Discussão do artigo "Redes neurais de maneira fácil (Parte 45): Ensinando habilidades para investigar estados"
Como executar testes sem usar o OpenCL?
Porque o processador é compatível com OpenCL, mas a placa de vídeo não é, e nem o teste nem a otimização começam....
Porque o processador suporta o OpenCL, mas a placa de vídeo não, e nem o teste nem a otimização começam....
Bom dia, Oleg.
Essa implementação funciona somente com o OpenCL. Para desativá-la, você precisa reprojetar todo o algoritmo de rede. Mas se ela puder ser executada em um processador, se ele for compatível com OpenCL e os drivers correspondentes estiverem instalados.
Boa tarde, Oleg.
Essa implementação funciona somente com o OpenCL. Para desativá-la, você precisa reprojetar todo o algoritmo de rede. Mas se ele puder ser executado no processador, se ele for compatível com OpenCL e os drivers correspondentes estiverem instalados.
Esse é o erro que recebo (veja a captura de tela). Na captura de tela, é possível ver que a placa de vídeo não é compatível com o OpenCL, mas o processador não tem problemas. Como posso contornar isso e executá-lo em um testador ou otimizador? O que você pode me aconselhar?

Este é o erro que recebo (veja a captura de tela). A captura de tela mostra que a placa de vídeo não é compatível com o OpenCL, mas o processador está funcionando bem. Como posso contornar isso e executá-lo em um testador ou otimizador? O que você pode me aconselhar?
O problema é que você está executando o "tester.ex5". Ele verifica a qualidade dos modelos treinados e você ainda não os tem. Primeiro, você precisa executar o Research.mq5 para criar um banco de dados de exemplos. Em seguida, o StudyModel.mq5, que treinará o codificador automático. O ator é treinado no StudyActor.mq5 ou no StudyActor2.mq5 (função de recompensa diferente). E só então o tester.ex5 funcionará. Observe que, nos parâmetros desse último, você precisa especificar o modelo de ator Act ou Act2. Depende do Expert Advisor usado para estudar o Actor.
Este é o erro que recebo (veja a captura de tela). A captura de tela mostra que a placa de vídeo não é compatível com OpenCL, mas tudo está em ordem com o processador. Como posso contornar isso e executá-lo em um testador ou otimizador? O que você pode me aconselhar?
Você está sem sorte, amigo. Tive o mesmo problema com meu i5-12400
Aparentemente, alguns processadores Intel de 12ª e 13ª geração não suportam o cálculo do fp64.
A Intel secretamente excluiu o fp64 dessas duas gerações de processadores, embora o fp64 esteja de volta na 14ª geração.
O problema é que você executa o "tester.ex5", que verifica a qualidade dos modelos treinados, e você ainda não os tem. Primeiro, você precisa executar o Research.mq5 para criar um banco de dados de exemplos. Em seguida, o StudyModel.mq5, que treinará o codificador automático. O ator é treinado no StudyActor.mq5 ou no StudyActor2.mq5 (função de recompensa diferente). E só então o tester.ex5 funcionará. Observe que, nos parâmetros desse último, você precisa especificar o modelo de ator Act ou Act2. Depende do Expert Advisor usado para estudar o Actor.
Começou a otimizar o Research.
Como resultado, ele escreve o seguinte no registro:
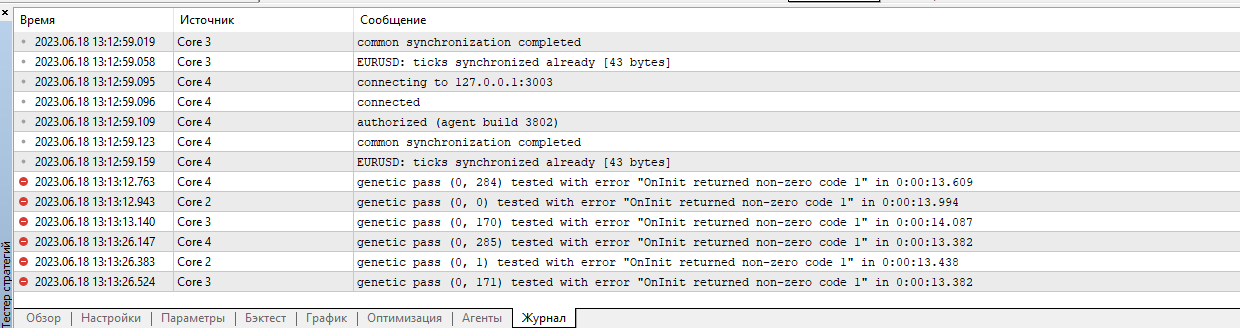
Estou entendendo algo errado novamente?
Você está sem sorte, amigo. Tenho o mesmo problema com meu i5-12400
Aparentemente, alguns Intel de 12ª e 13ª geração não suportam o cálculo fp64.
A Intel secretamente excluiu o fp64 dessas duas gerações de processadores, embora o fp64 esteja de volta na 14ª geração.
Essa versão não usa fp64. Apenas fp32. Eu a testei no Iris Xe i7-1165

Há alguma mensagem no registro do agente de teste? Em alguns estágios da interrupção da inicialização, o EA exibe mensagens.
Limpei todos os registros do testador e executei a otimização da pesquisa para os primeiros 4 meses de 2023 no EURUSD H1.
Executei-a em ticks reais:
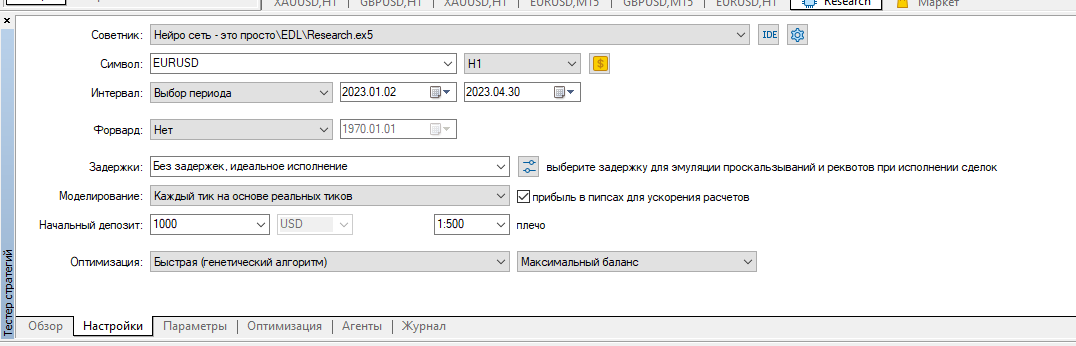
Resultado: apenas 4 amostras, 2 em mais e 2 em menos:

Talvez eu esteja fazendo algo errado, otimizando os parâmetros errados ou algo errado com meu terminal? Não está claro... Estou tentando repetir seus resultados como no artigo...
Os erros começam logo no início.
O conjunto e o resultado da otimização, bem como os registros dos agentes e do testador, estão anexados no arquivo Research.zip.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Redes neurais de maneira fácil (Parte 45): Ensinando habilidades para investigar estados foi publicado:
Aprender habilidades úteis sem uma função de recompensa explícita é um dos principais desafios do aprendizado por reforço hierárquico. Anteriormente, já nos familiarizamos com dois algoritmos para resolver esse problema. Mas a questão da completa exploração do ambiente ainda está em aberto. Neste artigo, é apresentada uma abordagem diferente para o treinamento de habilidades, cujo uso depende diretamente do estado atual do sistema.
É preciso mencionar que os primeiros resultados ficaram aquém das nossas expectativas. Entre os resultados positivos, podemos citar a distribuição relativamente uniforme das habilidades utilizadas no conjunto de testes. No entanto, isso é tudo o que podemos destacar como positivo em nossos testes. Após várias iterações de treinamento do autocodificador e do agente, não conseguimos desenvolver um modelo capaz de gerar lucro no conjunto de treinamento. Evidentemente, o problema estava na incapacidade do autocodificador em prever estados com precisão suficiente. Como resultado, a curva de balanço está longe do resultado desejado.
Para verificar nossa suposição, criamos um EA alternativo de treinamento do agente, chamado "EDL\StudyActor2.mq5". A única diferença entre a versão alternativa e a anterior reside no algoritmo de geração de recompensas. Usamos um ciclo novamente para prever as mudanças no estado da conta. No entanto, desta vez, usamos o indicador de mudança relativa no saldo como recompensa.
O Agente treinado com a função de recompensa modificada apresentou um aumento bastante uniforme no rendimento durante todo o período de teste.
Autor: Dmitriy Gizlyk