Y a-t-il un modèle dans ce chaos ? Essayons de le trouver ! Apprentissage automatique sur l'exemple d'un échantillon spécifique. - page 25
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
À TP=SL, il sera d'environ 50 %. A TP = 2*SL, il sera de 33%, etc.
Le bénéfice moyen d'une transaction est toujours très faible. Environ 0,00005. Mais il sera dépensé en spread, slippage, swap, qui ne sont pas pris en compte dans le markup du professeur (le spread est pris en compte, mais le minimum par barre, le réel sera plus élevé).
Et ceci en utilisant TP=SL=0,00400. C'est-à-dire qu'avec un risque de 400 nous obtenons un profit de 5 pts, soit l'avantage de 1%.
J'aimerais prendre au moins 10 pts sur le mouvement de 50 pts, mais là toutes les options sont plum.
Mais c'est tout avec mes jetons et mes objectifs. Il y a peut-être de meilleures options.
Cette stratégie donne 43% de trades rentables sur l'EURUSD de 2008 à 2023, avec un ratio TP/SL de 61,8, et 39% des trades rentables sont suffisants pour atteindre le seuil de rentabilité. Je n'ai pas encore vérifié les chiffres, je peux me tromper quelque part, et il s'agit bien sûr de conditions idéales. Cependant, il y a une perspective d'apprentissage ici, ce qui signifie que vous pouvez tirer un pourcentage plus élevé au détriment du MO.
En ce qui concerne les prédicteurs, avez-vous pris mes prédicteurs dans mon article ? On les retrouve souvent dans les modèles que j'ai, entre autres.
Ajouté : Oui, je n'ai pas pris en compte le fait qu'il y a des trades rentables, mais qui ne sont pas fermés par le TP, et il y aura moins de profit bien sûr.Cette stratégie donne 43% de trades rentables sur l'EURUSD de 2008 à 2023, avec un ratio TP/SL de 61,8 dans des conditions idéales, et 39% des trades rentables sont suffisants pour atteindre le seuil de rentabilité. Je n'ai pas encore vérifié les chiffres, je peux me tromper quelque part, et il s'agit bien sûr de conditions idéales. Cependant, il y a une perspective d'apprentissage ici, ce qui signifie que vous pouvez obtenir un pourcentage plus élevé au détriment du MO.
En ce qui concerne les prédicteurs, avez-vous pris mes prédicteurs dans mon article ? Ils se retrouvent souvent dans les modèles que j'ai, entre autres.
Je ne sais pas vraiment quelle est votre stratégie. Il semble que vous receviez un signal pour entrer une fois par jour. Je pense qu'il est très limité de parler de la signification statistique des résultats.
J'ai entraîné vos plus de 5000 prédicteurs sur votre ensemble de données. Ils ne donnent pas plus de 5 points, donc je pense qu'ils ne sont pas meilleurs que mes simples deltas de prix et zigzags, qui donnent également 5 points.
Je vais vérifier d'autres idées pour l'instant. Si elles ne donnent rien, j'essaierai vos prédicteurs pour générer mon propre modèle.
Je ne comprends pas vraiment votre stratégie. Elle ressemble à un signal d'entrée une fois par jour.
La stratégie est la suivante :
A l'ouverture de la journée, nous calculons la fourchette limite attendue du mouvement des prix, pour cela nous pouvons utiliser l'ATR(3) à la fin de la dernière journée, j'utilise une formule légèrement différente. Nous reportons cette fourchette à partir du début de l'ouverture de la journée en cours (barre) - nous la considérons comme étant de 100%.
Lorsque l'on atteint un niveau significatif au-dessus/au-dessous de l'ouverture (je me suis arrêté à 23,6 comme cela se produit souvent sur différents instruments selon mes observations), on ouvre une position avec TP sur le prochain niveau significatif (j'utilise 61,8), et on met SL sur le prix d'ouverture de la journée.
Si on a clôturé au take profit, on entre à nouveau lorsqu'un signal apparaît.
Il est préférable de clôturer à la fin de la journée (23:45) si les take-outs n'ont pas fonctionné, mais en fait j'attends le TP/SL.
Maintenant, la majoration initiale fonctionne comme suit - si nous avons clôturé en profit, nous mettons 1, si nous avons clôturé en perte -1.
Lors de la division de l'échantillon, j'ai décalé l'objectif de 300 pips, donc si le profit est inférieur à 300 pips, c'est zéro.
Je pense que c'est très peu pour parler de la signification statistique des résultats.
J'ai pris les données de 2008. Oui, il n'y a pas beaucoup de données, mais cela dépend de la façon dont vous le regardez, parce que si vous considérez que le niveau de 23,6 n'est pas aléatoire et que son franchissement est significatif pour le marché, alors ce sera comme des événements similaires qui peuvent être comparés les uns aux autres, contrairement à la situation lors de la génération d'entrées sur chaque barre - il y a beaucoup d'événements similaires, ce qui ne fait que compliquer l'apprentissage.
Je pense donc qu'il est logique de s'entraîner de cette manière, mais les événements qui influencent la décision des participants au marché doivent être différents selon les stratégies. De plus, il est possible d'échanger des ensembles de modèles.
J'ai entraîné vos plus de 5000 prédicteurs sur votre ensemble de données. Ils ne donnent pas plus de 5 points, donc je pense qu'ils ne sont pas meilleurs que mes simples deltas de prix et zigzags, qui donnent également 5 points.
Je vais vérifier d'autres idées pour l'instant. Si elles ne donnent rien, j'essaierai vos prédicteurs pour générer mon propre modèle.
Parlez-vous du premier ou du deuxième échantillon ? S'il s'agit du premier, j'avais une matrice d'espérance d'environ 30 points pour les bonnes variantes.
Je peux essayer d'entraîner votre échantillon sur CatBoost, si vous le téléchargez, bien sûr.
Voici la stratégie :
A l'ouverture de la journée, nous calculons la fourchette limite attendue du mouvement des prix, pour cela nous pouvons utiliser l'ATR(3) à la fin de la dernière journée, j'utilise une formule légèrement différente. Nous reportons cette fourchette au début de l'ouverture de la journée en cours (barre) - nous la considérons comme étant de 100%.
Lorsque nous atteignons un niveau significatif au-dessus/en dessous de l'ouverture (je me suis arrêté à 23,6 car cela s'avère souvent être le cas sur différents instruments selon mes observations), nous ouvrons une position avec TP sur le prochain niveau significatif (j'utilise 61,8), et mettons SL sur le prix d'ouverture de la journée.
Si nous avons clôturé au take profit, nous entrons à nouveau lorsqu'un signal apparaît.
Il est préférable de clôturer en fin de journée (23:45) si les take-outs n'ont pas fonctionné, mais en fait j'attends le TP/SL maintenant.
Maintenant, la majoration initiale fonctionne comme suit - si nous avons clôturé en profit, nous mettons 1, si nous avons clôturé en perte -1.
Lors de la division de l'échantillon, j'ai décalé l'objectif de 300 pips, donc si le profit est inférieur à 300 pips, c'est zéro.
J'ai pris des données de 2008. Oui, il n'y a pas beaucoup de données, mais cela dépend de la façon dont vous regardez les choses, car si nous considérons que le niveau de 23,6 n'est pas accidentel et que son franchissement est significatif pour le marché, alors il s'agit d'événements similaires qui peuvent être comparés entre eux.
Maintenant, l'objectif est plus ou moins clair.
Avez-vous une estimation du résultat en pips ou simplement en gain/perte ? Il semble que ce soit cette dernière. Il est préférable d'estimer en pts.
Ainsi, le modèle qui donne 75 % ne fonctionne pas en fait à 50/50.
Contrairement à la situation où les entrées sont générées à chaque barre, il y a beaucoup d'événements de ce type, ce qui ne fait que compliquer l'apprentissage.
J'aimerais ajouter l'amincissement - des barres similaires, si le prix n'a pas augmenté de 100...1000 pts, alors sautez.
Parlez-vous du premier ou du deuxième échantillon ? Si vous parlez du premier, alors j'avais une matrice d'attente d'environ 30 pips pour les bonnes variantes.
Le second, sur H1, n'était pas meilleur (mais j'ai fait moins de recherches, je n'ai pas sélectionné de caractéristiques, par exemple).
Je peux essayer d'entraîner votre échantillon sur CatBoost, si vous le téléchargez, bien sûr.
J'en ai des centaines. Et je n'aime aucun d'entre eux à mettre dans le commerce. Je change le TP ou le SL ou autre chose - c'est une nouvelle variante. Ce n'est donc pas la peine.
Maintenant, l'objectif est plus ou moins clair.
Avez-vous une estimation du résultat en termes de points ou simplement de victoire ou de défaite ? Il semble que ce soit cette dernière. Il est préférable d'estimer le résultat en points.
Ainsi, un modèle à 75 % ne fonctionne pas vraiment à 50/50.
J'ai une évaluation en argent :) Plus la cible, comme c'était le cas auparavant. L'objectif peut être déplacé plus tard, si vous voulez plus de points.
Dans la stratégie spécifique maintenant tout est take profit. J'ai fait un lot calculé, en fait il s'est avéré que le spread aggrave la proportion de manière significative, mais c'est bien, mais il y aura une stabilité sans émissions d'entrées super rentables - le risque est presque le même partout. Si vous utilisez ensuite les pauses, vous pourrez améliorer le résultat.
J'aimerais ajouter l'amincissement - des barres similaires, si le prix n'a pas augmenté de 100...1000 pts, alors sautez.
Et ensuite évaluer sur chaque barre, quel modèle appliquer ?
Le deuxième sur H1. Bon, le premier n'était pas mieux, (mais j'ai moins cherché, je n'ai pas sélectionné les chips par exemple).
J'en ai des centaines. Et je n'aime en mettre aucune dans le trade. Je change le TP ou le SL ou autre chose - c'est une nouvelle variante. Il n'y a donc aucun intérêt.
Ce que je veux dire, c'est que s'il existe le même algorithme pour créer un échantillon, il sera possible de comparer les prédicteurs.
Et ensuite d'estimer à chaque barre, bien le modèle à appliquer ?
Oui, si au moins XX pips se sont écoulés, comme à l'entraînement. Mais il y aura des distorsions - seules les premières barres de 100 à 120 (200-220, etc.) si elles sont en hausse et 999-979 (899-979) fonctionneront plus souvent.
Ce que je veux dire, c'est que s'il existe le même algorithme pour créer un échantillon, il sera possible de comparer les prédicteurs.
Je ne veux pas vraiment plus de 5000, cela prendrait beaucoup de temps à compter. Mais dans le cadre d'une recherche de prédicteurs significatifs, il peut être nécessaire de les vérifier.
Bonjour !
J'ai une approche qui peut résoudre ce problème, mais il est préférable que les fichiers d'échantillons soient sans prédicteurs. En d'autres termes, il n'est pas nécessaire de disposer de plus de 5000 prédicteurs, mais seulement du graphique de mouvement lui-même. Il n'est pas important de savoir s'il s'agit d'OHLC ou d'une seule variable. Cependant, j'ai essayé la méthode existante sur une variable de l'échantillon, à savoir la colonne 5584, que j'ai convertie en graphique à l'aide de la formule D(i)=D(i-1)+ Target_100_Buy . Pour les trois fichiers, j'ai obtenu les graphiques suivants :
1) train :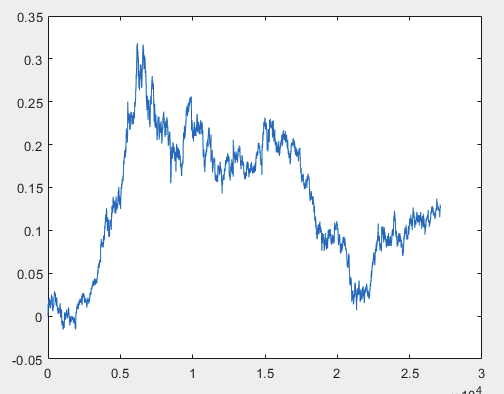
2) test :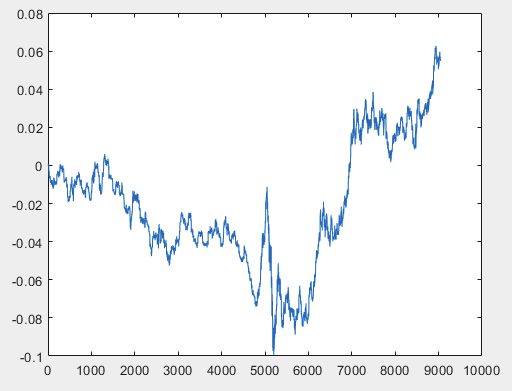
3) examen :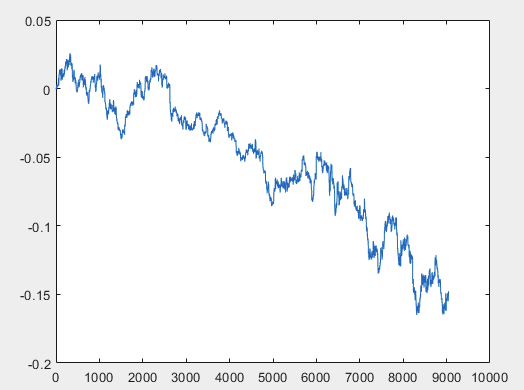
Je ne sais pas si je l'ai fait correctement ou non, mais si le topikstarter fait de nouveaux échantillons sans prédicteurs, je testerai la méthode sur de nouvelles données et je vous parlerai de l'approche.
Bien, et le bénéfice réel pour chacun des échantillons après l'entraînement du comité de réseaux neuronaux (il y en a 10 au total). Le profit est exprimé en nombre de points, avec spread=0 et commission=0 :
1) entraînement :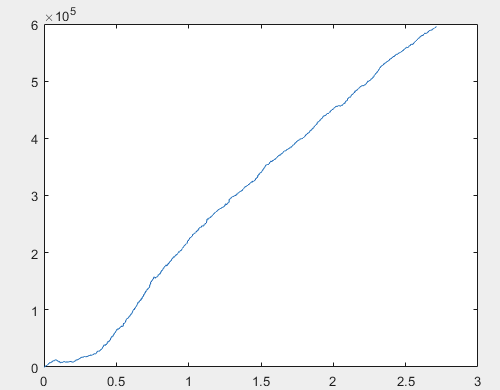
2) test :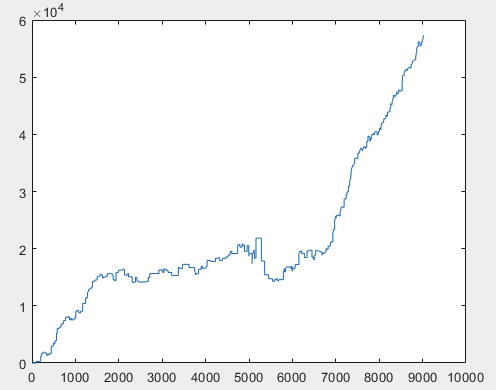
3) examen :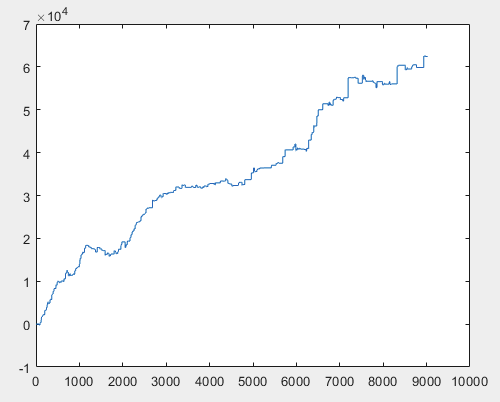
Je pense que le résultat de 60000+ pips est tout à fait acceptable.
Je suggère au topikstarter de faire de nouveaux échantillons, uniquement du signal le plus "chaotique".
La méthode sera appliquée au nouveau signal et les résultats seront montrés, ainsi que l'approche sera décrite dans une certaine mesure.
Salutations, RomFil !
P.S. L'avenir n'est pas connu, mais on peut toujours trouver une méthode pour le contrôler... :)
Bonjour !
J'ai une approche qui peut résoudre ce problème, mais il est préférable que les fichiers d'échantillons soient sans prédicteurs. En d'autres termes, il n'est pas nécessaire de disposer de plus de 5000 prédicteurs, mais seulement du graphique de mouvement lui-même. Il n'est pas important de savoir s'il s'agit d'OHLC ou d'une seule variable. Toutefois, j'ai essayé la méthode existante sur une variable de l'échantillon, à savoir la colonne 5584, que j'ai convertie en graphique à l'aide de la formule D(i)=D(i-1)+ Target_100_Buy . Pour les trois fichiers, les graphiques sont les suivants :
Je ne comprends pas ce que vous avez fait et pourquoi un nouvel échantillon est nécessaire si votre approche fonctionne avec des prix purs.
Les colonnes de la liste ci-dessous sont le résultat de l'événement qui s'est produit, c'est-à-dire qu'elles ne devraient pas participer à la formation. Au maximum 5582 - mais là, je pense qu'il est facile à prédire, donc il sera récupéré par le modèle tel quel.
5581 Auxiliaire
5582 Auxiliaire
5583 Étiquette
5584 Auxiliaire
5585 Auxiliaire
Je ne comprends pas ce que vous avez fait et pourquoi un nouvel échantillon est nécessaire si votre approche fonctionne avec des prix purs.
Les colonnes de la liste ci-dessous sont le résultat d'un événement qui s'est produit, c'est-à-dire qu'elles ne devraient pas participer à l'entraînement. Au maximum 5582 - mais je pense qu'il est facile à prédire, donc il sera récupéré par le modèle.
5581 Auxiliaire
5582 Auxiliaire
5583 Étiquette
5584 Auxiliaire
5585 Auxiliaire
"Qu'est-ce que j'ai fait ?
Le train d'échantillons a une taille d'environ 1 Go. Il faut beaucoup de temps pour le charger dans l'espace de travail. J'ai un i5-3570 avec 24 Go de RAM et un SSD rapide et il faut plusieurs minutes à Excel pour ouvrir ce fichier. C'est pourquoi j'ai décidé de le raccourcir. J'étais trop paresseux pour trouver les exposants pour plus de 5000 colonnes. J'ai pris la colonne 5584 5586 et j'ai appliqué un signal à toutes les lignes, par exemple BUY (honnêtement, je ne me souviens pas lequel, peut-être SELL). Ainsi, cette colonne a formé un graphique selon la formule ci-dessus. C'est-à-dire que la première étape était zéro, puis 0,00007, puis 0,00007-0,00002=0,00005, puis 0,00005+0,00007=0,00012, etc. C'est-à-dire qu'à partir de la colonne 5584 5586, j'ai formé un graphique de mouvement sans contrainte, pour ainsi dire un graphique de mouvement relatif. Comme s'il s'agissait d'un graphique de clôture, c'est-à-dire qu'à la fin de chaque étape du graphique, le prix de l'actif change de la valeur correspondante.
P.S. J'ai triché sur le nombre de colonnes... J'ai pris le 5586 le plus récent (je viens de le chercher dans Excel) avec le signal SELL.
"... pourquoi un nouvel échantillon" :
Pour montrer et raconter dans une certaine mesure l'approche sur son exemple. Si vous nommez les nombres de colonnes où vous pouvez prendre des prix OHLC ou juste des prix Clause, ce sera suffisant.
Pour le reste :
Les données des fichiers d'exemple ne sont pas du tout utilisées. Sur la base des colonnes 5584 5586 de chaque fichier, un graphique est créé comme décrit ci-dessus. Et l'approche est déjà appliquée à ces graphiques obtenus.
Bon, comme le topikstarter ne veut pas donner de nouveaux échantillons, je suggère à toute personne intéressée de poster les siens ... :)
Salutations, RomFil !
Bonjour !
J'ai une approche qui peut résoudre ce problème, mais il est préférable que les fichiers d'échantillons soient sans prédicteurs. En d'autres termes, il n'est pas nécessaire de disposer de plus de 5000 prédicteurs, mais seulement du graphique de mouvement lui-même. Il n'est pas important de savoir s'il s'agit d'OHLC ou d'une seule variable. Cependant, j'ai essayé la méthode existante sur une variable de l'échantillon, à savoir la colonne 5584, que j'ai convertie en graphique à l'aide de la formule D(i)=D(i-1)+ Target_100_Buy . Pour les trois fichiers, les graphiques sont les suivants :
La répétabilité de la fonction cible est entraînée ? Par exemple, si elle a réussi 20 fois, réussira-t-elle 21 fois ?
Combien de valeurs entrez-vous comme prédicteurs ?
Voici les cibles les plus simples pour l'achat et la vente avec TP/SL=50 pts
M5 pour environ 5 ans.
La majoration est sur chaque barre M5, c'est-à-dire qu'il est très probable que le trade du dernier signal (il y a 5 min) n'est pas encore terminé. Je ne suis pas sûr qu'il soit correct de les empiler. L'empilement serait acceptable pour un objectif avec seulement une transaction à un moment donné - même 100 transactions en même temps peuvent ne pas être terminées du jour au lendemain.
P.S. - Ils ne sont pas entraînables. Ils échouent toujours sur mon ensemble de prédicteurs.