Обсуждение статьи "Random Decision Forest в обучении с подкреплением"
if(ts<0.4 && CheckMoneyForTrade(_Symbol,lots,ORDER_TYPE_BUY)) { if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)) { updatePolicy(ts); }; }
Можно заменить на это
if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts);
ЗЫ Кстати, Ваш вариант проверки if(OrderSend) будет всегда срабатывать. Т.к. OrderSend не возвращает нуля в случае ошибки.
К сожалению, приходится именно так поступать. Посмотрите эту статью, там интересный способ "передачи" данных Агентам.

- 2018.02.27
- Aleksey Zinovik
- www.mql5.com
К сожалению, приходится именно так поступать. Посмотрите эту статью, там интересный способ "передачи" данных Агентам.
Да, видел, классная статья. Решил не мудрить, потому что быстродействие и так устраивает, проходов здесь много не потребовалось.
Можно заменить на это
ЗЫ Кстати, Ваш вариант проверки if(OrderSend) будет всегда срабатывать. Т.к. OrderSend не возвращает нуля в случае ошибки.
спасибо, так лучше (и про нуль забыл). Позже подправлю
Респект автору за отличный пример реализации ML, нативными средствами MQL и без никаких костылей!
Единственное мое ИМХО, в отношении позиционирования этого примера, как обучения с подкреплением.
Во-первых, мне кажется, что подкрепление должно дозированно воздействовать на память агента, т.е. в данном случае на RDF, а тут оно просто фильтрует сэмплы обучающей выборки и это практически мало чем отличается от подготовки данных для обучения с учителем.
Во-вторых, само обучение не потоковое, непрерывное, а разовое, т.к. после каждого прохода тестера, в процессе оптимизации, вся система обучается заново, я не говорю уже о реалтайм.
Респект автору за отличный пример реализации ML, нативными средствами MQL и без никаких костылей!
Единственное мое ИМХО, в отношении позиционирования этого примера, как обучения с подкреплением.
Во-первых, мне кажется, что подкрепление должно дозированно воздействовать на память агента, т.е. в данном случае на RDF, а тут оно просто фильтрует сэмплы обучающей выборки и это практически мало чем отличается от подготовки данных для обучения с учителем.
Во-вторых, само обучение не потоковое, непрерывное, а разовое, т.к. после каждого прохода тестера, в процессе оптимизации, вся система обучается заново, я не говорю уже о реалтайм.
Все верно, это простой огрубленный пример, больше направленный на знакомство с лесами, нежели на обучение с подкреплением. Думаю, что стоит развить тему в дальнейшем и рассмотреть другие способы подкрепления.
Познавательно, спасибо!
Во-первых, мне кажется, что подкрепление должно дозированно воздействовать на память агента, т.е. в данном случае на RDF, а тут оно просто фильтрует сэмплы обучающей выборки и это практически мало чем отличается от подготовки данных для обучения с учителем.
Во-вторых, само обучение не потоковое, непрерывное, а разовое, т.к. после каждого прохода тестера, в процессе оптимизации, вся система обучается заново, я не говорю уже о реалтайм.
Хочу немного дополнить ответ. Эти 2 пункта тесно связаны. В данной версии представлена вариация на тему experience replay (воспроизведения опыта). Что бы постоянно не апдейтить таблицу и не переобучать лес (что было бы более ресурсозатратно), а переобучаться только в конце на новом опыте. Т.е. это полностью легитимный вариант реинфорсмента и используется, например, в DeepMind для atari игр, правда там все сложнее и используются мини батчи для борьбы с оверфитом.
Для того что бы сделать обучение потоковым, неплохо было бы иметь НС с дообучением, я смотрю в сторону байесовских сетей. Если у вас или у кого-нибудь есть примеры таких сетей на плюсах - буду благодарен :)
Опять же, если нет возможности аппроксиматору дообучаться - то для реалтайм апдейта придется тащить всю матрицу прошлых состояний, и просто переобучаться на всей выборке каждый раз - это не очень изящное и медленное решение (при возрастании кол-ва состояний и признаков)
Также, хотелось бы объединить Q ф-ю и NN ср-вами mql, но пока не хватает понимания зачем ее использовать и велосипедить с вероятностями переходов из состояния в состояние, когда можно ограничиться обычной temporal difference оценкой, как в данной статье. Поэтому, актор-критик сюда больше в тему.
Хочу немного дополнить ответ. Эти 2 пункта тесно связаны. В данной версии представлена вариация на тему experience replay (воспроизведения опыта). Что бы постоянно не апдейтить таблицу и не переобучать лес (что было бы более ресурсозатратно), а переобучаться только в конце на новом опыте. Т.е. это полностью легитимный вариант реинфорсмента и используется, например, в DeepMind для atari игр, правда там все сложнее и используются мини батчи для борьбы с оверфитом.
Для того что бы сделать обучение потоковым, неплохо было бы иметь НС с дообучением, я смотрю в сторону байесовских сетей. Если у вас или у кого-нибудь есть примеры таких сетей на плюсах - буду благодарен :)
Опять же, если нет возможности аппроксиматору дообучаться - то для реалтайм апдейта придется тащить всю матрицу прошлых состояний, и просто переобучаться на всей выборке каждый раз - это не очень изящное и медленное решение (при возрастании кол-ва состояний и признаков)
Также, хотелось бы объединить Q ф-ю и NN ср-вами mql, но пока не хватает понимания зачем ее использовать и велосипедить с вероятностями переходов из состояния в состояние, когда можно ограничиться обычной temporal difference оценкой, как в данной статье. Поэтому, актор-критик сюда больше в тему.
Не спорю, возможно вариант с воспроизведением опыта, в виде пакетного обучения и является легитимной реализацией RL, но он же и является демонстрацией одного из главных ее недостатков - long term credit assignment. Поскольку вознаграждение(подкрепление) в нем происходит с запаздыванием, что м.б. неэффективно.
При этом, проявляется и другой известный недостаток в виде нарушения баланса - exploration vs expluatation, т.к. до конца прохода, весь опыт может только накапливаться и никак не м.б. использован в текущем сеансе эксплуатации. Поэтому ИМХО, что в RL без потокового обучения, скорее всего, ничего хорошего не светит.
По поводу новых примеров сетей, если речь о P-net, о которой я тут упоминал на форуме, то это пока NDA, поэтому поделиться исходниками не могу. Технически, там конечно свои плюсы и минусы, из положительного - высокая скорость обучения, работа с разными объектами данных, дообучение в перспективе, возможно LSTM.
На данный момент есть библиотека для Python и нативная MT4 EA генератора, все на тестовой стадии. Для непосредственного кодирования есть вариант использования встроенного в движек интерпретатора питона, с ним можно рабоатать через блоки кода передаваемые напрямую из советника по именованным каналам.
По поводу чистой MQL реализации RL, я не знаю, интуитивно кажется, что это должно ложиться в динамическое построение решающих деревьев(деревьями политик) или манипуляции с массивами весов между MLP, м.б. возможно доработки на базе соответствующих классов из Alglib...
Молодец Михаил! Процентов 20 пути к успеху прошел. Это похвала, остальные по 3 % прошли. Причем, идешь в правильном направлении.
Многие добавляют в советник с 37-ю индикаторами еще 84 индикатора и думают "вот теперь точно попрет". Наивные.
А теперь по делу. У тебя диалог идет только машина - машина. На мой взгляд, нужно добавить машина - человек - машина.
Обосную. В теории игр, стратегические игры имеют следующие признаки: огромное количество случайных, закономерных и психологически факторов.
Психологических - это типа: есть кино хорошее, есть плохое, а есть индийское. Ход мысли улавливаешь?
Если заинтересовал, спросишь что делать дальше и как это реализовать? Отвечу - пока не знаю, сам пытаюсь найти ответ.
Но если зациклишься только на машинах, будет как с 84 индикаторами: добавляй, не добавляй, будешь ходить кругами.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Random Decision Forest в обучении с подкреплением:
Random Forest (RF) с применением бэггинга — один из самых сильных методов машинного обучения, который немного уступает градиентному бустингу. В статье делается попытка разработки самообучающейся торговой системы, которая принимает решения на основании полученного опыта взаимодействия с рынком.
Можно сказать, что Random forest — это специальный случай бэггинга, когда в качестве базового семейства используются решающие деревья. При этом, в отличие от обычного способа построения решающих деревьев, не используется усечение дерева (pruning). Метод настроен на то, чтобы можно было построить композицию как можно быстрее по большим выборкам данных. Каждое дерево строится специфическим образом. Признак (атрибут) для построения узла дерева выбирается не из общего числа признаков, а из их случайного подмножества. Если мы строим регрессионную модель, то число признаков равно n/3. В случае классификации это √n. Все это является эмпирическими рекомендациями и называется декорреляцией: в разные деревья попадают разные наборы признаков, и деревья обучаются на разных выборках.
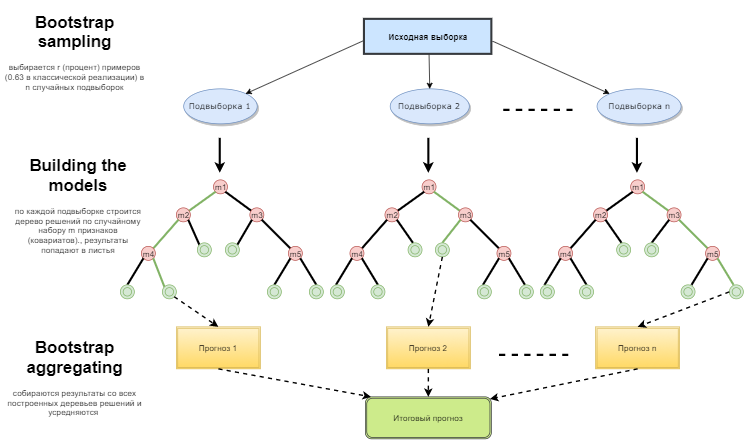
Рис. 1. Схема функционирования случайного лесаАвтор: Maxim Dmitrievsky