Библиотеки: Statistical Functions
Как вы реализуете?
Спасибо за интерес к моей библиотеке. Использовать ее очень просто, в основном вы оперируете с массивами 1 измерения.
Например, вы можете легко удалить линейный тренд из временных рядов с помощью функции detrend:
detrend(timeSerie, detrendResultArray);
timeSerie - это массив, заполненный ценами, а detrendResultArray должен быть пустым массивом, в котором будут храниться результаты.
Таким образом, после вызова функции у вас будет массив с детрендированными временными рядами, на которых вы можете проводить дальнейший анализ (например, проверять, является ли ряд стационарным).
Например, если у вас есть массив с валютой Currency1 (возможно, в обратном направлении), вы можете спрогнозировать ее следующее значение с помощью функции:
double detrendedSerie[]; double forecastedValue; //делаем валюту Currency1 хранимой в обратном порядке (последнее значение в массиве - самая новая цена) detrend(Currency1, detrendedSerie); if(dickeyFuller(detrendedSerie)){ forecastedValue = AR1(detrendedSerie); } if(forecastedValue > detrendedSerie[ArraySize(detrendedSerie)-1]){ //Buy }else{ //Sell }
Еще одна интересная функция - знаковый интеграл. Использовать его в текущем виде очень просто, достаточно вызвать функцию, определить пределы и степень многочлена (она может быть небольшой),
, чтобы получить хорошее приближение заданного интеграла. Вы также можете изменить функцию "foo", чтобы интегрировать функции, отличные от f(x) = x.
Как вы внедряете?
Как вы внедряете?
{kind=link}
Рад слышать, что вам это нравится! Пожалуйста, вставьте сюда ссылку, если вы создадите какой-нибудь советник/индикатор с использованием этой библиотеки.
Здравствуйте,Хераджика,
Я пытаюсь воспроизвести статистику теста Дики-Фуллера из кода, которым вы поделились, с помощью других статистических/математических программ. В частности, я использую для этого Wolfram Mathematica.
Пожалуйста, рассмотрите данные из оригинальной статьи, которую вы использовали (из Scribd):
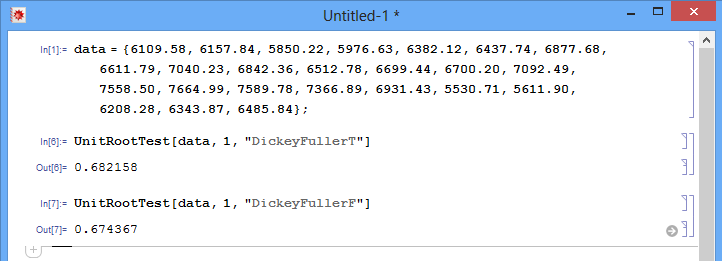
double data[] = {6109.58, 6157.84, 5850.22, 5976.63, 6382.12, 6437.74, 6877.68, 6611.79, 7040.23, 6842.36, 6512.78, 6699.44, 6700.20, 7092.49, 7558.50, 7664.99, 7589.78, 7366.89, 6931.43, 5530.71, 5611.90, 6208.28, 6343.87, 6485.84};
Чтобы получить статистику теста с помощью вашего кода, я удалил комментарий перед функцией Print, как видно из кода ниже:
bool dickeyFuller(double &arr[]) { // n=25 50 100 250 500 >500 // {-2.62, -2.60, -2.58, -2.57, -2.57, -2.57}; double cVal; bool result; int n=ArraySize(arr); double tValue; double corrCoeff; double copyArr[]; double difference[]; ArrayResize(difference,n-1); //--- for(int i=0; i<n-1; i++) { difference[i]=arr[i+1]-arr[i]; } //--- ArrayCopy(copyArr,arr,0,0,n-1); corrCoeff=correlation(copyArr,difference); tValue=corrCoeff*MathSqrt((n-2)/1-MathPow(corrCoeff,2)); //--- if(n<25) { cVal=-2.62; }else{ if(n>=25 && n<50) { cVal=-2.60; }else{ if(n>=50 && n<100) { cVal=-2.58; }else{ cVal=-2.57; } } } Print(tValue); //--- Тестовая статистика ?? result=tValue>cVal; return(result); }
Как уже было сказано, меня больше интересует сама тестовая статистика, а не только вывод теста. В этом смысле, используя код, которым вы поделились, я получаю:
void OnStart() { //--- ИСТОЧНИК: http://pt.scribd.com/doc/80877200/How-to-do-a-Dickey-Fuller-Test-using-Excel# double data[] = {6109.58, 6157.84, 5850.22, 5976.63, 6382.12, 6437.74, 6877.68, 6611.79, 7040.23, 6842.36, 6512.78, 6699.44, 6700.20, 7092.49, 7558.50, 7664.99, 7589.78, 7366.89, 6931.43, 5530.71, 5611.90, 6208.28, 6343.87, 6485.84}; //--- dickeyFuller(data); }
Теперь я печатаю строку со статистикой теста и получаю:
-1.719791886975595Однако в оригинальной статье указано, что t-статистика равна 1,8125.
Однако, когда я использую Wolfram Mathematica на том же наборе данных, я получаю:

У вас есть идеи, что может быть причиной того, что 3 теста дают 3 разных результата?
С уважением,
Malacarne
Здравствуйте! Что касается разницы между результатом из статьи(http://pt.scribd.com/doc/80877200/How-to-do-a-Dickey-Fuller-Test-using-Excel#) и моей реализацией, то
прошу заметить, что на указанном сайте существует некоторая проблема с вытеснением знаков (+, -). Поэтому на самом деле результат, приведенный в статье, равен -1.8125.
Что касается разницы с Wolfram Mathematica, то, возможно, в разных реализациях разных рендеров используются разные критические значения и по-разному вычисляются tValues. Проделав то же самое в Matlab, я получил
другой результат (0.6518).
Однако, если вы попробуете сделать то же самое в excel, это должно показать что-то близкое к -1.8125.
С уважением,
Herajika
Здравствуйте! Что касается разницы между результатом из статьи(http://pt.scribd.com/doc/80877200/How-to-do-a-Dickey-Fuller-Test-using-Excel#) и моей реализацией, то
прошу заметить, что на указанном сайте существует некоторая проблема с вытеснением знаков (+, -). Поэтому на самом деле результат, приведенный в статье, равен -1.8125.
Что касается разницы с Wolfram Mathematica, то, возможно, в разных реализациях разных рендеров используются разные критические значения и по-разному вычисляются tValues. Проделав то же самое в Matlab, я получил
другой результат (0.6518).
Однако, если вы попробуете сделать то же самое в excel, это должно показать что-то близкое к -1.8125.
С уважением,
Herajika
Здравствуйте, Herajika,
Спасибо за ответ. Итак, какую статистику в данном случае следует считать правильной?
Может быть, в оригинальной статье указаны неверные значения тестовой статистики?
С уважением,
Malacarne
P.S.: в системе Mathematica, если я не использую "TestStatistic" в качестве опции, я получаю аналогичные результаты по сравнению с MatLab.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Statistical Functions:
Набор статистических функций, которые позволяют рассчитывать некоторые значения, описывающие таймсерии, такие как корреляция между двумя таймсериями, линейная регрессия, стандартное отклонение и т.д.
Автор: Haruna Nakamura