Discussão do artigo "Redes Neurais de Terceira Geração: Redes Profundas" - página 2
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Não é uma pergunta para mim. Isso é tudo o que você tem a dizer sobre o artigo?
O que há sobre o artigo? É uma reescrita típica. É a mesma coisa em outras fontes, apenas com palavras ligeiramente diferentes. Até as fotos são as mesmas. Não vi nada de novo, ou seja, de autoral.
Eu queria experimentar os exemplos, mas é uma chatice. A seção é para MQL5, mas os exemplos são para MQL4.
vlad1949
Caro Vlad!
Ao dar uma olhada nos arquivos, você tem uma documentação do R bastante antiga. Seria bom mudar para as cópias anexadas.
vlad1949
Caro Vlad!
Por que você não conseguiu executar no testador?
Eu tenho tudo funcionando sem problemas. Mas o esquema não tem um indicador: o Expert Advisor se comunica diretamente com o R.
Jeffrey Hinton, inventor das redes profundas: "As redes profundas só são aplicáveis a dados em que a relação sinal-ruído é grande. As séries financeiras são tão ruidosas que as redes profundas não são aplicáveis. Nós tentamos e não tivemos sorte".
Ouça suas palestras no YouTube.
Jeffrey Hinton, inventor das redes profundas: "As redes profundas só são aplicáveis a dados em que a relação sinal-ruído é grande. As séries financeiras são tão ruidosas que as redes profundas não são aplicáveis. Nós tentamos e não tivemos sorte".
Ouça as palestras dele no YouTube.
Considerando sua postagem no tópico paralelo.
O ruído é entendido de forma diferente nas tarefas de classificação e na engenharia de rádio. Um preditor é considerado ruidoso se estiver fracamente relacionado (tiver um poder de previsão fraco) à variável de destino. Um significado completamente diferente. Deve-se procurar preditores que tenham poder de previsão para diferentes classes da variável de destino.
Tenho um entendimento semelhante de ruído. As séries financeiras dependem de um grande número de preditores, a maioria dos quais é desconhecida para nós e que introduzem esse "ruído" na série. Usando apenas os preditores disponíveis publicamente, não conseguimos prever a variável-alvo, independentemente das redes ou dos métodos que usamos.
vlad1949
Caro Vlad!
Por que você não conseguiu executar no testador?
Eu tenho tudo funcionando sem problemas. É verdade o esquema sem um indicador: o consultor se comunica diretamente com o R.
llllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllll
Boa tarde, SanSanych.
Portanto, a ideia principal é criar uma multimoeda com vários indicadores.
Caso contrário, é claro, você pode colocar tudo em um Expert Advisor.
Mas se o treinamento, o teste e a otimização forem implementados em tempo real, sem interromper a negociação, a variante com um Consultor especialista será um pouco mais difícil de implementar.
Boa sorte
PS. Qual é o resultado dos testes?
Saudações, SanSanych.
Aqui estão alguns exemplos de determinação do número ideal de clusters que encontrei em um fórum de língua inglesa. Não consegui usar todos eles com meus dados. Muito interessante o pacote 11 "clusterSim".
--------------------------------------------------------------------------------------
Na próxima postagem, cálculos com meus dados
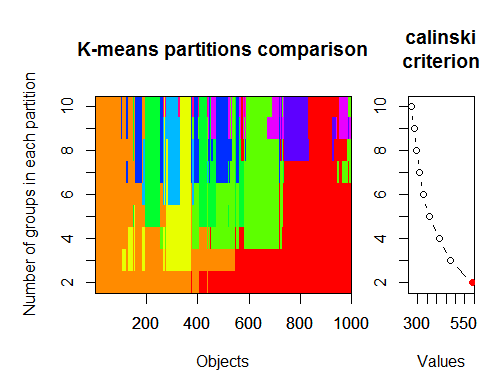
O número ideal de clusters pode ser determinado por vários pacotes e usando mais de 30 critérios de otimização. De acordo com minhas observações, o critério mais usado é ocritério de Calinsky.
Vamos pegar os dados brutos de nosso conjunto do indicador dt . Ele contém 17 preditores, alvo y e corpo de candlestick z.
Nas versões mais recentes dos pacotes "magrittr" e "dplyr", há muitos novos recursos interessantes, um deles é o 'pipe' - %>%. Ele é muito conveniente quando não é necessário salvar resultados intermediários. Vamos preparar os dados iniciais para o agrupamento. Pegue a matriz inicial dt, selecione as últimas 1.000 linhas dela e, em seguida, selecione 17 colunas de nossas variáveis. Obtemos uma notação mais clara, nada mais.
1.
2. Critério de Calinsky: outra abordagem para diagnosticar quantos clusters são adequados aos dados. Nesse caso
tentamos de 1 a 10 grupos.
3) Determine o modelo ideal e o número de clusters de acordo com o Critério de Informação Bayesiano para maximização de expectativa, inicializado por clusterização hierárquica para modelos de mistura gaussiana parametrizados.Modelos de mistura gaussiana