¿Hay algún patrón en el caos? ¡Intentemos encontrarlo! Aprendizaje automático a partir de una muestra concreta. - página 18
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Aleatorio es fijo :) Parece que esta semilla se calcula de una manera complicada, es decir, todos los predictores permitidos para la construcción del modelo están probablemente involucrados, y cambiar su número también cambia el resultado de la selección.
La semilla inicial es fija. Y luego aparece un nuevo número con cada llamada del HSC. Es por eso que a diferente número de predictores y el número de DSTs no caerá en el mismo predictor como en el número total de predictores.
¿Por qué se ajusta esto, o más bien en qué se ve? Tiendo a pensar que la muestra de prueba difiere del examen más que el examen del tren, es decir, hay diferentes distribuciones de probabilidad de los predictores.
Pues bien, tomas las mejores variantes del examen, con la esperanza de que sean buenas en la prueba. Seleccionas los predictores basándote en el mejor examen. Pero son los mejores sólo para el examen.
¿Qué es la métrica "err_"?
err_ oob - error en OOB (lo tienes examen), err_trn - error en tren. Por la fórmula obtendremos algún error común para ambos sitios de muestreo.
Por cierto, en la discusión hemos intercambiado prueba y examen. Al principio planeamos controles intermedios en la prueba y controles finales en el examen. Pero el contexto deja claro qué es qué, aunque hayan cambiado los nombres.
El número inicial es fijo. Y luego aparece un nuevo número con cada llamada de la DST. Por lo tanto, con un número diferente de predictores y números de DST no se caerá en el mismo predictor que con el número completo de predictores.
Nah, las variantes se reproducen allí si los predictores utilizados para el entrenamiento se dejan en el mismo número.
Bueno, se toman las mejores variantes del examen, con la esperanza de que sean buenas en el examen. Los predictores son seleccionados por el mejor examen. Pero son los mejores sólo para el examen.
Sucedió que esta variante fue la más equilibrada - con un beneficio decente en la prueba y el examen. Abajo en la imagen es el modelo seleccionado inicialmente - "Era" y el mejor modelo equilibrado después de 10k entrenamiento - "Se convirtió en". En general, el resultado es mejor, y se utilizan menos predictores, por lo que se elimina el ruido. Y aquí la cuestión es cómo evitar este ruido antes del entrenamiento.
Y la lógica es tal que el entrenamiento se detiene en la prueba, por lo que debería haber más probabilidades de obtener un resultado positivo allí que en la muestra que no participa en absoluto en el entrenamiento, por lo que se hace hincapié en esta última.
err_ oob - error en OOB (lo tiene examen), err_trn - error en trn. Por la fórmula obtendremos algún error común para ambos sitios de muestreo.
Quiero decir, no sé cómo se cuenta "err" - ¿es Accuracy? Y por qué examen y no prueba, porque en el examen de enfoque básico no vamos a saber.
Por cierto, hemos cambiado test y examen en la discusión. Al principio estaba previsto que las pruebas intermedias fueran en test y las finales en examen. Pero por el contexto está claro qué es qué, aunque cambiaron los nombres.
Yo no he cambiado nada (¿quizás me he descrito en algún sitio?) - simplemente es como es - on train - formación, test - control de parar la formación, y exam - sección no implicada en ningún tipo de formación.
Sólo estoy evaluando la eficacia del enfoque por el promedio de todos los modelos, incluyendo el beneficio medio - es más probable que se obtenga que los bordes con un buen resultado.
Y luego está la cuestión de cómo evitar ese ruido antes de empezar a entrenar.
Aparentemente no se puede. Se trata de filtrar el ruido y aprender a partir de los datos correctos.
Quiero decir que no sé cómo se considera "err" - ¿es Accuracy?
Es una forma de obtener un error combinado/resumido en una traine con una prueba. Se puede sumar cualquier tipo de error. Y (1-accuracy) y RMS y AvgRel y AvgCE etc.
No he cambiado nada(¿tal vez me he descrito en alguna parte?) - así es como es - en tren - formación, prueba - control de detener la formación, y el examen - sección no involucrada en cualquier tipo de formación.
Me pareció por las fotos que el examen significa prueba
Por ejemplo aquí.
Y en la tabla de arriba resultados del examen son mejores que la prueba. Ciertamente es posible, pero debería ser al revés.
Parece que no. Ése es el reto, eliminar el ruido y aprender de los datos correctos.
No, tiene que haber una manera, de lo contrario todo es inútil/aleatorio.
Esta es una forma de obtener el error combinado/resumido en una línea con una prueba. Se puede sumar cualquier tipo de error. Y (1-accuracy) y RMS y AvgRel y AvgCE etc.
Entendido, pero eso no funciona con mis datos - debería haber alguna correlación al menos :)
Me pareció a partir de las imágenes que el examen significaba prueba
Por ejemplo aquí
Y en la tabla de arriba los resultados del examen son mejores que los del test.
Sí, resulta que el examen tiene más probabilidades de ganar más dinero para los modelistas, yo mismo no entiendo del todo la situación.
Por desgracia, ahora me di cuenta de que en algún momento me confundí la muestra total (filas) y ahora los ejemplos de 2022 están en el tren :(.
Voy a rehacer todo - creo que tendré el resultado en un par de semanas - vamos a ver si el panorama general cambia.
Por desgracia, ahora me he dado cuenta de que en algún momento he mezclado la muestra total (filas), y ahora el tren incluye ejemplos de 2022 :(
Lo volveré a hacer - creo que tendré el resultado en un par de semanas - a ver si cambia el panorama general.
Da igual que se haya evaluado por examen o por test. Lo principal es que no se utilizó el lugar de evaluación ni en la formación ni en la evaluación inicial.
2 semanas. Me sorprende tu resistencia. Yo me fastidio con 3 horas de cálculos también..... Y ya he pasado un total de 5 años en MO, más o menos lo mismo que tú.
En fin, empezaremos a ganar algo en la jubilación )))) Puede ser.
Por desgracia, ahora me he dado cuenta de que en algún momento he mezclado la muestra global (filas) y ahora el tren está poblado de ejemplos de 2022 :(
Tengo todo pegado en 1 array secuencial. Y luego separo la cantidad justa de ella. Así no se mezcla nada.
No importa si se evaluó mediante examen o prueba. Lo principal es que el lugar de evaluación no se utilizó ni en la formación ni en la evaluación inicial.
Me pregunto si es mejor hacer el entrenamiento final como Maxim -tomando una muestra prehistórica como control-, o si es mejor tomar toda la muestra disponible y limitar el número de árboles, como se hace de media en los mejores modelos.
2 semanas... Me asombra tu resistencia. A mí también me resultan molestas 3 horas de cálculos..... Y ya he dedicado un total de 5 años a MO, más o menos lo mismo que tú.
Por supuesto, uno siempre quiere obtener resultados más rápido. Intento cargar el hardware de manera que mis cálculos no interfieran con otras cosas - a menudo no uso el ordenador principal de trabajo. Paralelamente puedo implementar otras ideas en código - se me ocurren ideas más rápido de lo que tengo tiempo para comprobarlas en código.
En resumen, vamos a empezar a ganar algo en la jubilación )))) Tal vez.
Estoy de acuerdo - la perspectiva es triste. Si no viera progresos en mi investigación, aunque lentos, probablemente ya habría terminado el trabajo.
Tengo todo pegado en 1 matriz secuencial. Y luego de esa matriz separo la cantidad correcta. Así no se mezcla nada.
Sí, convertí la muestra a un archivo binario, y en el script puse una casilla de verificación por accidente, al parecer, responsable de mezclar la muestra - por lo que no es un problema, y CatBoost requiere 3 muestras separadas - no hicieron la selección en el rango de filas, aunque tienen una validación cruzada incorporada.
También me pregunto si es mejor hacer el entrenamiento final como Maxim, tomando una muestra prehistórica como control, o si es mejor tomar toda la muestra disponible y limitar el número de árboles, como se hace de media en los mejores modelos.
Para mí, el preentrenamiento y las pruebas son una oportunidad para seleccionar de media los mejores hiperparámetros (número de árboles, etc.) y predictores. E incluso sin una prueba se puede entrenar en ellos en la línea e inmediatamente entrar en el comercio.
La idea del muestreo prehistórico funcionará si los patrones no cambian, tal vez sea así. Pero existe el riesgo de que cambien. Así que prefiero no correr riesgos y probar en el futuro muestreo.
Otra cuestión es cuánto tiempo hace de esta muestra prehistórica: ¿seis meses o quince años? Hace seis meses podría funcionar, pero el mercado de hace 15 años no es el mismo que el de ahora. Pero no es seguro. Quizá haya patrones que lleven funcionando décadas.Describiré los resultados obtenidos utilizando el mismo algoritmo que he descrito aquí, pero con la muestra sin mezclar, es decir, permaneciendo en orden cronológico.
Lo único que he cambiado es que ahora el entrenamiento de 10000 modelos se realizó no sobre la muestra completa en la que participaban los predictores excluidos, sino sobre una muestra re-formada en la que se eliminaron las columnas con predictores excluidos, lo que aceleró el proceso de entrenamiento (aparentemente bombear un archivo grande lleva mucho tiempo). Gracias a estos cambios pude realizar de forma consistente 6 pasos de selección de predictores.
Figura 1: Histograma del beneficio en el examen de la muestra después de entrenar 100 modelos en todos los predictores de la muestra.
Figura 2: Histograma de beneficios de la muestra de examen tras entrenar 10.000 modelos con los predictores de la muestra seleccionados - paso 1.
Figura 3. Histogramade los beneficios de la muestra del examen tras el entrenamiento de 10.000 modelos con los predictores de la muestra seleccionada (paso 2).
Figura 4: Histograma de beneficios de la muestra de examen tras el entrenamiento de 10.000 modelos con los predictores de muestra seleccionados - paso 3.
Figura 5: Histograma de los beneficios de la muestra de examen tras el entrenamiento de 10.000 modelos con los predictores de muestra seleccionados - paso 4.
Figura 6: Histograma de beneficios de la muestra de examen tras el entrenamiento de 10.000 modelos con los predictores de muestra seleccionados - paso 5.
Figura 7: Histograma de beneficios de la muestra de examen tras el entrenamiento de 10.000 modelos con los predictores de muestra seleccionados (paso 6).
Figura 8. Tabla con las características de los modelos que se seleccionaron para formar muestras posteriores con un número decreciente de predictores (características).
Consideremos el modelo con las siguientes características obtenido en el 6º paso de selección de predictores.
Figura 9: Características del modelo.
Figura 10. Visualización del modelo sobre el examen de la muestra como una distribución sobre la probabilidad de clasificación - eje x - probabilidades obtenidas a partir del modelo, y y - porcentaje de todas las muestras.
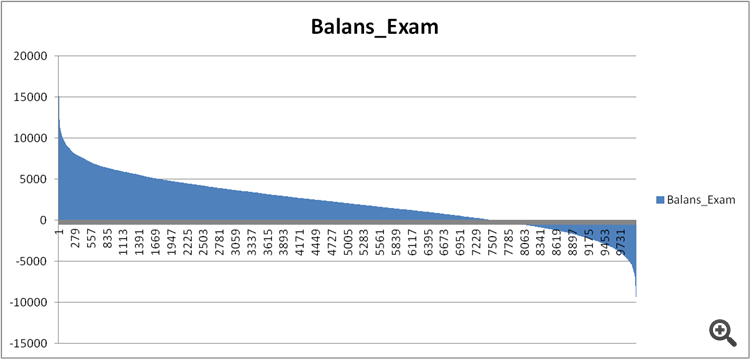
Figura 11. Balance del modelo sobre la muestra de examen.
Comparemos ahora los predictores de los modelos razonablemente buenos y extremadamente malos obtenidos en el paso 6 de la selección de predictores.
Figura 12. Comparación de las características de los modelos. Comparación de las características de los modelos.
¿Podemos ver ahora qué predictores tienen un efecto tan negativo en el resultado financiero y estropean el entrenamiento?
Figura 13. Ponderación de los predictores en los dos modelos.
La figura 13 muestra que se utilizan casi todos los predictores disponibles, excepto uno, pero dudo que ésta sea la raíz del problema. Entonces, ¿no se trata tanto de una cuestión de uso, sino más bien de la secuencia de uso en la construcción del modelo?
Hice una comparación de dos tablas, asignando un número ordinal de significación en lugar de un índice, y vi lo diferente que se clasifica esta significación en los modelos.
Figura 14: Tabla de comparación de la significación (uso) de los predictores en los dos modelos.
Pozo e histograma para una mejor visualización - las desviaciones en menos significan que el predictor del segundo modelo (no rentable) se utilizó más tarde, y en más - más temprano.
Figura 15. Desviaciones de significación de los predictores en los modelos.
Se puede ver que hay fuertes desviaciones, tal vez sea así, pero ¿cómo averiguarlo/probarlo? Tal vez sea necesario algún enfoque complejo de comparación de los modelos con la referencia, ¿alguna idea?
¿Existe algún tipo de índice de confusión para describir el sesgo general, quizás teniendo en cuenta la importancia de los predictores para el primer modelo, es decir, con un coeficiente decreciente?
¿Qué conclusiones pueden extraerse?
Mi conjetura es la siguiente:
1. Los resultados fueron mucho mejores en la muestra del pasado, supongo que esto se debe a la información que se "filtró" sobre acontecimientos del futuro al mezclar la cronología de la muestra. La cuestión es si los modelos serán más estables obtenidos sobre una muestra mezclada o sobre una muestra normal.
2. Es necesario construir una estructura de significación de los predictores para su posterior aplicación en los modelos, es decir, además de los números es necesario establecer la lógica, de lo contrario la dispersión de los resultados de los modelos es demasiado grande incluso con un pequeño número de predictores.