市場モデル:スループット一定 - ページ 10 1...34567891011121314151617...28 新しいコメント hrenfx 2010.10.10 09:43 #91 OlegTs: 1.元のアイデアを公理とするならば、そもそも完璧なアーカイバが必要であり、我々はそこから月と同じくらい遠いところにいるhttp://unseal.narod.ru/molekula_dnk.html, そうですね、データに含まれる情報量を推し量ることすら非常に難しいです。既存の圧縮アルゴリズム(損失あり・なし)は、完璧とは言い難い。 2.このアイデアを確認するために、テスターでティックフローのモデリングと同様の相場モデルを、きちんとした時間間隔で作り、このフローをベースに分足を組み、圧縮して、実際のものと比較する必要があると思います。ある時点で、実験の純度が途切れることがあります。 これは、上記で行いました。その結果、CvRは全くSBでないことがわかる。 Markowitzに限らず、最適なポートフォリオを構築するための推論では、価格はランダムであるという記述を参照し続ける。 ここで気になるのは、市場分析に必要な最小限のペアの数でしょうか。hrenfxが これらのペアを見つけることができれば、私は非常に感謝することになります。このトピックに言及するとhttps://www.mql5.com/ru/forum/114579 メジャーを使えば十分なのか、それともクラスタの最大数の機器が必要なのか、この疑問は繰り返し提起されることになります。 任意のBPの集合の中からメジャーを簡単に見つける方法がある。BPの名前は必要ない。全てはBPそのものの分析から。 この方法は、FOREXではすべての情報がメジャーに含まれていることを示しています。メジャーは一意に定義されない、つまり同じ情報量を含む複数のメジャーの集合が存在する。例えば、こんな感じです。 eurusd, audusd, gbpusd, usdjpy, usdchf, usdcad, ...です。 eurjpy, audjpy, gbpjpy, usdjpy, chfjpy, cadjpy, ...です。 削除済み 2010.10.10 10:00 #92 hrenfx: そうですね、データに含まれる情報量を推し量ることすら非常に難しいです。既存の圧縮アルゴリズム(損失あり、損失なし)は完璧とは言い難い。 圧縮アルゴリズムは、情報を扱うアルゴリズムではなく、最適な符号化を行うアルゴリズムである。符号化理論による情報の概念は、従来の情報の概念とは全く異なるものである。圧縮アルゴリズムでは、情報量を評価するのではなく、このデータはこの時間間隔でこの符号化方式にどれだけ対応しているかという符号化の最適性のみを評価します。正規分布で生成された(擬似)ランダムなデータは、選択した符号化方式(ベース - LZ)によく対応し、その結果得られる符号量は小さくなり、ここでの情報は百五十キロメートルにも及ばないのです。そして、それに対応するBPとSBを比較した結論が根本的に間違っている。 すでに何人かの方が、別の言葉で書いてくださっています。ミシェックも同じことを言ってたね。 結局はくだらない。 情報量を評価するのであれば情報を評価する。そして、引用を圧縮しないこと。 Oleg 2010.10.10 10:12 #93 gip: 圧縮アルゴリズムは、情報を扱うアルゴリズムではなく、最適な符号化を行うアルゴリズムである。符号化理論による情報の概念は、従来の情報の概念とは全く異なるものである。圧縮アルゴリズムでは、情報量を評価するのではなく、「このデータはこの時点でこの符号化方式にどれだけ対応しているか」という符号化の最適性だけを評価することになります。正規分布で生成されたランダムデータは、選択した符号化方式(ベース - LZ)によく対応し、対応する結果得られる符号量は少なく、ここでの情報は百五十キロメートルにも及ばないのです。そして、それに対応するBPとSBを比較した結論は根本的に間違っています。 すでに何人かの方が、別の言葉で書いてくださっています。ミシェックも同じことを言ってたね。 結局はくだらない。 情報量を評価するのであれば情報を評価する。そして、引用を圧縮しないこと。 ところで、このrarがなぜ故障したのか、考えたのですが、問題は単純な選択ではないのでしょうか? Андрей 2010.10.10 10:16 #94 hrenfx: そうですね、データに含まれる情報量を推し量ることすら非常に難しいです。既存の圧縮アルゴリズム(損失あり、損失なし)は完璧とは言い難い。 ところで、因子分析についてはどうでしょうか? この方式を覚えていますか? . . サンプルデータに対する要因の影響度を示している。 すなわち、図によれば、第1、第2、第3の因子を合わせて8.5個の「重さ」を持つ場合。 となると、他のものはもっと重くなる。 . という別のチャートをどこかで見たことがあるかもしれません。 を、左側にパーセンテージで表示します。その図には ファクターカーブのN点が、これまでのファクターカーブに対してどれだけ累積しているか は、その変動を説明します。 . そして、その後にどうするかという地味な問題...。 Oleg 2010.10.10 10:20 #95 jartmailru: そして、それをどうするかという地味な問題...。 しかし、電気は、彼らもどうしたらいいのかわからなかった......。 Alexandr Bryzgalov 2010.10.10 10:21 #96 OlegTs: でも、電気もどうしたらいいかわからないし......」。 しかし、それは電気ではない ) Alexandr Bryzgalov 2010.10.10 10:21 #97 jartmailru: そして、それをどうするかという地味な問題...。 アフターターにはその答えがわからない。) Oleg 2010.10.10 10:23 #98 の人たち!!みんな芸術が好きでここにいるのか!!誰か反論してくれませんか? Andrei01 2010.10.10 10:29 #99 joo: クリエイティビティを評価する人はいないでしょう。それだけでなく、こんな質問も出てきそうです。"「セールスマンについて」問題を解決することが、そのままFXと何の関係があるのか?" 静かに生地を切りましょう。なぜこの教育活動が必要なのですか?- という問いかけは、レトリックです。 クリエイティブはクリエイティブではない。もちろん、やろうと思えば、そして少し想像力を働かせれば、何にでも応用できる。世界は閉じたシステムであり、相互につながっているのだから。 問題は、非建設的な創造性ではなく、単なる疑似科学の氾濫をどうふるいにかけるかだ。それはとてもシンプルなことです。ほとんどの場合、これを行うには、単純な質問に答えようとするのに十分な - どのようにこの問題の解決は、FXに直接することができます。 さて、もし合理的な答えがなく、代わりに科学に近い創造性を残酷にしたという非難があるのなら、もう一つ当然の疑問が生じます。誰が何のためにこのようなアウトリーチ活動を必要としているのか?:) Oleg 2010.10.10 10:30 #100 OlegTs: の人たち!!みんな芸術が好きでここにいるのか!!誰か反論してくれませんか? 誰も何も言わないから、楽しく続けられるんだ:))))) 1...34567891011121314151617...28 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
1.元のアイデアを公理とするならば、そもそも完璧なアーカイバが必要であり、我々はそこから月と同じくらい遠いところにいるhttp://unseal.narod.ru/molekula_dnk.html,
そうですね、データに含まれる情報量を推し量ることすら非常に難しいです。既存の圧縮アルゴリズム(損失あり・なし)は、完璧とは言い難い。
2.このアイデアを確認するために、テスターでティックフローのモデリングと同様の相場モデルを、きちんとした時間間隔で作り、このフローをベースに分足を組み、圧縮して、実際のものと比較する必要があると思います。ある時点で、実験の純度が途切れることがあります。
これは、上記で行いました。その結果、CvRは全くSBでないことがわかる。
Markowitzに限らず、最適なポートフォリオを構築するための推論では、価格はランダムであるという記述を参照し続ける。
ここで気になるのは、市場分析に必要な最小限のペアの数でしょうか。hrenfxが これらのペアを見つけることができれば、私は非常に感謝することになります。このトピックに言及するとhttps://www.mql5.com/ru/forum/114579 メジャーを使えば十分なのか、それともクラスタの最大数の機器が必要なのか、この疑問は繰り返し提起されることになります。
任意のBPの集合の中からメジャーを簡単に見つける方法がある。BPの名前は必要ない。全てはBPそのものの分析から。
この方法は、FOREXではすべての情報がメジャーに含まれていることを示しています。メジャーは一意に定義されない、つまり同じ情報量を含む複数のメジャーの集合が存在する。例えば、こんな感じです。
そうですね、データに含まれる情報量を推し量ることすら非常に難しいです。既存の圧縮アルゴリズム(損失あり、損失なし)は完璧とは言い難い。
圧縮アルゴリズムは、情報を扱うアルゴリズムではなく、最適な符号化を行うアルゴリズムである。符号化理論による情報の概念は、従来の情報の概念とは全く異なるものである。圧縮アルゴリズムでは、情報量を評価するのではなく、このデータはこの時間間隔でこの符号化方式にどれだけ対応しているかという符号化の最適性のみを評価します。正規分布で生成された(擬似)ランダムなデータは、選択した符号化方式(ベース - LZ)によく対応し、その結果得られる符号量は小さくなり、ここでの情報は百五十キロメートルにも及ばないのです。そして、それに対応するBPとSBを比較した結論が根本的に間違っている。
すでに何人かの方が、別の言葉で書いてくださっています。ミシェックも同じことを言ってたね。
結局はくだらない。
情報量を評価するのであれば情報を評価する。そして、引用を圧縮しないこと。
圧縮アルゴリズムは、情報を扱うアルゴリズムではなく、最適な符号化を行うアルゴリズムである。符号化理論による情報の概念は、従来の情報の概念とは全く異なるものである。圧縮アルゴリズムでは、情報量を評価するのではなく、「このデータはこの時点でこの符号化方式にどれだけ対応しているか」という符号化の最適性だけを評価することになります。正規分布で生成されたランダムデータは、選択した符号化方式(ベース - LZ)によく対応し、対応する結果得られる符号量は少なく、ここでの情報は百五十キロメートルにも及ばないのです。そして、それに対応するBPとSBを比較した結論は根本的に間違っています。
すでに何人かの方が、別の言葉で書いてくださっています。ミシェックも同じことを言ってたね。
結局はくだらない。
情報量を評価するのであれば情報を評価する。そして、引用を圧縮しないこと。
そうですね、データに含まれる情報量を推し量ることすら非常に難しいです。既存の圧縮アルゴリズム(損失あり、損失なし)は完璧とは言い難い。
ところで、因子分析についてはどうでしょうか?
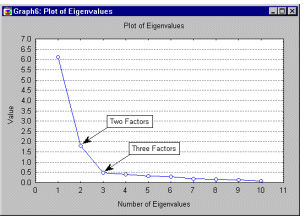
この方式を覚えていますか?
.
.
サンプルデータに対する要因の影響度を示している。
すなわち、図によれば、第1、第2、第3の因子を合わせて8.5個の「重さ」を持つ場合。
となると、他のものはもっと重くなる。
.
という別のチャートをどこかで見たことがあるかもしれません。
を、左側にパーセンテージで表示します。その図には
ファクターカーブのN点が、これまでのファクターカーブに対してどれだけ累積しているか
は、その変動を説明します。
.
そして、その後にどうするかという地味な問題...。
そして、それをどうするかという地味な問題...。
でも、電気もどうしたらいいかわからないし......」。
そして、それをどうするかという地味な問題...。
クリエイティビティを評価する人はいないでしょう。それだけでなく、こんな質問も出てきそうです。"「セールスマンについて」問題を解決することが、そのままFXと何の関係があるのか?"
静かに生地を切りましょう。なぜこの教育活動が必要なのですか?- という問いかけは、レトリックです。
クリエイティブはクリエイティブではない。もちろん、やろうと思えば、そして少し想像力を働かせれば、何にでも応用できる。世界は閉じたシステムであり、相互につながっているのだから。
問題は、非建設的な創造性ではなく、単なる疑似科学の氾濫をどうふるいにかけるかだ。それはとてもシンプルなことです。ほとんどの場合、これを行うには、単純な質問に答えようとするのに十分な - どのようにこの問題の解決は、FXに直接することができます。
さて、もし合理的な答えがなく、代わりに科学に近い創造性を残酷にしたという非難があるのなら、もう一つ当然の疑問が生じます。誰が何のためにこのようなアウトリーチ活動を必要としているのか?:)
の人たち!!みんな芸術が好きでここにいるのか!!誰か反論してくれませんか?