Y a-t-il un modèle dans ce chaos ? Essayons de le trouver ! Apprentissage automatique sur l'exemple d'un échantillon spécifique. - page 11
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
C'est bien là le problème, il est meilleur d'un facteur 2 que sur les caractéristiques 5000+.
Il s'avère que toutes les autres puces 5000+ ne font qu'empirer le résultat. Bien que si vous les sélectionnez, vous en trouverez sûrement qui s'améliorent.
Il est intéressant de comparer ce que votre modèle montrera sur ces 2.
J'ai une attente mat. un peu plus d'un, bénéfice dans les 5 mille, la précision écrit 51% - c'est à dire que les résultats sont clairement pires.
Oui, et sur l'échantillon test, j'ai obtenu une perte dans les 100 modèles.J'ai mat. l'attente un peu plus d'un, le bénéfice dans 5 mille, la précision dit 51% - c'est à dire, les résultats sont nettement plus mauvais.
Oui, et sur l'échantillon test, il y a eu une perte dans les 100 modèles.Mais sur le premier, il y a aussi une perte.
Sur le deuxième échantillon H1 ? Je m'améliore sur celui-ci.
Et sur le premier, je perds aussi.
Oui, je parle de l'échantillon H1. Je suis initialement formé sur train.csv, je m'arrête sur test.csv et je fais un contrôle indépendant sur exam.csv, de sorte que la variante avec deux colonnes échoue sur test.csv. Les variantes d'hier ont également perdu du terrain, mais il y en a aussi qui ont gagné un peu d'argent.
Alors, quel genre de diagrammes miraculeux avez-vous ?Et voici comment le valving progresse avec la formation sur 20000 lignes en 10000 lignes. En d'autres termes, le graphique ne montre pas 2 années, mais 5. 2 années de drawdown, puis une autre année sans profit, à cause de laquelle les gains moyens ont à nouveau chuté à 0,00002 par transaction. Ce n'est pas non plus une bonne chose pour le commerce.
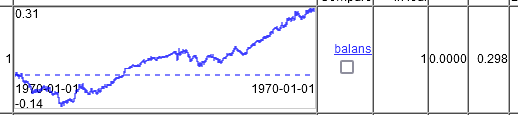
Seulement sur 2 colonnes de temps.
Les mêmes paramètres sur toutes les colonnes de plus de 5000. Légèrement mieux. 0,00003 par transaction.
Profit 0,20600, en moyenne 0,00004 par transaction. En rapport avec l'écart
Oui, le chiffre est déjà impressionnant. Cependant, l'objectif est marqué à la vente, et là, toute la période sur un grand TF est à la vente, je pense que cela améliore aussi artificiellement le résultat.
C'est plus que 0.00002 sur toutes les colonnes, mais comme je l'ai dit plus tôt " Le spread, les slippages, etc. absorberont tout le gain ". Teriminal montre le spread minimum par barre (c'est-à-dire pendant toute l'heure), mais au moment d'un trade il peut être de 5 à 10 pts, et sur les news il peut être de 20 et plus.
Donc la majoration que j'ai est prise sur des barres de minutes, les spreads s'élargissent généralement sur une période de temps, c'est-à-dire que dans une minute il y aura probablement un grand spread tout le temps, ou est-ce que ce n'est pas le cas maintenant ? Je n'ai même pas encore compris comment fonctionne le spread dans 5 - je le trouve plus pratique pour les tests dans 4.
Vous devriez chercher des modèles avec des gains moyens d'au moins 0,00020 par transaction. Ensuite, en trading réel, vous pouvez obtenir 0,00010. Ceci est pour l'EURUSD, sur d'autres paires comme AUD NZD même 50 pts ne seront pas suffisants, les spreads sont de 20-30 pts.
Je suis d'accord. Le premier exemple de ce fil de discussion donne une espérance de 30 pips. C'est pourquoi je reste d'avis que la marge doit être intelligente.
Il s'agit encore une fois du meilleur graphique sur l'échantillon de l'examen. Comment choisir les paramètres qui donneront le meilleur équilibre sur l'échantillon de l'examen est une question sans solution. Vous choisissez par test. Je me suis formé sur traine+test. En gros, ce que vous avez comme examen, je l'ai comme test.
Je pense que vous devriez commencer par faire en sorte que la majorité de l'échantillon passe le seuil de sélection. De plus, il peut être judicieux de choisir le modèle le moins entraîné de tous - il a moins d'ajustement.
Et voici comment on avance avec l'entraînement sur 20000 lignes dans 10000 lignes. C'est-à-dire que sur le graphique, ce ne sont pas 2 ans, mais 5. 2 années de drawdown, puis une autre année sans profit, ce qui fait que les gains moyens sont tombés à 0,00002 par transaction. Ce n'est pas bon non plus pour le commerce.
Seulement sur 2 colonnes de temps.
Les mêmes paramètres sur toutes les colonnes de plus de 5000. Légèrement mieux. 0,00003 par transaction.
Cependant, il s'avère que les autres prédicteurs peuvent également être utiles. Vous pouvez essayer de les ajouter en groupes, vous pouvez d'abord passer au crible les corrélations et les réduire légèrement.
En ce qui concerne la matrice d'espérance, il est peut-être plus rentable dans cette stratégie d'entrer non pas à l'ouverture de la bougie, mais à 30 pips du prix d'ouverture - les bougies sans queue sont rares.
Donc la marge que j'ai est prise sur des barres de minutes, les écarts s'élargissent généralement sur une période de temps, c'est-à-dire que dans une minute il y aura probablement un grand écart tout le temps, ou est-ce que ce n'est pas le cas maintenant ? Je n'ai même pas encore compris comment fonctionne l'écart dans 5 - pour moi, c'est plus pratique pour les tests dans 4.
Et sur M1 aussi, l'écart minimum pour le temps de barre est maintenu. Sur les comptes ECH, presque toutes les barres M1 ont 0,00001...0,00002 rarement plus. Toutes les barres seniors sont construites à partir de M1, c'est-à-dire que le même écart minimum sera respecté. Vous devez ajouter 4 pts de commission par tour (d'autres centres de courtage peuvent avoir d'autres commissions).
Et pourtant, il s'avère que les autres prédicteurs peuvent également être utiles. Vous pouvez essayer de les ajouter en groupes, vous pouvez d'abord passer au crible les corrélations et les réduire légèrement.
Peut-être devrions-nous les sélectionner. Mais si le fait d'ajouter 5000+ à 2 n'apporte qu'une petite amélioration, il peut être plus rapide de sélectionner 10 éléments par la force brute avec l'entraînement au modèle. Je pense que ce sera plus rapide que d'attendre la corrélation pendant 24 heures. Il est seulement nécessaire d'automatiser le ré-entraînement dans une boucle directement à partir du terminal.
Est-ce que katbusta n'a pas une version DLL ? La DLL peut être appelée directement depuis le terminal. Il y avait un article avec des exemples ici. https://www.mql5.com/ru/articles/18 et https://www.mql5.com/ru/articles/5798.
Peut-être devrions-nous sélectionner. Mais si l'ajout de plus de 5000 pièces aux 2s apporte une petite amélioration, il pourrait être plus rapide de sélectionner 10 pièces par la force brute avec l'entraînement du modèle. Je pense que ce serait plus rapide que d'attendre la corrélation pendant 24 heures.
Oui, il est préférable de procéder par groupes au début - vous pouvez faire, disons, 10 groupes et vous entraîner avec leurs combinaisons, évaluer les modèles, éliminer les groupes les moins performants et regrouper les groupes restants, c'est-à-dire réduire le nombre de prédicteurs dans le groupe et s'entraîner à nouveau. J'ai déjà utilisé cette méthode dans le passé - l'effet est là, mais encore une fois, il n'est pas rapide.
Il suffit d'automatiser le ré-entraînement dans une boucle directement à partir du terminal.
catbust n'a-t-il pas une version DLL ? La DLL peut être appelée directement depuis le terminal. Il y avait un article avec des exemples ici. https://www.mql5.com/ru/articles/18 et https://www.mql5.com/ru/articles/5798.
Heh, ce serait bien d'avoir un contrôle total de l'apprentissage via le terminal, mais d'après ce que j'ai compris, il n'y a pas de solution prête à l'emploi. Il existe une bibliothèque catboostmodel.dll qui ne fait qu'appliquer le modèle, mais je ne sais pas comment l'implémenter dans MQL5. En théorie, bien sûr, il est possible de créer une interface sous la forme d'une bibliothèque pour l'apprentissage - le code est ouvert, mais je n'en ai pas les moyens.
Oui, il est préférable de commencer par des groupes - vous pouvez créer, par exemple, 10 groupes et les entraîner en combinaisons, évaluer les modèles, éliminer les groupes les moins performants et regrouper les groupes restants, c'est-à-dire réduire le nombre de prédicteurs dans le groupe et les entraîner à nouveau. J'ai déjà utilisé cette méthode - l'effet est là, mais encore une fois pas rapide.
Je propose autre chose. Nous ajoutons des caractéristiques au modèle une par une. Et nous sélectionnons les meilleurs.
1) Entraîner 5000+ modèles sur une caractéristique : chacune des 5000+ caractéristiques. Prendre le meilleur modèle du test.
2) Entraîner (5000+ -1) modèles sur 2 caractéristiques : la première meilleure caractéristique et( 5000+ -1) les autres. Trouver la deuxième meilleure caractéristique.
3) Entraîner (5000+ -2) modèles sur 3 caractéristiques : sur la première, la deuxième meilleure caractéristique et( 5000+ -2) celles restantes. Trouver le troisième meilleur modèle.
Répétez l'opération jusqu'à ce que le modèle s'améliore.
J'ai généralement cessé d'améliorer le modèle après avoir ajouté 6 à 10 caractéristiques. Vous pouvez également aller jusqu'à 10-20 ou autant de caractéristiques que vous souhaitez ajouter.
Mais je pense que la sélection des caractéristiques par test consiste à adapter le modèle à la section test des données. Il existe une variante de sélection par trayne avec un poids de 0,3 et test avec un poids de 0,7. Mais je pense qu'il s'agit également d'un ajustement.
Je voulais faire le roll forward, puis l'ajustement sera pour de nombreuses sections de test, cela prendra plus de temps pour compter, mais il me semble que c'est la meilleure option.
Bien que vous n'ayez pas d'automatisation pour faire fonctionner les catbusters.... 50+ milliers de fois, il sera difficile d'entraîner à nouveau les modèles manuellement pour obtenir 10 caractéristiques.C'est en gros la raison pour laquelle je préfère mon métier au catbust. Même s'il est 5 à 10 fois plus lent que Cutbust. Vous avez eu un modèle pendant 3 minutes, j'en ai eu 22.
Ce n'est pas ce que je suggère. Nous ajoutons des caractéristiques au modèle une par une. Et nous sélectionnons les meilleures.
1) Entraîner 5000+ modèles sur une caractéristique : chacune des 5000+ caractéristiques. Prendre le meilleur modèle du test.
2) Entraîner (5000+ -1) modèles sur 2 caractéristiques : la première meilleure caractéristique et( 5000+ -1) les autres. Trouver la deuxième meilleure caractéristique.
3) Entraîner (5000+ -2) modèles sur 3 caractéristiques : sur la première, la deuxième meilleure caractéristique et( 5000+ -2) celles restantes. Trouver le troisième meilleur modèle.
Répétez l'opération jusqu'à ce que le modèle s'améliore.
J'ai généralement cessé d'améliorer le modèle après avoir ajouté 6 à 10 caractéristiques. Vous pouvez également aller jusqu'à 10-20 ou autant de caractéristiques que vous souhaitez ajouter.
Les approches peuvent être différentes - leur essence est la même en général, mais l'inconvénient est bien sûr commun - des coûts de calcul trop élevés.
Mais je pense que la sélection des caractéristiques par test est un ajustement du modèle à la section test des données. Il existe une variante de la sélection par trayne avec un poids de 0,3 et test avec un poids de 0,7. Mais je pense qu'il s'agit également d'un ajustement.
J'aimerais faire avancer la valorisation, l'ajustement se fera alors pour de nombreuses sections de test, cela prendra plus de temps à calculer, mais il me semble que c'est la meilleure option.
C'est pourquoi je cherche un grain rationnel à l'intérieur de la caractéristique pour justifier sa sélection. Jusqu'à présent, j'ai opté pour la fréquence de récurrence des événements et le déplacement de la probabilité de la classe. En moyenne, l'effet est positif, mais cette méthode évalue en fait la première division, sans tenir compte des prédicteurs corrélatifs. Mais je pense que vous devriez également essayer la même méthode pour la deuxième division, en supprimant de l'échantillon les lignes sur les scores des prédicteurs avec une forte prédisposition négative.
Bien que vous n'ayez pas d'automatisation pour exécuter catbusters.... 50+ milliers de fois, il serait difficile d'entraîner à nouveau les modèles manuellement pour obtenir 10 traits.
C'est en gros la raison pour laquelle je préfère mon craft au catbust. Même s'il est 5 à 10 fois plus lent que Cutbust. Vous aviez un modèle qui prenait 3 minutes à compter, j'en avais 22.
Lisez tout de même mon article.... Maintenant, tout fonctionne de manière semi-automatique - les tâches sont générées et le bootnik est lancé (y compris les tâches relatives au nombre de caractéristiques à utiliser dans l'apprentissage, c'est-à-dire que vous pouvez générer toutes les variantes en une seule fois et les lancer). Il faut essentiellement apprendre au terminal à exécuter le fichier bat, ce qui est possible je pense, et contrôler la fin de la formation, puis analyser les résultats et exécuter une autre tâche sur la base des résultats.
Ce n'est qu'en modifiant le taux d'apprentissage qu'il a pu obtenir deux modèles sur 100 qui répondaient au critère fixé.
Le premier.
Le second.
Il s'avère que, oui, CatBoost peut faire beaucoup, mais il semble nécessaire de régler les paramètres de manière plus agressive.
Choisissez-vous ces modèles en fonction des meilleurs résultats au test ?
Ou parmi un ensemble des meilleurs au test - les meilleurs à l'examen ?