
Les bases de la programmation MQL5 : Listes

Introduction
La nouvelle version du langage MQL a fourni aux développeurs de systèmes de trading automatisés des outils efficaces pour la mise en œuvre de tâches complexes. On ne peut nier le fait que les fonctionnalités de programmation du langage ont été considérablement étendues. Les fonctionnalités MQL5 OOP à elles seules valent beaucoup. De plus, la bibliothèque standard ne doit pas être ignorée. À en juger par le numéro de code d'erreur 359, les modèles de classe seront bientôt pris en charge.
Dans cet article, je voudrais évoquer ce qui peut être en quelque sorte une extension ou une continuation des sujets décrivant les types de données et leurs ensembles. Ici, je voudrais faire référence à un article publié sur le site MQL5.community. Une description très détaillée des principes et de la logique du travail avec les tableaux a été fournie par Dmitry Fedoseev (Entier) dans son article « Les bases de la programmation MQL5 : Tableaux ».
Alors, aujourd'hui je propose de me tourner vers les listes, et plus précisément, vers les listes linéaires liées. Nous allons commencer par la structure de la liste, la signification et la logique. Après cela, nous examinerons les outils connexes déjà disponibles dans la bibliothèque standard. En conclusion, je vais fournir des exemples de la façon dont les listes peuvent être utilisées lorsque vous travaillez avec MQL5.
- Concept de liste et de nœud : Théorie
- 1.1 Nœud dans une liste à liens simples
- 1.2 Nœud dans une liste à double chaînage
- 1.3 Nœud dans une liste circulaire à double chaînage
- 1.4 Principales opérations de liste
- Concept de liste et de nœud : La programmation
- 2.1 Nœud dans une liste à chaînage simple
- 2.2 Nœud dans une liste à double chaînage
- 2.3 Nœud dans une liste à double chaînage déroulée
- 2.4 Liste à chaînage simple
- 2.5 Liste à double chaînage
- 2.6 Liste à double chaînage déroulée
- 2.7 Liste circulaire à double chaînage
- Listes dans la bibliothèque standard MQL5
- Exemples d'utilisation de listes dans MQL5
1. Concept de liste et de nœud : Théorie
Alors, qu'est-ce qu'une liste pour un développeur et comment s'y prendre ? Je vais faire référence à la source publique d'information, Wikipedia, pour une définition générique de ce terme :
En informatique, une liste est un type de données abstrait qui implémente une collection ordonnée finie de valeurs, où la même valeur peut apparaître plusieurs fois. Une instance d'une liste est une représentation informatique du concept mathématique d'une séquence finie - un tuple. Chaque instance d'une valeur dans la liste est généralement appelée un élément, une entrée ou un élément de la liste ; si la même valeur apparaît plusieurs fois, ceci est considérée comme un élément distinct.
Le terme « liste » est également utilisé pour plusieurs structures concrètedata structures qui peuvent être utilisées pour implémenter des listes abstraites, en particulier les listes liées.
Je pense que vous conviendrez que cette définition est un peu trop savante.
Pour les besoins de cet article, nous nous intéressons davantage à la dernière phrase de cette définition. Attardons-nous donc dessus :
En informatique, une liste chaînée est une structure dynamique de basestructure de données composée de nœuds, où chaque nœud est composé de données et une ou deux références (« liens ») vers le nœud suivant et/ou précédent de la liste.[1] Le principal l'avantage d'une liste tableau est une flexibilité structurelle : la séquence des éléments de la liste chaînée n'a pas besoin de correspondre à la séquence des éléments de données dans la mémoire de l'ordinateur, tandis que les liens internes des éléments de la liste sont toujours conservés pour le parcours de la liste.
Essayons de l'examiner étape par étape.
En informatique, une liste en elle-même est un type de données. Nous l'avons établi. Il s'agit plutôt d'un type de données synthétique car il inclut d'autres types de données. Une liste est un peu similaire à un tableau. Si un tableau de données de type unique était un jour classé comme un nouveau type de données, ce serait une liste. Mais pas tout à fait.
Le principal avantage d'une liste est qu'elle permet l'insertion ou la suppression de nœuds à n'importe quel point de la liste, selon les besoins. Ici, la liste est similaire à un tableau dynamique, sauf que pour une liste, vous n'avez pas besoin d'utiliser la fonction ArrayResize() tout le temps.
En termes d'ordre des éléments de mémoire, les nœuds de liste ne sont pas stockés et n'ont pas besoin d'être stockés de la même manière que les éléments de tableau sont stockés dans des zones de mémoire adjacentes.
Et c'est plus ou moins tout. Aller plus loin dans la liste.
1.1 Nœud dans une liste à liens simples
Les listes vous permettent de stocker des nœuds, au lieu d'éléments. Le nœud est un type de données composé de deux parties.
La première partie est un champ de données et la seconde partie est utilisée pour les liens avec d'autres nœuds (Fig. 1). Le premier nœud de la liste est appelé « tête » et le dernier nœud de la liste est appelé « queue ». Le champ de lien de queue contient une référence NULL. Il est essentiellement utilisé pour indiquer le manque de nœuds supplémentaires dans la liste. D'autres sources spécialisées se réfèrent au reste de la liste après la tête comme « queue ».

Fig. 1 Nœuds dans une liste à chaînage simple
Outre les nœuds de liste à chaînage simple, il existe d'autres types de nœuds. Un nœud dans une liste à double chaînage est peut-être le plus courant.
1.2 Nœud dans une liste à double chaînage
Nous aurons également besoin d'un nœud qui répondra aux besoins d'une liste à double chaînage. Il diffère du type précédent en ce qu'il contient un autre lien pointant vers le nœud précédent. Et naturellement, le nœud de la tête de liste contiendra une référence NULL. Dans le schéma montrant la structure de la liste contenant de tels nœuds (Fig. 2), les liens pointant vers les nœuds précédents sont affichés sous forme de flèches rouges.

Fig. 2 Nœuds dans une liste à double chaînage
Ainsi, les capacités d'un nœud dans une liste à double chaînage seront similaires à celles d'un nœud de liste à chaînage simple. Vous aurez juste besoin de gérer un lien supplémentaire vers le nœud précédent.
1.3 Nœud dans une liste circulaire à double chaînage
Il existe des cas où les nœuds ci-dessus peuvent également être utilisés dans des listes non linéaires. Et bien que l'article décrive principalement des listes linéaires, je donnerai également un exemple de liste circulaire.

Fig. 3 Nœuds dans une liste circulaire à double chaînage
Le schéma d'une liste circulaire à double chaînage (Fig. 3) montre que les nœuds avec deux champs de liaison sont simplement liés circulairement. Cela se fait à l'aide des flèches orange et verte. Ainsi, le nœud de tête sera lié à la queue (comme l'élément précédent). Et le champ de lien du nœud de queue ne sera pas vide car il pointera vers la tête.
1.4 Principales opérations de liste
Comme indiqué dans la littérature spécialisée, toutes les opérations de liste peuvent être divisées en 3 groupes de base :
- Ajout (d'un nouveau nœud à la liste) ;
- Suppression (d'un nœud de la liste) ;
- Vérification (données d'un nœud).
Les méthodes d'ajout incluent :
- ajouter un nouveau nœud au début de la liste ;
- ajouter un nouveau nœud à la fin de la liste ;
- ajouter un nœud à la position spécifiée dans la liste ;
- ajouter un nœud à une liste vide ;
- constructeur paramétré.
Quant aux opérations de suppression, elles reflètent virtuellement les opérations correspondantes du groupe d'ajout :
- supprimer le nœud principal ;
- supprimer le nœud de fin;
- supprimer un nœud de la position spécifiée dans la liste ;
- destructeur.
Ici, je voudrais noter que le destructeur sert non seulement à achever et à terminer correctement l'opération de liste, mais également à supprimer correctement tous ses éléments.
Le troisième groupe de diverses opérations de vérification donne en fait accès à des nœuds ou des valeurs de nœud dans la liste :
- rechercher une valeur donnée ;
- vérifier que la liste est vide ;
- obtenir la valeur du ième nœud de la liste ;
- obtenir le pointeur vers le ième nœud de la liste ;
- obtenir la taille de la liste ;
- impression des valeurs des éléments de la liste.
En plus des groupes de base, je séparerais également le quatrième groupe de service. Il dessert les groupes précédents :
- opérateur d'assignation ;
- constructeur par copie
- travailler avec un pointeur dynamique ;
- copier la liste par valeurs ;
- tri.
C'est à peu près ça. Le développeur peut bien entendu étendre les fonctionnalités et les caractéristiques d'une classe de liste à tout moment, selon ses besoins.
2. Concept de liste et de nœud : La programmation
Dans cette partie, je suggère que nous procédions directement à la programmation des nœuds et des listes. Des illustrations du code seront fournies, le cas échéant.
2.1 Nœud dans une liste à chaînage simple
Jetons les bases de la classe de nœuds (Fig. 4) répondant aux besoins d'une liste chaînée singulièrement. Vous pouvez vous familiariser avec la notation des diagrammes de classes (modèle) dans l'article intitulé «Comment développer un Expert Advisor à l'aide des outils UML» (voir Fig. 5. modèle UML de la classe CTradeExpert).

Fig. 4 Modèle de classe CiSingleNode
Essayons maintenant de travailler avec le code. Il est basé sur l'exemple fourni dans le livre d’Art Friedman et autres auteurs. «Archives annotées C/C++».
//+------------------------------------------------------------------+ //| CiSingleNode class | //+------------------------------------------------------------------+ class CiSingleNode { protected: int m_val; // data CiSingleNode *m_next; // pointer to the next node public: void CiSingleNode(void); // default constructor void CiSingleNode(int _node_val); // parameterized constructor void ~CiSingleNode(void); // destructor void SetVal(int _node_val); // set-method for data void SetNextNode(CiSingleNode *_ptr_next); // set-method for the next node virtual void SetPrevNode(CiSingleNode *_ptr_prev){}; // set-method for the previous node virtual CiSingleNode *GetPrevNode(void) const {return NULL;}; // get-method for the previous node CiSingleNode *GetNextNode(void) const; // get-method for the next node int GetVal(void){TRACE_CALL(_t_flag) return m_val;} // get-method for data };
Je ne vais pas expliquer chaque méthode de la classe CiSingleNode. Vous pourrez les regarder de plus près dans le fichier CiSingleNode.mqh ci-joint. Cependant, je voudrais attirer votre attention sur une nuance intéressante. La classe contient des méthodes virtuelles qui fonctionnent avec les nœuds précédents. Ce sont en fait des mannequins et leur présence est plutôt à des fins de polymorphisme pour les futurs descendants.
Le code utilise la directive de préprocesseur TRACE_CALL(f) requise pour tracer les appels de chaque méthode utilisée.
#define TRACE_CALL(f) if(f) Print("Calling: "+__FUNCSIG__);
Avec seulement la classe CiSingleNodedisponible, vous êtes en mesure de créer une liste à chaînage unique. Laissez-moi vous donner un exemple de code.
//=========== Example 1 (processing the CiSingleNode type ) CiSingleNode *p_sNodes[3]; // #1 p_sNodes[0]=NULL; srand(GetTickCount()); // initialize a random number generator //--- create nodes for(int i=0;i<ArraySize(p_sNodes);i++) p_sNodes[i]=new CiSingleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_sNodes)-1);j++) p_sNodes[j].SetNextNode(p_sNodes[j+1]); // #3 //--- check values for(int i=0;i<ArraySize(p_sNodes);i++) { int val=p_sNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_sNodes)-1);j++) { CiSingleNode *p_sNode_next=p_sNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_sNodes);i++) delete p_sNodes[i]; // #12
Dans la chaîne #1, nous déclarons un tableau de pointeurs vers des objets de type CiSingleNode. Dans la chaîne #2, le tableau est rempli avec les pointeurs créés. Pour les données de chaque nœud, nous prenons un entier pseudo-aléatoire compris entre 0 et 32767 en utilisant la fonction rand(). Les nœuds sont liés au pointeur suivant dans la chaîne #3. Dans les chaînes #4-5, nous vérifions les valeurs des nœuds, et dans les chaînes #9-11, nous vérifions les performances des liens. Les pointeurs sont supprimés dans la chaîne #12.
C'est ce qui a été imprimé dans le journal.
DH 0 23:23:10 test_nodes (EURUSD,H4) Node #1 value = 3335 KP 0 23:23:10 test_nodes (EURUSD,H4) Node #2 value = 21584 GI 0 23:23:10 test_nodes (EURUSD,H4) Node #3 value = 917 HQ 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #1 value = 21584 HI 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #2 value = 917
La structure de nœud résultante peut être représentée schématiquement comme suit (Fig. 5).
![Fig. 5 Liens entre les nœuds du tableau CiSingleNode *p_sNodes[3]](https://c.mql5.com/2/6/5__1.png "Fig. 5 Liens entre les nœuds du tableau CiSingleNode *p_sNodes[3]")
Fig. 5 Liens entre les nœuds du tableau CiSingleNode *p_sNodes[3]
Passons maintenant aux nœuds d'une liste à double chaînage.
2.2 Nœud dans une liste à double chaînage
Tout d'abord, nous devons revoir le fait qu'un nœud dans une liste à double chaînage est distinct en ce sens qu'il possède deux pointeurs : le pointeur du nœud suivant et le pointeur du nœud précédent. C'est-à-dire qu'en plus du lien du nœud suivant, vous devez ajouter un pointeur vers le nœud précédent à un nœud de liste à liaison unique.
Ce faisant, je propose d'utiliser l'héritage comme relation de classe. Ensuite, le modèle de classe pour un nœud dans une liste à double chaînage peut se présenter comme suit (Fig. 6).

Fig. 6 Modèle de classe CDoubleNode
Maintenant, il est temps de jeter un œil au code.
//+------------------------------------------------------------------+ //| CDoubleNode class | //+------------------------------------------------------------------+ class CDoubleNode : public CiSingleNode { protected: CiSingleNode *m_prev; // pointer to the previous node public: void CDoubleNode(void); // default constructor void CDoubleNode(int node_val); // parameterized constructor void ~CDoubleNode(void){TRACE_CALL(_t_flag)};// destructor virtual void SetPrevNode(CiSingleNode *_ptr_prev); // set-method for the previous node virtual CiSingleNode *GetPrevNode(void) const; // get-method for the previous node CDoubleNode };
Il existe très peu de méthodes supplémentaires - elles sont virtuelles et sont liées au travail avec le nœud précédent. La description complète de la classe est fournie dans CDoubleNode.mqh.
Essayons de créer une liste à double chaînage basée sur la classe CDoubleNode. Laissez-moi vous donner un exemple de code.
//=========== Example 2 (processing the CDoubleNode type) CiSingleNode *p_dNodes[3]; // #1 p_dNodes[0]=NULL; srand(GetTickCount()); // initialize a random number generator //--- create nodes for(int i=0;i<ArraySize(p_dNodes);i++) p_dNodes[i]=new CDoubleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { p_dNodes[j].SetNextNode(p_dNodes[j+1]); // #3 p_dNodes[j+1].SetPrevNode(p_dNodes[j]); // #4 } //--- check values for(int i=0;i<ArraySize(p_dNodes);i++) { int val=p_dNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_next=p_dNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- check prev-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_prev=p_dNodes[j+1].GetPrevNode(); // #12 int snode_prev_val=p_sNode_prev.GetVal(); // #13 Print("Prev-Node #"+IntegerToString(j+2)+ // #14 " value = "+IntegerToString(snode_prev_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_dNodes);i++) delete p_dNodes[i]; // #15
En principe, cela est similaire à la création d'une liste à chaînage simple, mais il y a quelques particularités. Notez comment le tableau de pointeurs p_dNodes[] est déclaré dans la chaîne #1. Le type de pointeurs peut être défini de manière identique pour la classe de base. Le principe du polymorphisme dans la chaîne #2 nous aidera à les reconnaître à l'avenir. Les nœuds précédents sont vérifiés dans les chaînes #12-14.
Les informations suivantes ont été ajoutées au journal.
GJ 0 16:28:12 test_nodes (EURUSD,H4) Node #1 value = 17543 IQ 0 16:28:12 test_nodes (EURUSD,H4) Node #2 value = 1185 KK 0 16:28:12 test_nodes (EURUSD,H4) Node #3 value = 23216 DS 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #1 value = 1185 NH 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #2 value = 23216 FR 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #2 value = 17543 LI 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #3 value = 1185
La structure de nœuds résultante peut être schématiquement représentée comme suit (Fig. 7) :
![Fig. 7 Liens entre les nœuds du tableau CDoubleNode *p_sNodes[3]](https://c.mql5.com/2/6/7.png "Fig. 7 Liens entre les nœuds du tableau CDoubleNode *p_sNodes[3]")
Fig. 7 Liens entre les nœuds du tableau CDoubleNode *p_sNodes[3]
Je suggère maintenant que nous considérions un nœud qui sera nécessaire pour créer une liste à double chaînage déroulée.
2.3 Nœud dans une liste à double chaînage déroulée
Pensez à un nœud qui contiendrait un membre de données qui, au lieu d'une valeur unique, est attribuable à l'ensemble du tableau, c'est-à-dire qu'il contient et décrit l'ensemble du tableau. Un tel nœud peut ensuite être utilisé pour créer une liste déroulée. J'ai décidé de ne fournir aucune illustration ici car ce nœud est exactement le même qu'un nœud standard dans une liste à double chaînage. La seule différence est que l'attribut 'data' encapsule l'ensemble du tableau.
Je vais à nouveau utiliser l'héritage. La classe CDoubleNodeservira de classe de base pour un nœud dans une liste à double liaison déroulée. Et le modèle de classe pour un nœud dans une liste à double chaînage déroulée se présentera comme suit (Fig. 8).

Fig. 8 Modèle de classe CiUnrollDoubleNode
La classe CiUnrollDoubleNode peut être définie à l'aide du code suivant :
//+------------------------------------------------------------------+ //| CiUnrollDoubleNode class | //+------------------------------------------------------------------+ class CiUnrollDoubleNode : public CDoubleNode { private: int m_arr_val[]; // data array public: void CiUnrollDoubleNode(void); // default constructor void CiUnrollDoubleNode(int &_node_arr[]); // parameterized constructor void ~CiUnrollDoubleNode(void); // destructor bool GetArrVal(int &_dest_arr_val[])const; // get-method for data array bool SetArrVal(const int &_node_arr_val[]); // set-method for data array };
Vous pouvez examiner chaque méthode plus en détail dans CiUnrollDoubleNode.mqh.
Considérons un constructeur paramétré comme exemple.
//+------------------------------------------------------------------+ //| Parameterized constructor | //+------------------------------------------------------------------+ void CiUnrollDoubleNode::CiUnrollDoubleNode(int &_node_arr[]) : CDoubleNode(ArraySize(_node_arr)) { ArrayCopy(this.m_arr_val,_node_arr); TRACE_CALL(_t_flag) }
Ici, en utilisant la liste d'initialisation, nous entrons la taille d'un tableau à une dimension dans le membre de données this.m_val.
Après cela, nous créons « manuellement » une liste à double chaînage déroulée et vérifions les liens qu'elle contient.
//=========== Example 3 (processing the CiUnrollDoubleNode type) //--- data arrays int arr1[],arr2[],arr3[]; // #1 int arr_size=15; ArrayResize(arr1,arr_size); ArrayResize(arr2,arr_size); ArrayResize(arr3,arr_size); srand(GetTickCount()); // initialize a random number generator //--- fill the arrays with pseudorandom integers for(int i=0;i<arr_size;i++) { arr1[i]=rand(); // #2 arr2[i]=rand(); arr3[i]=rand(); } //--- create nodes CiUnrollDoubleNode *p_udNodes[3]; // #3 p_udNodes[0]=new CiUnrollDoubleNode(arr1); p_udNodes[1]=new CiUnrollDoubleNode(arr2); p_udNodes[2]=new CiUnrollDoubleNode(arr3); //--- links for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { p_udNodes[j].SetNextNode(p_udNodes[j+1]); // #4 p_udNodes[j+1].SetPrevNode(p_udNodes[j]); // #5 } //--- check values for(int i=0;i<ArraySize(p_udNodes);i++) { int val=p_udNodes[i].GetVal(); // #6 Print("Node #"+IntegerToString(i+1)+ // #7 " value = "+IntegerToString(val)); } //--- check array values for(int i=0;i<ArraySize(p_udNodes);i++) { int t_arr[]; // destination array bool isCopied=p_udNodes[i].GetArrVal(t_arr); // #8 if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Node #"+IntegerToString(i+1)+ // #9 " array values = "+arr_str); } } //--- check next-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_next=p_udNodes[j].GetNextNode(); // #10 bool isCopied=p_udNode_next.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Next-Node #"+IntegerToString(j+1)+ " array values = "+arr_str); } } //--- check prev-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_prev=p_udNodes[j+1].GetPrevNode(); // #11 bool isCopied=p_udNode_prev.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Prev-Node #"+IntegerToString(j+2)+ " array values = "+arr_str); } } //--- delete nodes for(int i=0;i<ArraySize(p_udNodes);i++) delete p_udNodes[i]; // #12 }
La quantité de code est devenue légèrement plus importante. Cela est dû au fait que nous devons créer et remplir un tableau pour chaque nœud.
Le travail avec des tableaux de données commence dans la chaîne #1. Il est fondamentalement similaire à ce que nous avions dans les nœuds précédents considérés. C'est juste que nous devons imprimer les valeurs des données de chaque nœud pour l'ensemble du tableau (par exemple, la chaîne #9).
Voilà ce que j'ai :
IN 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 value = 15 NF 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 value = 15 CI 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 value = 15 FQ 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 EG 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 MK 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 RP 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #1 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 JD 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #2 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 EH 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #2 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 NN 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #3 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756
Je suggère que nous devrions tracer une ligne sous le travail avec des nœuds et passer directement aux définitions de classe de différentes listes. Les exemples 1 à 3 peuvent être trouvés dans le script test_nodes.mq5.
2.4 Liste à chaînage simple
Il est temps que nous fassions un modèle de classe d'une liste à chaînage unique à partir des principaux groupes d'opérations de liste (Fig. 9).

Fig. 9 Modèle de classe CiSingleList
Il est facile de voir que la classe CiSingleListutilise le nœud de type CiSingleNode. En parlant de types de relations entre classes, on peut dire que :
- la classe CiSingleListcontient la classeCiSingleNode (composition) ;
- la classe CiSingleListutilise les méthodes de la classe CiSingleNode(dépendance).
L'illustration des relations ci-dessus est fournie à la figure 10.

Fig. 10 Types de relations entre la classe CiSingleList et la classe CiSingleNode
Créons une nouvelle classe - CiSingleList. À l'avenir, toutes les autres classes de liste utilisées dans l'article seront basées sur cette classe. C'est pourquoi il est si «riche».
//+------------------------------------------------------------------+ //| CiSingleList class | //+------------------------------------------------------------------+ class CiSingleList { protected: CiSingleNode *m_head; // head CiSingleNode *m_tail; // tail uint m_size; // number of nodes in the list public: //--- constructor and destructor void CiSingleList(); // default constructor void CiSingleList(int _node_val); // parameterized constructor void ~CiSingleList(); // destructor //--- adding nodes void AddFront(int _node_val); // add a new node to the beginning of the list void AddRear(int _node_val); // add a new node to the end of the list virtual void AddFront(int &_node_arr[]){TRACE_CALL(_t_flag)}; // add a new node to the beginning of the list virtual void AddRear(int &_node_arr[]){TRACE_CALL(_t_flag)}; // add a new node to the end of the list //--- deleting nodes int RemoveFront(void); // delete the head node int RemoveRear(void); // delete the node from the end of the list void DeleteNodeByIndex(const uint _idx); // delete the ith node from the list //--- checking virtual bool Find(const int _node_val) const; // find the required value bool IsEmpty(void) const; // check the list for being empty virtual int GetValByIndex(const uint _idx) const; // value of the ith node in the list virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // get the ith node in the list virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list CiSingleNode *GetHeadNode(void) const; // get the head node CiSingleNode *GetTailNode(void) const; // get the tail node virtual uint Size(void) const; // list size //--- service virtual void PrintList(string _caption=NULL); // print the list virtual bool CopyByValue(const CiSingleList &_sList); // copy the list by values virtual void BubbleSort(void); // bubble sorting //---templates template<typename dPointer> bool CheckDynamicPointer(dPointer &_p); // template for checking a dynamic pointer template<typename dPointer> bool DeleteDynamicPointer(dPointer &_p); // template for deleting a dynamic pointer protected: void operator=(const CiSingleList &_sList) const; // assignment operator void CiSingleList(const CiSingleList &_sList); // copy constructor virtual bool AddToEmpty(int _node_val); // add a new node to an empty list virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" node from the end of the list virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int _val); // new "native" node virtual void CalcSize(void) const; // calculate the list size };
La définition complète des méthodes de classe est fournie dans CiSingleList.mqh.
Lorsque j'ai commencé à développer cette classe, il n'y avait que 3 membres de données et quelques méthodes. Mais comme cette classe servait de base à d'autres classes, j'ai dû ajouter plusieurs fonctions membres virtuelles. Je ne vais pas décrire ces méthodes en détail. Un exemple d'utilisation de cette classe de liste chaînée peut être trouvé dans le script test_sList.mq5.
S'il est exécuté sans l'indicateur de trace, les entrées suivantes apparaîtront dans le journal :
KG 0 12:58:32 test_sList (EURUSD,H1) =======List #1======= PF 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 RL 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 MD 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 DM 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 QE 0 12:58:32 test_sList (EURUSD,H1) KN 0 12:58:32 test_sList (EURUSD,H1) LR 0 12:58:32 test_sList (EURUSD,H1) =======List #2======= RE 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 DQ 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 GK 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 FP 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 KF 0 12:58:32 test_sList (EURUSD,H1) MK 0 12:58:32 test_sList (EURUSD,H1) PR 0 12:58:32 test_sList (EURUSD,H1) =======renewed List #2======= GK 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=11 JP 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=13 JI 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=14 CF 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=34 QL 0 12:58:32 test_sList (EURUSD,H1) Node #5, val=35 OE 0 12:58:32 test_sList (EURUSD,H1) Node #6, val=36 MR 0 12:58:32 test_sList (EURUSD,H1) Node #7, val=37 KK 0 12:58:32 test_sList (EURUSD,H1) Node #8, val=38 MS 0 12:58:32 test_sList (EURUSD,H1) Node #9, val=666 OF 0 12:58:32 test_sList (EURUSD,H1) QK 0 12:58:32 test_sList (EURUSD,H1)
Le script a rempli 2 listes liées individuellement, puis étendu et trié la deuxième liste.
2.5 Liste à double chaînage
Essayons maintenant de créer une liste à double chaînage basée sur la liste du type précédent. L'illustration du modèle de classe d'une liste à double chaînage est fournie sur la figure 11 :

Fig. 11 Modèle de classe CDoubleList
La classe descendante contient beaucoup moins de méthodes, tandis que les données membres sont totalement absentes. Vous trouverez ci-dessous la définition de la classe CDoubleList.
//+------------------------------------------------------------------+ //| CDoubleList class | //+------------------------------------------------------------------+ class CDoubleList : public CiSingleList { public: void CDoubleList(void); // default constructor void CDoubleList(int _node_val); // parameterized constructor void ~CDoubleList(void){}; // destructor virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list protected: virtual bool AddToEmpty(int _node_val); // add a node to an empty list virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" tail node virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int _node_val); // new "native" node };
La description complète des méthodes de la classe CDoubleList est fournie dans CDoubleList.mqh.
D'une manière générale, les fonctions virtuelles ne sont utilisées ici que pour répondre aux besoins du pointeur vers le nœud précédent qui n'existe pas dans les listes à chaînages unique.
Un exemple d'utilisation de la liste de type CDoubleListse trouve dans le script test_dList.mq5. Il montre toutes les opérations de liste courantes pertinentes pour ce type de liste. Le code du script contient une chaîne particulière :
CiSingleNode *_new_node=new CDoubleNode(666); // create a new node of CDoubleNode type
Il n'y a pas d'erreur car une telle construction est tout à fait acceptable dans les cas où le pointeur de classe de base décrit un objet de la classe descendante. C'est l'un des avantages de l'héritage.
En MQL5, ainsi qu'en С++, le pointeur vers la classe de base peut pointer vers l'objet de la sous-classe dérivée de cette classe de base. Mais l'inverse est invalide.
Si vous écrivez la chaîne comme suit :
CDoubleNode*_new_node=new CiSingleNode(666);
le compilateur ne rapportera pas d'erreur ou d'avertissement mais le programme s'exécutera jusqu'à ce qu'il atteigne cette chaîne. Dans ce cas, vous verrez un message concernant la mauvaise trans-typage des types référencés par les pointeurs. Étant donné que le mécanisme de liaison tardive n'intervient que lorsque le programme est en cours d'exécution, nous devons soigneusement considérer la hiérarchie des relations entre les classes.
Après avoir exécuté le script, le journal contiendra les entrées suivantes :
DN 0 13:10:57 test_dList (EURUSD,H1) =======List #1======= GO 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 IE 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 FM 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 KD 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 JL 0 13:10:57 test_dList (EURUSD,H1) DG 0 13:10:57 test_dList (EURUSD,H1) CK 0 13:10:57 test_dList (EURUSD,H1) =======List #2======= IL 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 KH 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 PR 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 MI 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 DO 0 13:10:57 test_dList (EURUSD,H1) FR 0 13:10:57 test_dList (EURUSD,H1) GK 0 13:10:57 test_dList (EURUSD,H1) =======renewed List #2======= PR 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=11 QI 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=13 QP 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=14 LO 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=34 JE 0 13:10:57 test_dList (EURUSD,H1) Node #5, val=35 HL 0 13:10:57 test_dList (EURUSD,H1) Node #6, val=36 FK 0 13:10:57 test_dList (EURUSD,H1) Node #7, val=37 DR 0 13:10:57 test_dList (EURUSD,H1) Node #8, val=38 FJ 0 13:10:57 test_dList (EURUSD,H1) Node #9, val=666 HO 0 13:10:57 test_dList (EURUSD,H1) JR 0 13:10:57 test_dList (EURUSD,H1)
Comme dans le cas d'une liste à liaison simple, le script a rempli la première liste (doublement liée), l'a copiée et transmise à la deuxième liste. Ensuite, il a augmenté le nombre de nœuds dans la deuxième liste, trié et imprimé la liste.
2.6 Liste à double chaînage déroulée
Ce type de liste est pratique car il vous permet de stocker non seulement une valeur mais un tableau entier.
Jetons les bases de la liste de type CiUnrollDoubleList(Fig. 12).

Fig. 12 Modèle de classe CiUnrollDoubleList
Comme ici nous allons traiter d'un tableau de données, nous devrons redéfinir les méthodes définies dans la classe de base indirecte CiSingleList.
Vous trouverez ci-dessous la définition de la classe CiUnrollDoubleList.
//+------------------------------------------------------------------+ //| CiUnrollDoubleList class | //+------------------------------------------------------------------+ class CiUnrollDoubleList : public CDoubleList { public: void CiUnrollDoubleList(void); // default constructor void CiUnrollDoubleList(int &_node_arr[]); // parameterized constructor void ~CiUnrollDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual void AddFront(int &_node_arr[]); // add a new node to the beginning of the list virtual void AddRear(int &_node_arr[]); // add a new node to the end of the list virtual bool CopyByValue(const CiSingleList &_udList); // copy by values virtual void PrintList(string _caption=NULL); // print the list virtual void BubbleSort(void); // bubble sorting protected: virtual bool AddToEmpty(int &_node_arr[]); // add a node to an empty list virtual void addFront(int &_node_arr[]); // add a new "native" node to the beginning of the list virtual void addRear(int &_node_arr[]); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" node from the beginning of the list virtual int removeRear(void); // delete the "native" node from the end of the list virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int &_node_arr[]); // new "native" node };
La définition complète des méthodes de classe est fournie dans CiUnrollDoubleList.mqh.
Exécutons le script test_UdList.mq5 pour vérifier le fonctionnement des méthodes de classe. Ici, les opérations de nœud sont similaires à celles utilisées dans les scripts précédents. Il faudrait peut-être dire quelques mots sur les méthodes de tri et d'impression. La méthode de tri trie les nœuds par nombre d'éléments de sorte que le nœud contenant le tableau de valeurs de la plus petite taille soit en tête de liste.
La méthode d'impression imprime une chaîne de valeurs de tableau contenues dans un certain nœud.
Après avoir exécuté le script, le journal possèdera les entrées suivantes :
II 0 13:22:23 test_UdList (EURUSD,H1) =======List #1======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 OO 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 GG 0 13:22:23 test_UdList (EURUSD,H1) GP 0 13:22:23 test_UdList (EURUSD,H1) GR 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 before sorting======= JO 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 CH 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CF 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 GD 0 13:22:23 test_UdList (EURUSD,H1) GQ 0 13:22:23 test_UdList (EURUSD,H1) LJ 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 after sorting======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CJ 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 II 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 MD 0 13:22:23 test_UdList (EURUSD,H1) MQ 0 13:22:23 test_UdList (EURUSD,H1)
Comme vous pouvez le voir, après avoir été triée, la liste udList2 a été imprimée en partant du nœud avec le plus petit tableau jusqu'au nœud contenant le plus grand tableau.
2.7 Liste circulaire à double chaînage
Bien que les listes non linéaires ne soient pas prises en compte dans cet article, je suggère que nous travaillions également avec elles. Comment vous pouvez lier circulairement des nœuds a déjà été montré ci-dessus (Fig. 3).
Créons un modèle de la classe CiCircleDoubleList (Fig. 13). Cette classe sera une classe descendante de la classe CDoubleList.

Fig. 13 Modèle de classe CiCircleDoubleList
Du fait que les nœuds de cette liste ont un caractère spécifique (la tête et la queue sont liées), presque toutes les méthodes de la classe de base source CiSingleListdevront être rendues virtuelles.
//+------------------------------------------------------------------+ //| CiCircleDoubleList class | //+------------------------------------------------------------------+ class CiCircleDoubleList : public CDoubleList { public: void CiCircleDoubleList(void); // default constructor void CiCircleDoubleList(int _node_val); // parameterized constructor void ~CiCircleDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual uint Size(void) const; // list size virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list virtual int GetValByIndex(const uint _idx) const; // value of the ith node in the list virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // get the ith node in the list virtual bool Find(const int _node_val) const; // find the required value virtual bool CopyByValue(const CiSingleList &_sList); // copy the list by values protected: virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" tail node virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list protected: void CalcSize(void) const; // calculate the list size void LinkHeadTail(void); // link head to tail };
La description complète de la classe est fournie dans CiCircleDoubleList.mqh.
Considérons quelques méthodes de la classe. La méthode CiCircleDoubleList::LinkHeadTail() relie le nœud de queue au nœud de tête. Il doit être appelé lorsqu'il y a une nouvelle queue ou une nouvelle tête et que le lien précédent est perdu.
//+------------------------------------------------------------------+ //| Linking head to tail | //+------------------------------------------------------------------+ void CiCircleDoubleList::LinkHeadTail(void) { TRACE_CALL(_t_flag) this.m_head.SetPrevNode(this.m_tail); // link head to tail this.m_tail.SetNextNode(this.m_head); // link tail to head }
Pensez à ce que serait cette méthode si nous avions affaire à une liste circulaire à chaînage simple.
Considérez, par exemple, la méthode CiCircleDoubleList::addFront().
//+------------------------------------------------------------------+ //| New "native" node to the beginning of the list | //+------------------------------------------------------------------+ void CiCircleDoubleList::addFront(int _node_val) { TRACE_CALL(_t_flag) CDoubleList::addFront(_node_val); // call a similar method of the base class this.LinkHeadTail(); // link head and tail }
Vous pouvez voir dans le corps de la méthode qu'une méthode similaire de la classe de base CDoubleListest appelée. À ce stade, nous pourrions terminer l'opération de méthode (la méthode en tant que telle n'est fondamentalement pas nécessaire ici), si ce n'était pour une chose. Le lien entre la tête et la queue est perdu et la liste ne peut pas être liée circulairement sans elle. C'est pourquoi nous devons appeler la méthode de lier la tête et la queue.
Le travail avec la liste circulaire à double chaînage est vérifié dans le script test_UdList.mq5.
En termes de tâches et d'objectifs, les autres méthodes utilisées sont les mêmes que dans les exemples précédents.
Par conséquent, le journal contient les entrées suivantes :
PR 0 13:34:29 test_CdList (EURUSD,H1) =======List #1======= QS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=14 QI 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=666 LQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=13 OH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=11 DP 0 13:34:29 test_CdList (EURUSD,H1) DK 0 13:34:29 test_CdList (EURUSD,H1) DI 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 before sorting======= MS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=38 IJ 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=37 IQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=36 EH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=35 EO 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=34 FF 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=14 DN 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=666 GD 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=13 JK 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=11 JM 0 13:34:29 test_CdList (EURUSD,H1) JH 0 13:34:29 test_CdList (EURUSD,H1) MS 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 after sorting======= LE 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=11 KL 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=13 QS 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=14 NJ 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=34 NQ 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=35 NH 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=36 NO 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=37 NF 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=38 JN 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=666 RJ 0 13:34:29 test_CdList (EURUSD,H1) RE 0 13:34:29 test_CdList (EURUSD,H1)
Ainsi, le schéma final de l'héritage entre les classes de liste introduites est le suivant (Fig. 14).
Je ne sais pas si toutes les classes doivent être liées par héritage, mais j'ai décidé de tout laisser tel quel.

Fig. 14 Héritage entre les classes de liste
Tirant la ligne sous cette section de l'article qui a traité de la description des listes personnalisées, je voudrais noter que nous avons à peine effleuré le groupe des listes non linéaires, des listes chaînées et autres. Au fur et à mesure que je collecte les informations pertinentes et que j'acquiers plus d'expérience en travaillant avec de telles structures de données dynamiques, j'essaierai d'écrire un autre article.
3. Listes dans la bibliothèque standard MQL5
Jetons un coup d'œil à la classe de liste disponible dans la bibliothèque standard (Fig. 15).
Il appartient aux classes de données.

Fig. 15 Modèle de classe CList
Curieusement, CListest un descendant de la classe CObject. C'est-à-dire que la liste hérite des données et des méthodes de la classe, qui est un nœud.
La classe de liste contient un ensemble impressionnant de méthodes. Pour être honnête, je ne m'attendais pas à trouver une si grande classe dans la bibliothèque standard.
La classe CList a 8 membres de données. Je voudrais souligner deux ou trois choses. Les attributs de classe contiennent l'index du nœud courant (int m_curr_idx) et le pointeur vers le nœud courant (CObject* m_curr_node). On peut dire que la liste est «intelligente» - elle peut indiquer l'endroit où le contrôle est localisé. De plus, il comporte un mécanisme de gestion de la mémoire (nous pouvons supprimer physiquement un nœud ou simplement l'exclure de la liste), un indicateur de liste triée et un mode de tri.
En parlant de méthodes, toutes les méthodes de la classe CListsont réparties dans les groupes suivants :
- Les attributs ;
- Créer des méthodes ;
- Ajouter des méthodes ;
- Supprimer les méthodes ;
- La navigation ;
- Méthodes d’ordre ;
- Comparer les méthodes ;
- Méthodes de recherche ;
- Entrée /sortie.
Comme d'habitude, il existe un constructeur et un destructeur standard.
Le premier vide (NULL) tous les pointeurs. L'état de l'indicateur de gestion de la mémoire est défini sur suppression. La nouvelle liste ne sera pas triée.
Dans son corps, le destructeur appelle uniquement la méthode Clear() pour vider la liste des nœuds. La fin de l'existence de la liste n'entraîne pas nécessairement la « mort » de ses éléments (nœuds). Ainsi, l'indicateur de gestion de la mémoire défini lors de la suppression des éléments de la liste fait passer la relation de classe de la composition à l'agrégation.
Nous pouvons gérer ce drapeau en utilisant les méthodes set- and get FreeMode().
Il existe deux méthodes dans la classe qui vous permettent d'étendre la liste : Ajouter() et Insérer(). La première est similaire à la méthode AddRear() utilisée dans la première section de l'article. La deuxième méthode est similaire à la méthode SetNodeByIndex().
Commençons par un petit exemple. Nous devons d'abord créer une classe de nœuds CNodeInt, un descendant de la classe d'interface CObject. Il stockera la valeur de type entier.
//+------------------------------------------------------------------+ //| CNodeInt class | //+------------------------------------------------------------------+ class CNodeInt : public CObject { private: int m_val; // node data public: void CNodeInt(void){this.m_val=WRONG_VALUE;}; // default constructor void CNodeInt(int _val); // parameterized constructor void ~CNodeInt(void){}; // destructor int GetVal(void){return this.m_val;}; // get-method for node data void SetVal(int _val){this.m_val=_val;}; // set-method for node data }; //+------------------------------------------------------------------+ //| Parameterized constructor | //+------------------------------------------------------------------+ void CNodeInt::CNodeInt(int _val):m_val(_val) { };
Nous allons travailler avec la liste CListdans le script test_MQL5_List.mq5.
L'exemple 1 montre une création dynamique de la liste et des nœuds. La liste est ensuite remplie de nœuds et la valeur du premier nœud est vérifiée avant et après la suppression de la liste.
//--- Example 1 (testing memory management) CList *myList=new CList; // myList.FreeMode(false); // reset flag bool _free_mode=myList.FreeMode(); PrintFormat("\nList \"myList\" - memory management flag: %d",_free_mode); CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("List \"myList\" has as many nodes as: %d",myList.Total()); Print("=======Before deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",p_new_nodes_int[0].GetVal()); delete myList; int val_to_check=WRONG_VALUE; if(CheckPointer(p_new_nodes_int[0])) val_to_check=p_new_nodes_int[0].GetVal(); Print("=======After deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",val_to_check);
Si la chaîne réinitialisant le drapeau reste commentée (inactive), nous obtiendrons les entrées suivantes dans le journal :
GS 0 14:00:16 test_MQL5_List (EURUSD,H1) EO 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 1 FR 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 JH 0 14:00:16 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= DO 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: 7189 KJ 0 14:00:16 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= QK 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: -1
Veuillez noter qu'après la suppression dynamique de la liste myList, tous les nœuds qu'elle contient ont également été supprimés de la mémoire.
Cependant, si nous décommentons la chaîne du drapeau de réinitialisation :
// myList.FreeMode(false); // reset flagla sortie vers le journal sera la suivante :
NS 0 14:02:11 test_MQL5_List (EURUSD,H1) CN 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 0 CS 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 KH 0 14:02:11 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= NL 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 HJ 0 14:02:11 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= LI 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 QQ 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 undeleted objects left DD 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 objects of type CNodeInt left DL 1 14:02:11 test_MQL5_List (EURUSD,H1) 400 bytes of leaked memory
Il est facile de remarquer que le nœud principal conserve sa valeur avant et après la suppression de la liste. Dans ce cas, il restera également des objets non supprimés si le script ne contient pas le code pour les supprimer correctement.
Essayons maintenant de travailler avec la méthode de tri.
//--- Example 2 (sorting) CList *myList=new CList; CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("\nList \"myList\" has as many nodes as: %d",myList.Total()); Print("=======List \"myList\" before sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } myList.Sort(0); Print("\n=======List \"myList\" after sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } delete myList;
Par conséquent, le journal contient les entrées suivantes :
OR 0 22:47:01 test_MQL5_List (EURUSD,H1) FN 0 22:47:01 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 FH 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" before sorting======= LG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 30511 CO 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 17404 GF 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 12215 KQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 31574 NJ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 7285 HP 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 23509 IH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 26991 NS 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 414 MK 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 18824 DR 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 1560 OR 0 22:47:01 test_MQL5_List (EURUSD,H1) OM 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" after sorting======= QM 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 26991 RE 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 23509 ML 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 18824 DD 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 414 LL 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 1560 IG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 17404 PN 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 30511 II 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 31574 OQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 12215 JH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 7285
Même si un tri a été fait, la technique de tri est restée un mystère pour moi. Je vais expliquer pourquoi. Sans entrer dans les détails de l'ordre d'appel, la méthode CList::Sort() appelle la méthode virtuelle CObject::Compare() qui n'est en aucun cas implémentée dans la classe de base. Ainsi, le programmeur doit gérer lui-même la mise en œuvre d'une méthode de tri.
Et maintenant, quelques mots sur la méthode Total(). Il renvoie le nombre d'éléments (nœuds) dont le membre de données m_data_total est responsable. C'est une méthode très courte et concise. Le nombre d'éléments dans cette implémentation sera beaucoup plus rapide que dans celui que j'ai proposé plus tôt. En effet, pourquoi à chaque fois parcourir la liste et compter les nœuds, alors que le nombre exact de nœuds dans la liste peut être défini lors de l'ajout ou de la suppression de nœuds.
L'exemple 3 compare la vitesse de remplissage des listes de type CListet CiSingleListet calcule le temps nécessaire pour obtenir la taille de chaque liste.
//--- Example 3 (nodes number) int iterations=1e7; // 10 million iterations //--- the new CList CList *p_mql_List=new CList; uint start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) { CNodeInt *p_node_int=new CNodeInt(rand()); p_mql_List.Add(p_node_int); } uint time=GetTickCount()-start; // time spent, msec Print("\n=======the CList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); int list_size=p_mql_List.Total(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_mql_List; //--- the new CiSingleList CiSingleList *p_sList=new CiSingleList; start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) p_sList.AddRear(rand()); time=GetTickCount()-start; // time spent, msec Print("\n=======the CiSingleList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); list_size=(int)p_sList.Size(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_sList;
Voilà ce que j'ai dans l’historique :
KO 0 22:48:24 test_MQL5_List (EURUSD,H1) CK 0 22:48:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= JL 0 22:48:24 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2606 msec RO 0 22:48:24 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 0 msec LF 0 22:48:29 test_MQL5_List (EURUSD,H1) EL 0 22:48:29 test_MQL5_List (EURUSD,H1) =======the CiSingleList type list======= KK 0 22:48:29 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2356 msec NF 0 22:48:29 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 359 msec
La méthode pour obtenir la taille fonctionne instantanément dans la liste CList. Soit dit en passant, l'ajout de nœuds à la liste est également assez rapide.
Dans le bloc suivant (exemple 4), je suggère de prêter attention à l'un des principaux inconvénients de la liste en tant que conteneur de données - la vitesse d'accès aux éléments. Le fait est que les éléments de la liste sont accessibles de manière linéaire. Dans la classe CList, ils sont accessibles de manière binaire, ce qui diminue légèrement la pénibilité de l'algorithme.
Lors d'une recherche linéaire, la pénibilité est O(N). Une recherche implémentée de manière binaire entraîne la pénibilité de log2(N).
Voici un exemple de code pour accéder aux éléments d'un ensemble de données :
//--- Example 4 (speed of accessing the node) const uint Iter_arr[]={1e3,3e3,6e3,9e3,1e4,3e4,6e4,9e4,1e5,3e5,6e5}; for(uint i=0;i<ArraySize(Iter_arr);i++) { const uint cur_iterations=Iter_arr[i]; // iterations number uint randArr[]; // array of random numbers uint idxArr[]; // array of indexes //--- set the arrays size ArrayResize(randArr,cur_iterations); ArrayResize(idxArr,cur_iterations); CRandom myRand; // random number generator //--- fill the array of random numbers for(uint t=0;t<cur_iterations;t++) randArr[t]=myRand.int32(); //--- fill the array of indexes with random numbers (from 0 to 10 million) int iter_log10=(int)log10(cur_iterations); for(uint r=0;r<cur_iterations;r++) { uint rand_val=myRand.int32(); // random value (from 0 to 4 294 967 295) if(rand_val>=cur_iterations) { int val_log10=(int)log10(rand_val); double log10_remainder=val_log10-iter_log10; rand_val/=(uint)pow(10,log10_remainder+1); } //--- check the limit if(rand_val>=cur_iterations) { Alert("Random value error!"); return; } idxArr[r]=rand_val; } //--- time spent for the array uint start=GetTickCount(); //--- accessing the array elements for(uint p=0;p<cur_iterations;p++) uint random_val=randArr[idxArr[p]]; uint time=GetTickCount()-start; // time spent, msec Print("\n=======the uint type array======="); PrintFormat("Random accessing the array of elements %.1e has taken %d msec",cur_iterations,time); //--- the CList type list CList *p_mql_List=new CList; //--- fill the list for(uint q=0;q<cur_iterations;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_mql_List.Add(p_node_int); } start=GetTickCount(); //--- accessing the list nodes for(uint w=0;w<cur_iterations;w++) CNodeInt *p_node_int=p_mql_List.GetNodeAtIndex(idxArr[w]); time=GetTickCount()-start; // time spent, msec Print("\n=======the CList type list======="); PrintFormat("Random accessing the list of nodes %.1e has taken %d msec",cur_iterations,time); //--- free the memory ArrayFree(randArr); ArrayFree(idxArr); delete p_mql_List; }
Sur la base des résultats de l'opération de blocage, les entrées suivantes ont été imprimées dans le journal :
MR 0 22:51:22 test_MQL5_List (EURUSD,H1) QL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= IG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+003 has taken 0 msec QF 0 22:51:22 test_MQL5_List (EURUSD,H1) IQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= JK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+003 has taken 0 msec MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) QD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= GO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+003 has taken 0 msec QN 0 22:51:22 test_MQL5_List (EURUSD,H1) II 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= EP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+003 has taken 16 msec OR 0 22:51:22 test_MQL5_List (EURUSD,H1) OL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= FG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+003 has taken 0 msec CF 0 22:51:22 test_MQL5_List (EURUSD,H1) GQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CH 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+003 has taken 31 msec QJ 0 22:51:22 test_MQL5_List (EURUSD,H1) MD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= MO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+003 has taken 0 msec EN 0 22:51:22 test_MQL5_List (EURUSD,H1) MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+003 has taken 47 msec CR 0 22:51:22 test_MQL5_List (EURUSD,H1) KL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= JG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+004 has taken 0 msec GF 0 22:51:22 test_MQL5_List (EURUSD,H1) KR 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= MK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+004 has taken 343 msec GJ 0 22:51:22 test_MQL5_List (EURUSD,H1) GG 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= LO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+004 has taken 0 msec QO 0 22:51:24 test_MQL5_List (EURUSD,H1) MJ 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= NP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+004 has taken 1217 msec OS 0 22:51:24 test_MQL5_List (EURUSD,H1) KO 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the uint type array======= CP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+004 has taken 0 msec MG 0 22:51:26 test_MQL5_List (EURUSD,H1) ER 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the CList type list======= PG 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+004 has taken 2387 msec GK 0 22:51:26 test_MQL5_List (EURUSD,H1) OG 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the uint type array======= NH 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+004 has taken 0 msec JO 0 22:51:30 test_MQL5_List (EURUSD,H1) NK 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the CList type list======= KO 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+004 has taken 3619 msec HS 0 22:51:30 test_MQL5_List (EURUSD,H1) DN 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the uint type array======= RP 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+005 has taken 0 msec OD 0 22:52:05 test_MQL5_List (EURUSD,H1) GS 0 22:52:05 test_MQL5_List (EURUSD,H1) =======the CList type list======= DE 0 22:52:05 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+005 has taken 35631 msec NH 0 22:52:06 test_MQL5_List (EURUSD,H1) RF 0 22:52:06 test_MQL5_List (EURUSD,H1) =======the uint type array======= FI 0 22:52:06 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+005 has taken 0 msec HL 0 22:54:20 test_MQL5_List (EURUSD,H1) PD 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the CList type list======= FN 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+005 has taken 134379 msec RQ 0 22:54:20 test_MQL5_List (EURUSD,H1) JI 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the uint type array======= MR 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+005 has taken 15 msec NE 0 22:58:48 test_MQL5_List (EURUSD,H1) FL 0 22:58:48 test_MQL5_List (EURUSD,H1) =======the CList type list======= GE 0 22:58:48 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+005 has taken 267589 msec
Vous pouvez voir que l'accès aléatoire aux éléments de la liste prend plus de temps à mesure que la taille de la liste augmente (Fig. 16).

Fig. 16 Temps passé pour l'accès aléatoire aux éléments de tableau et de liste
Considérons maintenant les méthodes d'enregistrement et de chargement des données.
La classe de liste de base CListcontient de telles méthodes mais elles sont virtuelles. Ainsi, afin de tester leur fonctionnement à l'aide d'un exemple, nous devons nous préparer.
Nous devrions hériter des capacités de la classe CListen utilisant la classe descendante CIntList. Ce dernier n'aura qu'une seule méthode pour créer un nouvel élément CIntList::CreateElement().
//+------------------------------------------------------------------+ //| CIntList class | //+------------------------------------------------------------------+ class CIntList : public CList { public: virtual CObject *CreateElement(void); }; //+------------------------------------------------------------------+ //| New element of the list | //+------------------------------------------------------------------+ CObject *CIntList::CreateElement(void) { CObject *new_node=new CNodeInt(); return new_node; }
Nous devrons également ajouter les méthodes virtuelles CNodeInt::Save() et CNodeInt::Load() au type de nœud dérivé CNodeInt. Ils seront appelés à partir des fonctions membres CList::Save() et CList::Load(), respectivement.
En conséquence, l'exemple sera le suivant (exemple 5) :
//--- Example 5 (saving list data) //--- the CIntList type list CList *p_int_List=new CIntList; int randArr[1000]; // array of random numbers ArrayInitialize(randArr,0); //--- fill the array of random numbers for(int t=0;t<1000;t++) randArr[t]=(int)myRand.int32(); //--- fill the list for(uint q=0;q<1000;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_int_List.Add(p_node_int); } //--- save the list to the file int file_ha=FileOpen("List_data.bin",FILE_WRITE|FILE_BIN); p_int_List.Save(file_ha); FileClose(file_ha); p_int_List.FreeMode(true); p_int_List.Clear(); //--- load the list from the file file_ha=FileOpen("List_data.bin",FILE_READ|FILE_BIN); p_int_List.Load(file_ha); int Loaded_List_size=p_int_List.Total(); PrintFormat("Nodes loaded from the file: %d",Loaded_List_size); //--- free the memory delete p_int_List;
Après avoir exécuté le script sur le graphique, l'entrée suivante sera ajoutée au journal :
ND 0 11:59:35 test_MQL5_List (EURUSD,H1) As many as 1000 nodes loaded from the file.
Ainsi, nous avons vu la mise en œuvre de méthodes d'entrée/sortie pour une donnée membre de type nœud CNodeInt.
Dans la section suivante, nous verrons des exemples de la façon dont les listes peuvent être utilisées pour résoudre des problèmes lorsque vous travaillez avec MQL5.
4. Exemples d'utilisation de listes dans MQL5
Dans la section précédente, lors de l'examen des méthodes de la classe CListde la bibliothèque standard, j'ai donné quelques exemples.
Maintenant, je vais considérer les cas où la liste est utilisée pour résoudre un problème spécifique. Et ici, je ne peux que souligner une fois de plus l'avantage de la liste en tant que type de données de conteneur. Nous pouvons rendre le travail avec le code plus efficace en tirant parti de la flexibilité d'une liste.
4.1 Manipulation des objets graphiques
Imaginez que nous ayons besoin de créer par programmation des objets graphiques dans le graphique. Il peut s'agir de différents objets pouvant apparaître dans le graphique pour diverses raisons.
Je me souviens qu'une fois la liste m'a aidé à démêler une situation avec des objets graphiques. Et je voudrais partager ce souvenir avec vous.
J'avais pour tâche de créer des lignes verticales selon la condition spécifiée. Selon la condition, les lignes verticales servaient de limites pour un intervalle de temps donné dont la longueur variait au cas par cas. Cela dit, l'intervalle n'était pas toujours complètement formé.
J'étudiais le comportement d'EMA21 et pour cela devais collecter des statistiques.
J'étais particulièrement intéressé par la longueur de la pente de la moyenne mobile. Par exemple, dans un mouvement vers le bas, le point de départ a été identifié en enregistrant le mouvement négatif de la moyenne mobile (c'est-à-dire la diminution de la valeur) par lequel une ligne verticale a été tracée. La figure 17 montre un tel point identifié pour l'EURUSD, S1, le 5 septembre 2013 à 16h00, lors de l'ouverture d'un chandelier.

Fig. 17 Premier point de l'intervalle descendant
Le deuxième point suggérant la fin du mouvement à la baisse a été identifié sur la base du principe inverse - en enregistrant un mouvement positif de la moyenne mobile, c'est-à-dire une augmentation de la valeur (Fig. 18).

Fig. 18 Deuxième point de l'intervalle descendant
Ainsi, l'intervalle cible était du 5 septembre 2013 16h00 au 6 septembre 2013 17h00.
Le système d'identification des différents intervalles peut être plus complexe ou plus simple. La question n'est pas là Ce qui est important, c'est que cette technique de travail avec des objets graphiques et de collecte simultanée de données statistiques implique l'un des avantages majeurs de la liste - la flexibilité de la composition.
Comme pour l'exemple actuel, j'ai d'abord créé un nœud de type CVertLineNodequi est responsable de 2 «Lignes verticales» d’objets graphiques .
La définition de classe est la suivante :
//+------------------------------------------------------------------+ //| CVertLineNode class | //+------------------------------------------------------------------+ class CVertLineNode : public CObject { private: SVertLineProperties m_vert_lines[2]; // array of structures of vertical line properties uint m_duration; // frame duration bool m_IsFrameFormed; // flag of frame formation public: void CVertLineNode(void); void ~CVertLineNode(void){}; //--- set-methods void SetLine(const SVertLineProperties &_vert_line,bool IsFirst=true); void SetDuration(const uint _duration){this.m_duration=_duration;}; void SetFrameFlag(const bool _frame_flag){this.m_IsFrameFormed=_frame_flag;}; //--- get-methods void GetLine(SVertLineProperties &_vert_line_out,bool IsFirst=true) const; uint GetDuration(void) const; bool GetFrameFlag(void) const; //--- draw the line bool DrawLine(bool IsFirst=true) const; };
Fondamentalement, cette classe de nœuds décrit un cadre (interprété ici comme un nombre de chandeliers confinés dans deux lignes verticales). Les limites de trame sont représentées par quelques structures de propriétés de ligne verticale, de durée et de drapeau de formation.
Outre le constructeur et le destructeur standard, la classe a plusieurs méthodes set et get, ainsi que la méthode pour tracer la ligne dans le graphique.
Permettez-moi de vous rappeler que le nœud de lignes verticales (cadre) dans mon exemple peut être considéré comme formé lorsqu'il y a une première ligne verticale indiquant le début du mouvement descendant et la deuxième ligne verticale indiquant le début du mouvement ascendant.
À l'aide du script Stat_collector.mq5, j'ai affiché toutes les images du graphique et j'ai compté le nombre de nœuds (images) correspondant à une certaine limite de durée sur les 2 000 dernières barres.
Pour illustration, j'ai créé 4 listes pouvant contenir n'importe quel cadre. La première liste contenait des cadres avec un nombre de chandeliers jusqu'à 5, le second - jusqu'à 10, le troisième - jusqu'à 15 et le quatrième - un nombre illimité.
NS 0 15:27:32 Stat_collector (EURUSD,H1) =======List #1======= RF 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 5 ML 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 65 HK 0 15:27:32 Stat_collector (EURUSD,H1) OO 0 15:27:32 Stat_collector (EURUSD,H1) =======List #2======= RI 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 10 NP 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 15 RG 0 15:27:32 Stat_collector (EURUSD,H1) FH 0 15:27:32 Stat_collector (EURUSD,H1) =======List #3======= GN 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 15 FG 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 6 FR 0 15:27:32 Stat_collector (EURUSD,H1) CD 0 15:27:32 Stat_collector (EURUSD,H1) =======List #4======= PS 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 20
En conséquence, j'ai obtenu le graphique suivant (Fig. 19). Pour plus de commodité, la deuxième ligne de cadre verticale est affichée en bleu.
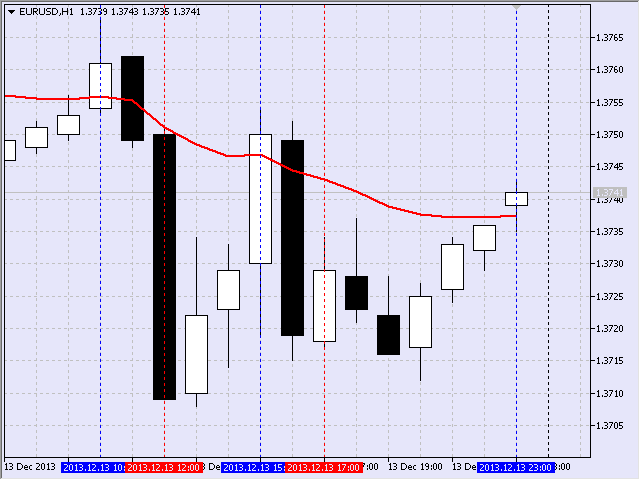
Fig. 19 Affichage des cadres
Curieusement, la dernière image s'est formée au cours de la dernière heure, le vendredi 13 décembre 2013. Il relevait de la deuxième liste puisqu'il durait 6 heures.
4.2 Traiter avec le trading virtuel
Imaginez que vous deviez créer un Expert Advisor qui mettrait en œuvre plusieurs stratégies indépendantes par rapport à un instrument dans un flux de ticks. Il est clair qu'en réalité une seule stratégie peut être mise en œuvre à la fois par rapport à un instrument. Toutes les autres stratégies seront de nature virtuelle. Ainsi, il peut être mis en œuvre uniquement à des fins de test et d'optimisation d'une idée de trading.
Ici, je dois faire référence à un article fondamental qui fournit une description détaillée des concepts de base liés au trading en général et, en particulier, au terminal MetaTrader 5: «Ordres, positions et transactions dans MetaTrader 5»..
Donc, si pour résoudre ce problème, nous utilisons le concept de trading, le système de gestion des objets de trading et la méthodologie de stockage d'informations sur les objets de trading qui sont habituels dans l'environnement MetaTrader 5, nous devrions probablement penser à créer une base de données virtuelle.
Permettez-moi de vous rappeler qu'un développeur classe tous les objets de trading en ordres, positions, transactions et ordres d'historique. Un œil critique remarquera peut-être que le terme « objet de trading» a été utilisé ici par l'auteur lui-même. C'est vrai...
Je propose d'utiliser une approche similaire dans le trading virtuel et d'obtenir les objets de trading virtuels suivants : ordres virtuels, positions virtuelles, transactions virtuelles et ordres d'historique virtuel.
Je pense que ce sujet mérite une discussion approfondie et plus détaillée. En attendant, pour revenir au sujet de l'article, je voudrais dire que les types de données conteneurs, y compris les listes, peuvent faciliter la vie du programmeur lors de la mise en œuvre de stratégies virtuelles.
Pensez à une nouvelle position virtuelle qui, bien entendu, ne peut pas être du côté du serveur de trade. Cela signifie que les informations à ce sujet doivent être enregistrées du côté du terminal. Ici, une base de données peut être représentée par une liste qui à son tour se compose de plusieurs listes, dont l'une contiendra des nœuds de la position virtuelle.
En utilisant l'approche du développeur, il y aura les classes de trading virtuel suivantes :
Classe/Groupe | Description |
Commande Virtuelle C | Cours pour travailler avec des commandes virtuelles en attente |
CVirtualHistoryOrder | Cours pour travailler avec des commandes «historiques» virtuelles |
Position CVirtual | Cours pour travailler avec des postes ouverts virtuels |
CVirtualDeal | Cours pour travailler avec des offres «historiques» virtuelles |
TradelCVirtua | Cours pour effectuer des opérations de trading virtuel |
Table 1. Cours de trading virtuel
Je ne discuterai pas de la composition d'aucune des classes de trading virtuelles. Mais il contiendra probablement toutes ou presque toutes les méthodes d'une classe de trading standard. Je veux juste noter que ce que le développeur utilise n'est pas une classe d'un objet de trading donné lui-même, mais une classe de ses propriétés.
Afin d'utiliser des listes dans vos algorithmes, vous aurez également besoin de nœuds. Par conséquent, nous devons envelopper la classe d'un objet de trading virtuel dans un nœud.
Supposons que le nœud d'une position ouverte virtuelle soit de typeCVirtualPositionNode La définition de ce type pourrait initialement être la suivante :
//+------------------------------------------------------------------+ //| Class CVirtualPositionNode | //+------------------------------------------------------------------+ class CVirtualPositionNode : public CObject { protected: CVirtualPositionNode *m_virt_position; // pointer to the virtual function public: void CVirtualPositionNode(void); // default constructor void ~CVirtualPositionNode(void); // destructor };
Désormais, lorsque le poste virtuel s'ouvre, il peut être ajouté à la liste des postes virtuels.
Je voudrais également noter que cette approche pour travailler avec des objets de trading virtuels ne nécessite pas l'utilisation de mémoire cache car la base de données est stockée dans la mémoire vive. Vous pouvez, bien sûr, faire en sorte qu'il soit stocké sur d'autres supports de stockage.
Conclusion
Dans cet article, j'ai essayé de démontrer les avantages d'un type de données conteneur, tel que liste. Mais je ne pouvais pas passer sans mentionner ses inconvénients. Quoi qu'il en soit, j'espère que ces informations seront utiles à ceux qui étudient la POO en général, et en particulier, l'un de ses principes fondamentaux, le polymorphisme.
Emplacement des fichiers :
À mon avis, il serait préférable de créer et de stocker des fichiers dans le dossier du projet. Par exemple, comme ceci : %MQL5\Projects\UserLists. C'est là que j'ai enregistré tous les fichiers de code source. Si vous utilisez des répertoires par défaut, vous devrez modifier la méthode de désignation du fichier d'inclusion (remplacez les guillemets par des chevrons) dans le code de certains fichiers.
| # | Fichier | Localisation | Description |
|---|---|---|---|
| 1 | CiSingleNode.mqh | %MQL5\Projects\UserLists | Classe d'un nœud de liste à chaînage simple |
| 2 | CDoubleNode.mqh | %MQL5\Projects\UserLists | Classe d'un nœud de liste à double chaînage |
| 3 | CiUnrollDoubleNode.mqh | %MQL5\Projects\UserLists | Classe d'un nœud de liste à double chaînage déroulée |
| 4 | test_nodes.mq5 | %MQL5\Projects\UserLists | Script avec des exemples de travail avec des nœuds |
| 5 | CiSingleList.mqh | %MQL5\Projects\UserLists | Classe d'une liste à chaînage simple |
| 6 | CDoubleList.mqh | %MQL5\Projects\UserLists | Classe d'une liste à double chaînage |
| 7 | CiUnrollDoubleList.mqh | %MQL5\Projects\UserLists | Classe d'une liste à double chaînage déroulée |
| 8 | CiCircleDoublList.mqh | %MQL5\Projects\UserLists | Classe d'une liste circulaire à double chaînage |
| 9 | test_sList.mq5 | %MQL5\Projects\UserLists | Script avec des exemples de travail avec une liste à chaînage simple |
| 10 | test_dList.mq5 | %MQL5\Projects\UserLists | Script avec des exemples de travail avec une liste à double chaînage |
| 11 | test_UdList.mq5 | %MQL5\Projects\UserLists | Script avec des exemples de travail avec une liste à double chaînage déroulée |
| 12 | test_CdList.mq5 | %MQL5\Projects\UserLists | Script avec des exemples de travail avec une liste circulaire à double chaînage |
| 13 | test_MQL5_List.mq5 | %MQL5\Projects\UserLists | Script avec des exemples d'utilisation de la classe CList |
| 14 | CNodeInt.mqh | %MQL5\Projects\UserLists | Classe du nœud de type entier |
| 15 | CIntList.mqh | %MQL5\Projects\UserLists | Classe de liste pour les nœuds CNodeInt |
| 16 | CRandom.mqh | %MQL5\Projects\UserLists | Classe d'un générateur de nombres aléatoires |
| 17 | CVertLineNode.mqh | %MQL5\Projects\UserLists | Classe de nœud pour la gestion du cadre des lignes verticales |
| 18 | Stat_collector.mq5 | %MQL5\Projects\UserLists | Script avec un exemple de collecte de statistiques |
Les références:
- A. Friedman, L. Klander, M. Michaelis, H. Schildt. Archives annotées C/C++. Médias McGraw-Hill Osborne, 1999. 1008 pages.
- V.D. Daleka, A.S. Derevyanko, O.G. Kravets, L.E. Timanovskaya. Modèles et structures de données. Guide d'étude. Kharkov, KhGPU, 2000. 241 pages (en russe).
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/709
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Indicateurs techniques et filtres numériques
Indicateurs techniques et filtres numériques
 Livre de recettes MQL5 - Expert Advisor multi-devises et utilisation des commandes en attente dans MQL5
Livre de recettes MQL5 - Expert Advisor multi-devises et utilisation des commandes en attente dans MQL5
 Élevez vos systèmes de trading linéaires au rang de puissance
Élevez vos systèmes de trading linéaires au rang de puissance
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Bonjour,
J'ai essayé de compiler test_MQL5_List.mq5 , j'ai obtenu les erreurs suivantes :
'm_head' - membre de l'objet constant ne peut être modifié CiSingleList.mqh 504 9
'm_tail' - membre de l'objet constant ne peut être modifié CiSingleList.mqh 505 9
'm_size' - membre de l'objet constant ne peut être modifié CiSingleList.mqh 496 9
Voici le code réparé. Veuillez remplacer l'ancienne version.
L'erreur consistait à déclarer certaines méthodes comme constantes, alors qu'elles ne le sont pas.
Voici le code réparé. Veuillez remplacer l'ancienne version.
L'erreur consistait à déclarer certaines méthodes comme constantes, alors qu'elles ne le sont pas.
Il n'y a plus d'erreurs.
Merci Dennis.