Cosa inserire nell'ingresso della rete neurale? Le vostre idee... - pagina 53
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Alcuni riassunti:
- La rete neurale è applicabile solo a modelli statici e stazionari che non hanno nulla a che fare con la determinazione dei prezzi.
La mia opinione, per come la vedo ioSu serie stazionarie tutto funziona e quindi non c'è alcun bisogno di MO.
Beh, tutto torna al punto in cui il thread sulla MO è iniziato nel 2016: le serie non stazionarie non contengono caratteristiche statistiche stabili, quindi tutte le NS sono solo congetture.
Ricordo che quando l'ho scritto Dmitrievsky correva in giro per il thread, strillando e chiedendo che gli venisse mostrato nei libri di testo....
Sui filari fissi tutto funziona e quindi non è necessario il MO.
Bene, tutto torna al punto in cui è iniziato il thread sul MO nel 2016: le serie non stazionarie non contengono caratteristiche statistiche stabili. pertanto, tutti i NS sono solo congetture.
Ricordo che quando ho scritto questo Dmitrievsky correva in giro per il thread, strillando e chiedendo che gli venisse mostrato questo nei libri di testo....
I tentativi di adattare i pesi alla storia sono destinati a fallire. Allenamento, ottimizzazione. Non importa.
Qualsiasi intervento come l'adattamento diretto è un percorso che non porta da nessuna parte. E sembra che la direzione giusta sia il fitting....
La base: quando i dati in ingresso assumono la forma da 0 a 1 o da -1 a 1, abbiamo una certa gamma di valori numerici possibili, che è limitata dall'alto verso il basso.
La parte inferiore è il numero di cifre decimali. Non possiamo limitare e lasciare i numeri reali così come sono, e la limitazione sarà solo tecnica - è il numero massimo di cifre decimali secondo i terminali MT4/MT5. Oppure possiamo limitarlo manualmente, ad esempio con le funzioniNormalizeDouble o Rounding.
Di conseguenza, possiamo semplicemente cercare tutti i valori nell'ottimizzatore, assegnare uno dei tre valori a ciascun numero: posizione di apertura, chiusura, salto, attesa e così via. Questo metodo fornisce un'ottimizzazione assoluta o una riqualificazione assoluta, o tende a farlo.
Cioè, come una tabella di apprendimento Q, registriamo anche il risultato di ogni schema in essa, e poi scegliamo cosa fare dopo in base alle valutazioni "passate". Il risultato di questo approccio è una rottura dell'equilibrio, una discesa in avanti, e così via.
L'aggiunta artificiale di rumore attraverso la riduzione dell'architettura (riduzione del numero di neuroni, strati, ecc.) o altri metodi non è altro che una stampella. Una specie di mezza misura. E guardando il risultato dell'ottimizzatore successivo sul grafico, in cui il soggetto di prova era una MLP normale, mi sono grattato la testa e non riuscivo a capire: perché?
Perché una fottuta MLP funziona meglio dell'overfitting assoluto? Nella scienza dell'apprendimento automatico esiste una definizione e un termine per questo fenomeno (quando si verifica uno svuotamento espressivo in avanti dopo una sovraottimizzazione assoluta o un overtraining). Ma non è di questo che stiamo parlando ora.
Quando una fottuta MLP apre una posizione, una posizione inceppata, tardiva, sovraservita, inavvertitamente manca ... le aree di prugna del grafico. Cioè, la posizione mediamente perdente si sovrappone al 50/50 alla porzione di grafico in cui si sarebbe potuta verificare la prugna se fosse stata aperta dall'altra parte. Una bella prugna.
In altre parole, MLP non solo calcola la media dei pesi per tutte le situazioni sul grafico, ma essenzialmente smussa tutte le cause di forza maggiore, il che lo fa apparire più convincente in avanti. Da qui la conclusione: l'ottimizzazione dovrebbe essere fatta in modo tale che ci siano sia la media che la riqualificazione.
Cioè, abbiamo ancora bisogno di estrarre parti di intervalli numerici ed etichettarli, ma allo stesso tempo - di gettarli nella caldaia, spalmare, sfocare. Dall'esterno sembra che stia dicendo cose ovvie, ma io, per esempio, ora ho MLP in una forma pervertita, e mostra risultati migliori rispetto al solito MLP, ma ha un modulo fatto in casa di sovrallenamento parziale assoluto.
AGGIORNAMENTO
Come opzione.
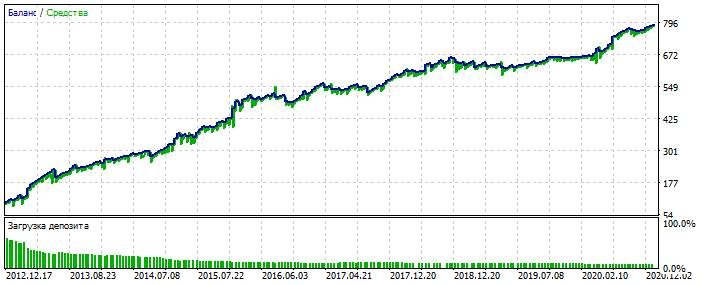
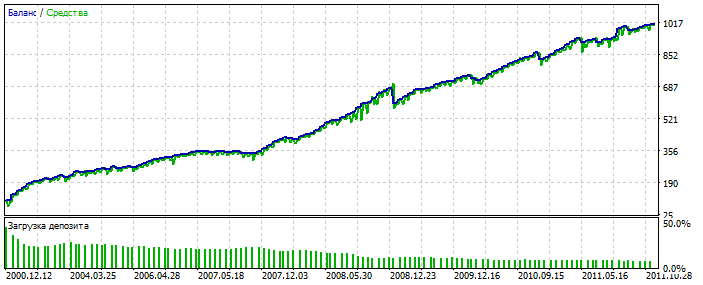
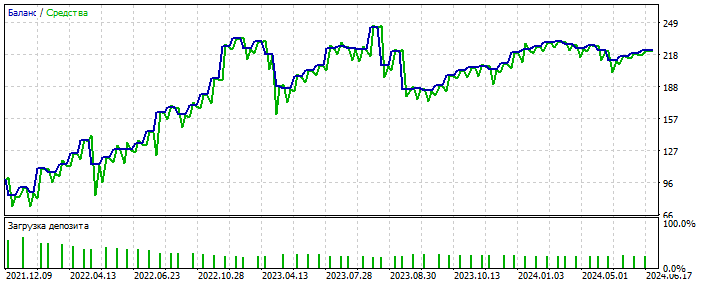
Sovra-ottimizzazione sul grafico EURUSD 2012-2021. Si può notare che il grafico di equilibrio è troppo lucido, senza una grave skewness. Un segno di sovraottimizzazione.
Per MLP è con 3 neuroni. Bektest 2000-2012 Per qualche motivo è più bello dell'ottimizzazione.
Probabilmente ha individuato un'anomalia. Forward 2021-2025 Le prove sono poche, ma qui non stiamo parlando di lucidare il sistema. L'essenza è importante. È possibile colmare il divario nel numero di operazioni aggiungendo altre 28 coppie di valute e il numero delle prime aumenterà di 20 volte. Ancora una volta, non è questo il punto.
E la cosa più importante è che questo sistema non ha bisogno di dati di input qualitativi.
Funziona su quasi tutto: incrementi, oscillatori, zigzag, modelli, prezzi, qualsiasi cosa. Mi sto ancora muovendo in questa direzione.
E la cosapiù importante è che un sistema di questo tipo non ha bisogno di dati di ingresso di alta qualità.
Funziona su quasi tutto: incrementi, oscillatori, zigzag, pattern, prezzi, qualsiasi cosa. Per ora mi sto muovendo in questa direzione.
Ti alleni selezionando i pesi della rete in MT5-optimiser?
Sì. Occasionalmente ricorro all'apprendimento reale attraverso la propagazione degli errori.
Sì. Di tanto in tanto ricorro all'apprendimento reale attraverso la propagazione degli errori.
Qual è la relazione tra l'ottimizzatore di mt5 e la back propagation di error?????
Cool Bypassare le limitazioni di MT5 è come ottimizzare una coppia di strati di 10 neuroni: un normale ottimizzatore MT5 si lamenterà della limitazione a 64 bit.
Conclusioni meritate :)
Tra le altre cose, vorrei solo far notare che meno sono le transazioni (osservazioni), più è facile fare curwafitting (adattamento alla storia) includendo nuovi dati. Questa è una caratteristica del curwafitting basata sulla statistica, non sul progresso. 🫠