¿Hay algún patrón en el caos? ¡Intentemos encontrarlo! Aprendizaje automático a partir de una muestra concreta. - página 25
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
En TP=SL, será aproximadamente del 50%. En TP = 2*SL, será del 33%, etc.
Siempre el beneficio medio de 1 operación es muy pequeño. Alrededor de 0,00005. Pero se gastará en spread, slippage, swap, que no se tienen en cuenta en el markup del maestro (el spread se tiene en cuenta, pero el mínimo por barra, el real será mayor).
Y esto Usando TP=SL=0,00400. Es decir, con un riesgo de 400 obtenemos un beneficio de 5 pts, es decir, la ventaja del 1%.
Me gustaría sacar al menos 10 pts del movimiento de 50 pts, pero ahí todas las opciones son ciruela.
Pero todo esto es con mis fichas y objetivos. Tal vez hay mejores opciones.
Esta estrategia da un 43% de operaciones rentables en EURUSD desde 2008 hasta 2023, con un ratio TP/SL de 61.8, y el 39% de las operaciones rentables son suficientes para alcanzar el punto de equilibrio. No he comprobado los números todavía, puedo estar equivocado en alguna parte, y estas son, por supuesto, condiciones ideales. Sin embargo, hay una perspectiva de aprendizaje aquí, lo que significa que usted puede sacar un mayor porcentaje a expensas de MO.
En cuanto a los predictores, ¿tomaste mis predictores de mi artículo? Se encuentran a menudo en los modelos que tengo, entre otros.
Añadido: Sí, no tuve en cuenta que hay operaciones rentables, pero no cerradas por TP, y habrá menos beneficio por supuesto.Esta estrategia da un 43% de operaciones rentables en EURUSD desde 2008 hasta 2023, con un ratio TP/SL de 61.8 en condiciones ideales, y el 39% de las operaciones rentables son suficientes para alcanzar el punto de equilibrio. Todavía no he comprobado los números, puedo estar equivocado en alguna parte, y estas son, por supuesto, condiciones ideales. Sin embargo, hay una perspectiva de aprendizaje aquí, lo que significa que usted puede sacar un mayor porcentaje a expensas de MO.
En cuanto a los predictores, ¿tomaste mis predictores de mi artículo? Se encuentran a menudo en los modelos que tengo, entre otros.
No estoy muy seguro de cuál es tu estrategia. Parece que recibes una señal para entrar una vez al día. Creo que es muy poco hablar de la significación estadística de los resultados.
He entrenado tus más de 5000 predictores en tu conjunto de datos. No dan más que los mismos 5 pts, así que creo que no son mejores que mis simples deltas de precio y zigzags, que también dan 5 pts.
Comprobaré otras ideas por ahora. Si no dan nada, probaré tus predictores para generar mi propio modelo.
Realmente no entiendo cuál es su estrategia. Parece una señal para entrar una vez al día.
La estrategia es la siguiente:
En la apertura del día calculamos el rango límite esperado de movimiento del precio, para ello podemos utilizar ATR(3) al final del último día, yo uso una fórmula ligeramente diferente. Posponemos este rango desde el principio de la apertura del día actual (barra) - lo consideramos como el 100%.
Al llegar a un nivel significativo por encima / por debajo de la apertura (me detuve en 23,6, ya que a menudo resulta ser tal en diferentes instrumentos de acuerdo a mis observaciones), abrimos una posición con TP en el siguiente nivel significativo (yo uso 61,8), y poner SL en el precio de apertura del día.
Si cerramos en take profit, entramos de nuevo cuando aparezca una señal.
Es mejor cerrar al final del día (23:45) si las tomas de ganancias no funcionaron, pero de hecho estoy esperando TP/SL.
Ahora el margen inicial funciona así - si cerramos en ganancias, ponemos 1, si cerramos en pérdidas -1.
Al dividir la muestra, he hecho que el objetivo se desplace 300 pips, por lo que si el beneficio es inferior a 300 pips, es cero.
Creo que esto es muy poco para hablar de la significación estadística de los resultados.
Tomé los datos de 2008. Sí, no hay muchos datos, pero depende de cómo se mire, porque si se considera que el nivel de 23,6 no es aleatorio y su cruce es significativo para el mercado, entonces será como eventos similares que se pueden comparar entre sí, a diferencia de la situación al generar entradas en cada barra - hay muchos eventos similares, que sólo complica el aprendizaje.
Así que creo que tiene sentido para entrenar de esta manera, pero los eventos que influyen en la decisión de los participantes del mercado debe ser diferente en diferentes estrategias. Y, además de comercio conjuntos de modelos.
He entrenado sus más de 5000 predictores en su conjunto de datos. No dan más que los mismos 5 pts, así que creo que no son mejores que mis simples deltas de precios y zigzags, que también dan 5 pts.
Comprobaré otras ideas por ahora. Si no dan nada, probaré tus predictores para generar mi propio modelo.
¿Te refieres a la primera muestra o a la segunda? Si es la primera, entonces tenía una matriz de expectativas de unos 30 puntos para las variantes buenas.
Puedo intentar entrenar tu muestra en CatBoost, si la subes, por supuesto.
Esta es la estrategia:
En la apertura del día calculamos el rango límite esperado de movimiento del precio, para ello podemos utilizar ATR(3) al final del último día, yo uso una fórmula ligeramente diferente. Posponemos este rango desde el principio de la apertura del día actual (barra) - lo consideramos al 100%.
Cuando alcanzamos un nivel significativo por encima/debajo de la apertura (yo me detuve en 23.6 ya que a menudo resulta ser así en diferentes instrumentos según mis observaciones) abrimos una posición con TP en el siguiente nivel significativo (yo uso 61.8), y ponemos SL en el precio de apertura del día.
Si cerramos en take profit, entramos de nuevo cuando aparezca una señal.
Es mejor cerrar al final del día (23:45) si las tomas de ganancias no funcionaron, pero de hecho estoy esperando TP/SL ahora.
Ahora el margen inicial funciona así - si cerramos en beneficios, ponemos 1, si cerramos en pérdidas -1.
Al dividir la muestra, hice que el objetivo se compensara en 300 pips, por lo que si el beneficio es inferior a 300 pips, es cero.
Tomé datos de 2008. Sí, no hay muchos datos, pero depende de cómo se mire, porque si consideramos que el nivel de 23,6 no es casual y su cruce es significativo para el mercado, entonces son eventos similares que se pueden comparar entre sí.
Ahora el objetivo está más o menos claro.
¿Tienes una estimación del resultado en pips o sólo en ganancias/pérdidas? Parece que lo segundo. Es mejor estimar en pts.
Para que el modelo que da 75% no funcione en realidad 50/50.
a diferencia de la situación cuando las entradas se generan en cada barra - hay muchos eventos de este tipo, que sólo complica el aprendizaje.
Me gustaría añadir adelgazamiento - bares similares, si el precio no ha ido por 100...1000 pts, a continuación, omitir.
¿Estás hablando de la primera muestra o de la segunda? Si usted está hablando de la primera, entonces tenía una matriz de expectativas de alrededor de 30 pips para buenas variantes.
La segunda en H1. Bueno, la primera no era mejor (pero la investigué menos, no seleccioné características, por ejemplo).
Puedo intentar entrenar tu muestra en CatBoost, si la subes, claro.
Tengo cientos de ellas. Y no me gusta ninguno de ellos para poner en el comercio. Cambio TP o SL u otra cosa - que es una nueva variante. Así que no tiene sentido.
Ahora el objetivo está más o menos claro.
¿Tienes una estimación del resultado en puntos o sólo ganar/perder? Parece que lo segundo. Es mejor estimar en pts.
Para que un modelo del 75% no funcione realmente 50/50.
Tengo una valoración en dinero :) Más objetivo, como solía ser. El objetivo se puede mover más tarde, si quieres más puntos.
En la estrategia específica ahora todo es take profit. Hice un lote calculado, de hecho resultó que la propagación empeora significativamente la proporción, pero está bien, pero habrá estabilidad sin emisiones de entradas super rentables - el riesgo es casi el mismo en todas partes. Si a continuación, utilizar las pausas, usted será capaz de mejorar el resultado.
Me gustaría añadir adelgazamiento - barras similares, si el precio no ha ido por 100...1000 pts, a continuación, omitir.
Y luego evaluar en cada barra, así modelo a aplicar?
El segundo en H1. Bueno, el primero no era mejor, (pero lo investigué menos, no seleccioné fichas por ejemplo).
Tengo cientos de ellas. Y ninguna me gusta ponerla en el trade. Cambio TP o SL u otra cosa - que es una nueva variante. Así que no tiene sentido.
Mi punto es que si existe el mismo algoritmo para crear una muestra, será posible comparar los predictores.
Y luego para estimar en cada bar, ¿bien el modelo a aplicar?
Sí, si han pasado al menos XX pips, como en el entrenamiento. Pero habrá distorsiones - sólo las primeras barras de 100 a 120 (200-220, etc) si arriba y 999-979 (899-979) trabajará más a menudo.
Mi punto es que si existe el mismo algoritmo para crear una muestra, será posible comparar predictores.
Realmente no quiero 5000+, tomará mucho tiempo para contar. Pero como una búsqueda de predictores significativos puede ser necesario comprobarlos.
Buenas tardes.
Tengo un enfoque que puede resolver este problema, pero preferiblemente los archivos de muestra deben ser sin predictores. Es decir, no se necesitan más de 5000 predictores, sólo el propio gráfico de movimiento. Si consiste en OHLC o tiene una variable no es importante. Sin embargo, probé el método existente en una variable de la muestra, concretamente en la columna 5584, que convertí en un gráfico utilizando la fórmula D(i)=D(i-1)+ Target_100_Buy . Para los tres archivos obtuve estos gráficos:
1)entrenar: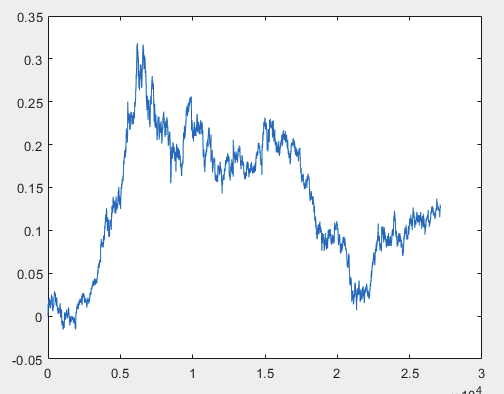
2)prueba: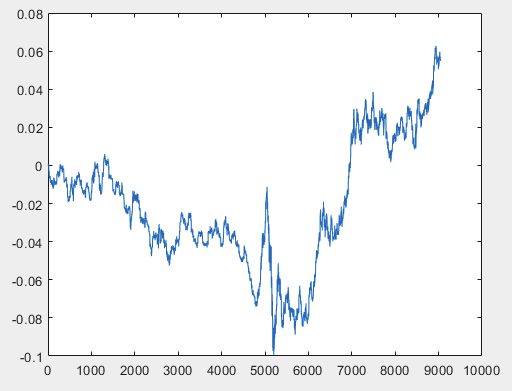
3)examen: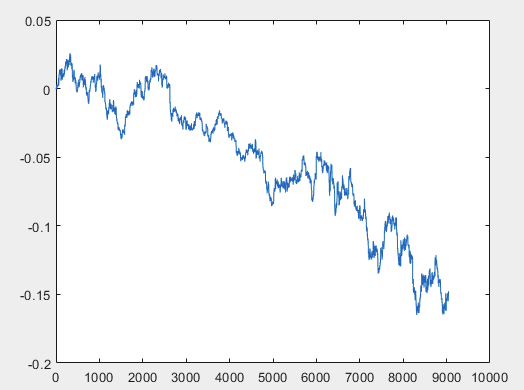
No sé si lo he hecho bien o no, pero si el topikstarter hace nuevas muestras sin predictores, probaré el método con nuevos datos y os cuento el planteamiento.
Bueno, y el beneficio real para cada una de las muestras después de entrenar al comité de redes neuronales (son 10 en total). El beneficio se expresa en número de puntos, con spread=0 y comisión=0:
1) entrenar: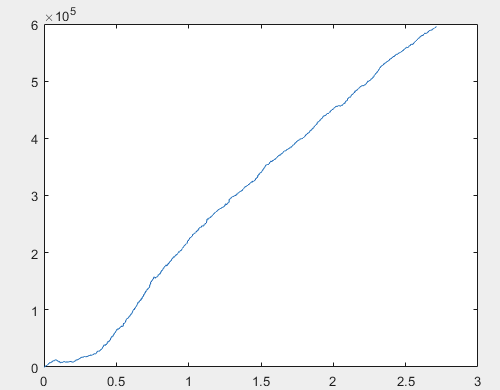
2) prueba: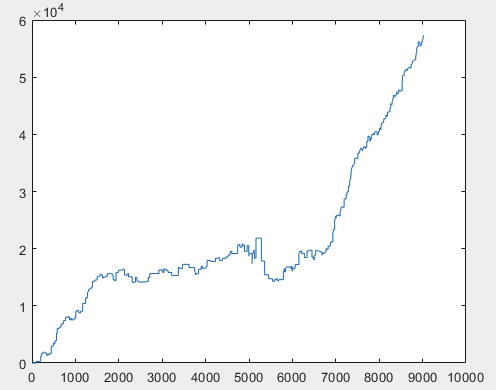
3) examen: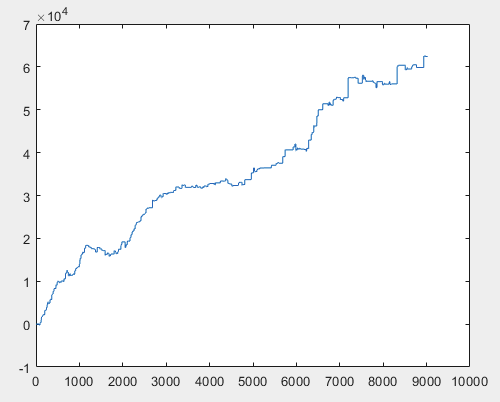
Creo que el resultado de 60000+ pips es bastante aceptable.
Sugiero al topikstarter hacer nuevas muestras, sólo de la señal más "caótica".
El método se aplicará a la nueva señal y los resultados se mostrarán, así como el enfoque se describirá en cierta medida.
¡Saludos, RomFil!
P.D. El futuro no se conoce, pero siempre se puede encontrar un método para controlarlo ... :)
¡Buenas tardes!
Tengo un enfoque que puede resolver este problema, pero preferiblemente los archivos de muestra deben ser sin predictores. Es decir, no se necesitan más de 5000 predictores, sólo el propio gráfico de movimiento. Si consiste en OHLC o tiene una variable no es importante. Sin embargo, he probado el método existente en una variable de la muestra, concretamente en la columna 5584, que he convertido en un gráfico utilizando la fórmula D(i)=D(i-1)+ Target_100_Buy . Para los tres archivos, los gráficos son los siguientes:
No entiendo lo que hiciste y por qué se necesita una nueva muestra si tu enfoque funciona con precios puros.
Las columnas de la lista de abajo son el resultado del evento que ocurrió, es decir, no deberían participar en el entrenamiento. Como mucho 5582 - pero ahí creo que es fácil de predecir, así que será recuperado por el modelo tal cual.
5581 Auxiliar
5582 Auxiliar
5583 Etiqueta
5584 Auxiliar
5585 Auxiliar
No entiendo lo que hiciste y por qué se necesita una nueva muestra si tu enfoque funciona con precios puros.
Las columnas de la lista de abajo son el resultado de un evento que ocurrió, es decir, no deberían participar en el entrenamiento. Como mucho 5582 - pero creo que es fácil de predecir, por lo que será recuperado por el modelo.
5581 Auxiliar
5582 Auxiliar
5583 Etiqueta
5584 Auxiliar
5585 Auxiliar
"¿Qué he hecho?":
El tren de muestra tiene un tamaño aproximado de 1 GB. Tarda bastante en cargarlo en el espacio de trabajo. Tengo un i5-3570 con 24GB de RAM y un SSD rápido y Excel tarda varios minutos en abrir este archivo. Por eso decidí que había que acortarlo. Yo era demasiado perezoso para averiguar los superíndices para 5000+ columnas. Tomé la columna 5584 5586 y apliqué una señal a todas las filas, por ejemplo COMPRA (honestamente, no recuerdo cuál, tal vez VENTA). Así, esta columna formó un gráfico de acuerdo con la fórmula anterior. Es decir, el primer paso era cero, luego 0,00007, luego 0,00007-0,00002=0,00005, luego 0,00005+0,00007=0,00012, etc. Es decir, a partir de la columna 5584 5586 he formado un gráfico de movimiento sin enlace, por así decirlo un gráfico de movimiento relativo. Como si fuera un gráfico Close, es decir, al final de cada paso del gráfico el precio del activo cambia en el valor correspondiente.
P.D. Engañado sobre el número de columna ... Tomé la más reciente 5586 (lo acabo de buscar en Excel) con la señal de VENTA.
"... por qué una nueva muestra":
Para mostrar y decir en cierta medida sobre el enfoque en su ejemplo. Si usted nombra los números de columnas donde se puede tomar OHLC o sólo los precios de las cláusulas, será suficiente.
Sobre el resto:
Los datos de los archivos de ejemplo no se utiliza en absoluto. En base a las columnas 5584 5586 de cada fichero, se hace un gráfico como se ha descrito anteriormente. Y el enfoque ya se aplica a estos gráficos obtenidos.
Bueno, ya que el topikstarter no quiere dar nuevas muestras, sugiero a quien esté interesado que publique las suyas propias ... :)
¡Saludos, RomFil!
¡Buenas tardes!
Tengo un enfoque que puede resolver este problema, pero preferiblemente los archivos de muestra deben ser sin predictores. Es decir, no se necesitan más de 5000 predictores, sólo el propio gráfico de movimiento. Si consiste en OHLC o tiene una variable no es importante. Sin embargo, he probado el método existente con una variable de la muestra, concretamente la columna 5584, que he convertido en un gráfico utilizando la fórmula D(i)=D(i-1)+ Target_100_Buy . Para los tres archivos, los gráficos son los siguientes:
¿Se entrena la repetibilidad de la función objetivo? Por ejemplo, si tuvo éxito 20 veces, ¿tendrá éxito 21 veces?
¿Cuántos valores se introducen como predictores?
Aquí están los objetivos más simples para comprar y para vender con TP/SL=50 pts
M5 durante unos 5 años.
El margen es en cada barra M5, es decir, lo más probable es que el comercio de la última señal (hace 5 min) no ha terminado todavía. No estoy seguro de que sea correcto apilarlas. El apilamiento estaría bien para un objetivo con sólo 1 operación en 1 momento en el tiempo - incluso 100 al mismo tiempo pueden no completarse durante la noche.
P.D. - Los tengo sin entrenar. Siempre fallan en mi conjunto de predictores.