indicatore è più preciso.
(3) Un risultato completamente nuovo per l'AT: i coefficienti dell'indicatore sono variabili casuali. Almeno una conclusione: gli indicatori senza adattamento del rapporto alla quotazione attuale non hanno senso.
(2) Più preciso di cosa?
(3) A cosa serve se il vostro indicatore è più accurato ma privo di significato?
(2) Più preciso di cosa?
(3) Qual è il profitto nel tuo indicatore che è più accurato ma senza significato?
Siete interessati solo all'interesse personale.
L'econometria nonè per il profitto, ma per la crisi mondiale.
Non importa quale indicatore sia più preciso e non importa che sia privo di significato. La cosa più importante per un nerd è calcolare tutto ciò che gli capita a tiro. Ma il programmatore ha finalmente padroneggiato EViews ed è felice di poter inserire dei dati nel programma e ottenere in cambio dei numeri senza senso. La cosa principale qui non è il risultato, ma la gioia del processo.
L'econometrico vuole che ci rallegriamo insieme a lui. Quindi non roviniamo il suo umore con il mercantilismo e gioiamo delle possibilità insensate dell'econometria.
Onoriamo anche la memoria di Jenkins e Box, gli istigatori della crisi mondiale, con un minuto di silenzio, cioè dovremmo cercare di vivere un minuto intero senza imprecare contro di loro. Non accadrà immediatamente e non per tutti, ma bisogna provare.
(2) Più preciso di cosa?
(3) Qual è il vantaggio del vostro indicatore che è più accurato ma privo di significato?
(2) Più preciso di cosa?
Sta tutto nel confronto. Una volta ha scritto un articolo che HP ha poco a che fare con la citazione. Più preciso di HP, se volete.
(3) Qual è il vantaggio del tuo indicatore che è più preciso ma senza significato?
E questa è la questione fondamentale di tutto in AT e in econometria.
La domanda in risposta è: quale dovrebbe essere il punto?
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Nel 1974, 38 anni fa, fu pubblicato il leggendario libro "Time Series Analysis" di Box e Jenkins. Questo libro ha avuto e continua ad avere un enorme impatto sull'analisi e la previsione delle serie temporali. Ancora oggi, le agenzie governative statunitensi fanno previsioni utilizzando una modifica di questo modello, anche se sono venute fuori molte cose nuove. Ma ricordiamoci dei veterani.
Il libro presenta il modello ARMA, ARIMA nella traduzione russa ARSS o ARPSS.
Ci sono diversi malintesi su questo modello. Cominciamo con il nome.
In russo: ARSS - media autoregressiva e mobile.
AR - autoregressivo - è autoesplicativo. L'ultimo termine della serie temporale è definito attraverso i suoi valori precedenti, ritardati. Un'idea comune a quasi tutti gli indicatori.
SS - media mobile. È qui che diventa difficile. Non ha niente a che vedere con la bilancia. Si tratta di modellare il rumore. Cioè, il modello rappresenta inizialmente il mercato da due componenti: deterministico, che è descritto da AP, e il rumore, che è descritto da MA. Per gli indicatori questa è chiaramente una parola nuova dal 1974!
Esiste un'estensione del modello ARSS sotto forma di ARPSS, dove P è pro-integrato. È qui che entra in gioco. Integrato significa differenziato! Cioè, hanno preso la differenza tra le barre vicine del quoziente!
E il risultato finale di Box e Jenkins. La non stazionarietà del BP è esplicitamente riconosciuta e viene proposta una metodologia per convertire una serie temporale non stazionaria in una stazionaria. La lettera "P" è solo il modo per trasformare la VR non stazionaria in stazionaria.
Più avanti nell'argomento darò i risultati dei calcoli con questo modello. Propongo di discutere i risultati e l'applicabilità a Fora. Il modello è discusso a sufficienza in STATISTICS sia nella documentazione che nell'implementazione del software. Userò EViews, anche se in questa materia mi sembra che sia inferiore a STATISTICS.
Quindi cominciamo.