L'Apprentissage Automatique dans le trading : théorie, modèles, pratique et trading algo - page 1489
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Si quelqu'un comprend le HMM, veuillez m'aider à résoudre le problème, si le problème peut être résolu, je partagerai le graal.)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Si quelqu'un comprend le HMM, veuillez m'aider à résoudre le problème, si le problème peut être résolu, je partagerai le graal.)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Bien, l'état est markovien, mais quel est le modèle ?
cela signifie que vous avez besoin de plus de points pour la fenêtre carrée, au moins
Et si on alimente une série aléatoire, de quel type de prédiction autre que 50-50 peut-on parler ?cela signifie que vous avez besoin de plus de points pour la fenêtre au carré, au minimum.
Je vous l'ai dit, j'ai même pris plusieurs milliers de points
et si une série aléatoire est entrée, alors de quel type de prédiction autre que 50/50 pouvons-nous parler ?
Quelle différence cela fait-il ? Les données sont les mêmes, le modèle est le même.
j'ai prédit de nouvelles données en utilisant la fonction complète du paquet (comme dans tous les exemples sur le net ...) les résultats sont excellents.
J'utilise le même modèle pour prédire les mêmes données mais avec une fenêtre glissante et le résultat est différent, inacceptable.
C'est la question : quel est le problème ?Je vous ai dit que j'ai même pris plusieurs milliers de points
quelle différence cela fait-il ? Les données sont les mêmes, le modèle est le même.
Je prédis de nouvelles données en utilisant toute la fonction du paquet (comme dans tous les exemples sur le web...) et les résultats sont excellents.
je prédis les mêmes données avec le même modèle mais avec une fenêtre glissante et le résultat est différent, inacceptable.
C'est la vraie question : quel est le problème ?Je ne sais pas quel type de modèle et d'où vous obtenez vos états. sans aucun paquet, à quoi bon ?
Peut-être qu'il y a un gcp qui ne donne pas d'état aléatoire, c'est pourquoi il est prédit dans le 1er cas. Essayez de changer la graine pour le train et le test pour voir que dans le 1er cas, il est impossible de prédire quoi que ce soit, sinon je ne sais pas comment aider l'idée n'est pas claire.
Les divisions sont effectuées en fonction de la probabilité de la classification. Plus précisément, pas par probabilité, mais par erreur de classification. Parce que tout est connu sur l'exercice d'entraînement, et nous n'avons pas de probabilité, mais une estimation exacte.
Bien qu'il existe différentes fi ches de séparation, c'est-à-dire des mesures d'impureté (échantillonnage à gauche ou à droite).
Je faisais référence à la distribution de la précision de classification sur l'échantillon, et non au total comme c'est le cas actuellement.
il n'est pas clair quel est le modèle et d'où vous obtenez les états. Sans aucun paquet, quel est l'intérêt conceptuel ?
Peut-être qu'il y a un gcp qui ne donne aucune randomisation, c'est pourquoi il est prédit dans le 1er cas. Essayez de changer la graine pour le train et le test pour voir s'il est impossible de prédire dans le premier cas aussi, sinon je ne sais pas comment aider l'idée.
Voici le fichier, il y a des prix et deux colonnes avec les prédicteurs "data1" et "data2".
Vous entraînez des HMM avec seulement deux états(sur une piste de données sans professeur) pour ces deux colonnes ("data1" et "data2") en Python ou ce que vous voulez. Vous ne touchez pas du tout au prix, vous le faites juste pour la visualisation.
Ensuite, vous prenez l'algorithme de Viterbi et vous obtenez un (test de données).
nous obtenons deux états, cela devrait ressembler à ceci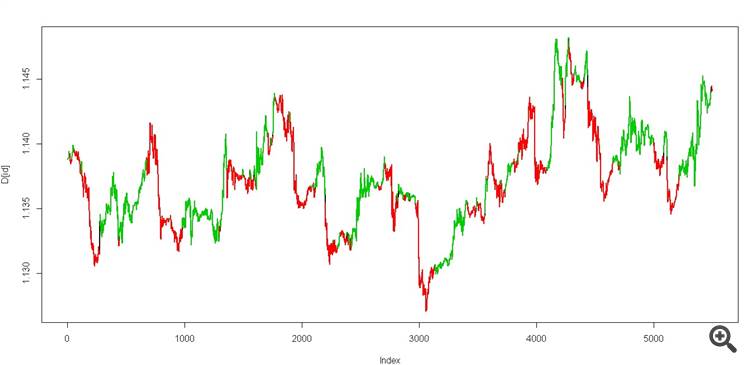
c'est un vrai graal))
Et ensuite, essayez de calculer le même Viterbi dans la fenêtre glissante en utilisant les mêmes données.
Voici un fichier avec des prix et deux colonnes avec des prédicteurs "data1" et "data2".
Vous entraînez les HMM avec seulement deux états(sur une piste de données) en utilisant ces deux colonnes ("data1" et "data2") en Python ou ce que vous voulez. Vous ne touchez pas du tout au prix, vous l'utilisez juste pour la visualisation.
Ensuite, vous prenez l'algorithme de Viterbi et (test de données)
nous obtenons deux états, cela devrait ressembler à ceci
C'est un vrai graal).
Et ensuite, essayez le même calcul de Viterbi dans la fenêtre glissante sur les mêmes données.
Senk, j'y jetterai un coup d'œil plus tard, je vous le ferai savoir, car je travaille avec un Markovien.
senk, j'y jetterai un coup d'œil plus tard et je vous le ferai savoir, car je travaille moi-même avec des Markov.
une chance ?
une chance ?
Je ne cherche pas encore, c'est mon jour de congé. Je vous ferai savoir quand j'aurai le temps, plus tard dans la semaine je veux dire.
Je regarde les packs jusqu'à présent. Je pense que cela correspond àhttps://hmmlearn.readthedocs.io/en/latest/tutorial.html