Что подать на вход нейросети? Ваши идеи... - страница 53
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Некоторые итоги:
- Нейросеть применима только к стационарным, статичным паттернам, которые не имеют отношения к ценообразования
Моё имхо, как вижуНа стационарных рядах все работает и тогда вообще не нужно МО.
Мда уж, все вернулось к тому, с чего начиналась ветка МО в 2016 году - нестационарный ряд не содержить устойчивых статистических характеристик. поэтому все НС суть просто гадание.
Помню когда я это написал дмитриевский бегал по ветке, визжал и требовал, чтобы ему показали это в учебниках....
На стационарных рядах все работает и тогда вообще не нужно МО.
Мда уж, все вернулось к тому, с чего начиналась ветка МО в 2016 году - нестационарный ряд не содержить устойчивых статистических характеристик. поэтому все НС суть просто гадание.
Помню когда я это написал дмитриевский бегал по ветке, визжал и требовал, чтобы ему показали это в учебниках....
Попытки подогнать веса под историю всенепременно терпят крах.
Обучение, оптимизация. Не важно. Любое вмешательство по типу прямого подгона - путь в никуда.
И кажется, что верное направление - это подгонка... с преподвыподвертом.
Основание оному:
Когда входные данные принимают вид от 0 до 1 или -1 до 1, то у нас есть определённый диапазон возможных значений чисел, который ограничен сверху и снизу. Снизу - это количество знаков после запятой.
Мы можем не ограничиваться и оставить вещественные числа как есть, и ограничение будет только техническое - это максимальное количество знаков после запятой согласно терминалам МТ4/МТ5.
А можем ограничить вручную, непример функциями нормализации NormalizeDouble или округления.
И тогда у нас получится диапазон ещё уже.
В результате, мы можем просто перебрать все значения в оптимизаторе, каждому числу присвоить одно из трёх значений: открытия позиции, закрыть, пропустить, ждать, и так далее.
Такой метод даёт абсолютную оптимизацию или абсолютное переобучение, либо стремится к ним. То есть, как таблица Q-обучения, мы в неё тоже записываем результат по каждому паттерну, а потом выбираем, что делать дальше на основе оценок «прошлого».
Результат такого подхода - срыв баланса, пикирование вниз на форварде, и так далее.
Искуственное добавление шума методом уменьшения архитектуры (уменьшение кол-ва нейронов, слоёв и тд) или другими методами есть ни что иное как - костыль.
Какая-то полумера.
И вот поглядывая на очередной результат оптимизатора на графике, где в качестве испытуемого был обычный MLP, я чесал затылок и не мог понять: почему? Почему сраная MLP работает лучше, чем абсолютная подгонка?
В науке машинного обучения есть определение и термин этому явлению (когда на форварде после абсолютной переоптимизации или переобучения идёт выразительный слив). Но речь сейчас не об этом.
Когда сраная MLP открывает позицию, косяченную, запоздалую, пересиживающую, она ненароком пропускает... сливные участки графика. То есть, средняя убыточная позиция 50 на 50 перекрывает участок графика, где мог произойти слив, если открыться в другую сторону. Хороший слив. И переобученная модель обязательно понаоткрывает там.
То есть MLP не просто усредняет веса для всех ситуаций на графике, она по сути сглаживает все форс-мажоры, отчего на форварде выгляддит убедительнее.
Отсюда вывод:
Оптимизировать нужно так, чтобы было как усредление, так и переобучение. То есть, мы всё также должны вычленять участки числовых диапазонов и маркировать их, но и в тоже время - кидать их в котёл, размазывать, замыливать.
Со стороны кажется, что я говорю очевидные вещи, но у меня например, сейчас стоит MLP в извращённом виде, и она показывает результаты лучше, чем обычная MLP, но при этом имеет самодельный модуль частичного абсолютного переобучения.
UPD
Как вариант. Переоптимизация на участке 2012-2021 по EURUSD.
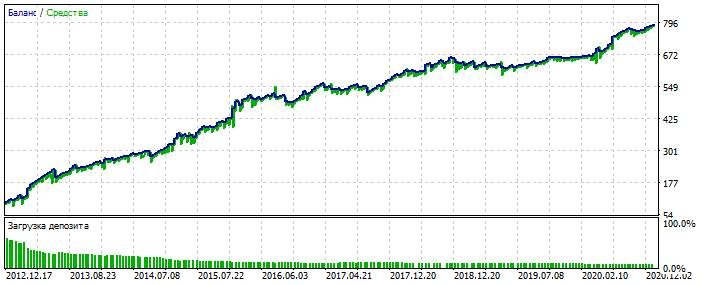
Видно, что график баланса слишком вылизанный, без сильных перекосов. Признак переобучения. Для MLP то с 3-мя нейронами.
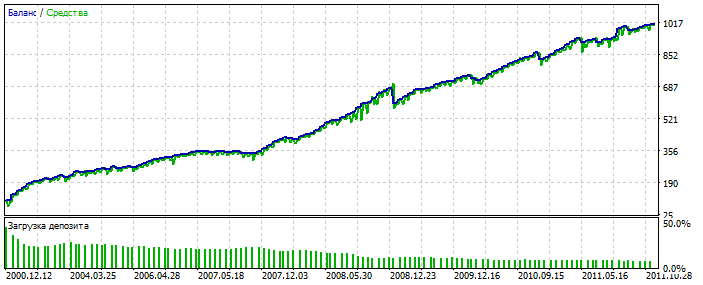
Бектест 2000-2012
Почему-то симпатичней оптимизации. Возможно подхватил аномалию.
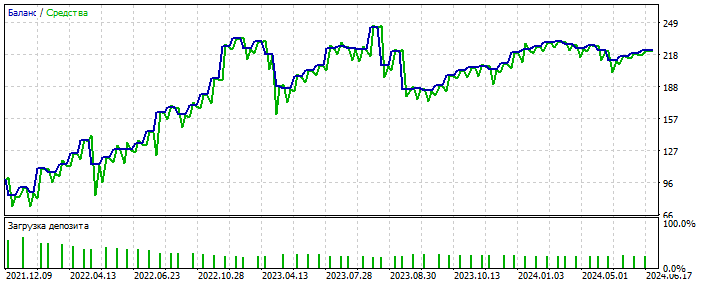
Форвард 2021-2025
Сделок мало, но здесь речь не идёт о полировке системы. Важна суть. Да и заполнить пробел в количестве сделок можно добавив ещё 28 валютных пар и количество первых возрастёт раз в 20. Опять же - не суть.
И что самое важное - такой системе не важны качественные входные данные. Она работает почти на всех: приращения, осциляторы, зигзаги, паттерны, цены, любые.
Пока двигаюсь в этом направлении.
И что самое важное - такой системе не важны качественные входные данные. Она работает почти на всех: приращения, осциляторы, зигзаги, паттерны, цены, любые.
Пока двигаюсь в этом направлении.
Обучаешь подбором весов сети в МТ5-оптимизаторе?
Да. Изредка прибегаю к реальному обучению через обратное распространение ошибки
Да. Изредка прибегаю к реальному обучению через обратное распространение ошибки.
В чем связь оптимизатора из мт5 и обратным распространением ошибки????
Круто
Обойти ограничения МТ5 - это же как оптимизировать пару слоёв по 10 нейронов - обычный оптимизатор МТ5 пожалуйется на ограничение 64bit
Выводы, которые вы заслужили :)
Среди прочего набора слов, я бы отметил лишь то, что чем меньше сделок (наблюдений), тем проще сделать курвафитинг (подогнать под историю), включая новые данные. Это особенность курвафитинга, основанная на статистике, а не движение вперед. 🫠