Discusión sobre el artículo "Modelos ocultos de Márkov en sistemas comerciales de aprendizaje automático"
Затем, следует скомпилировать приложенного в конце статьи бота и протестировать его в тестере MetaTrader 5.
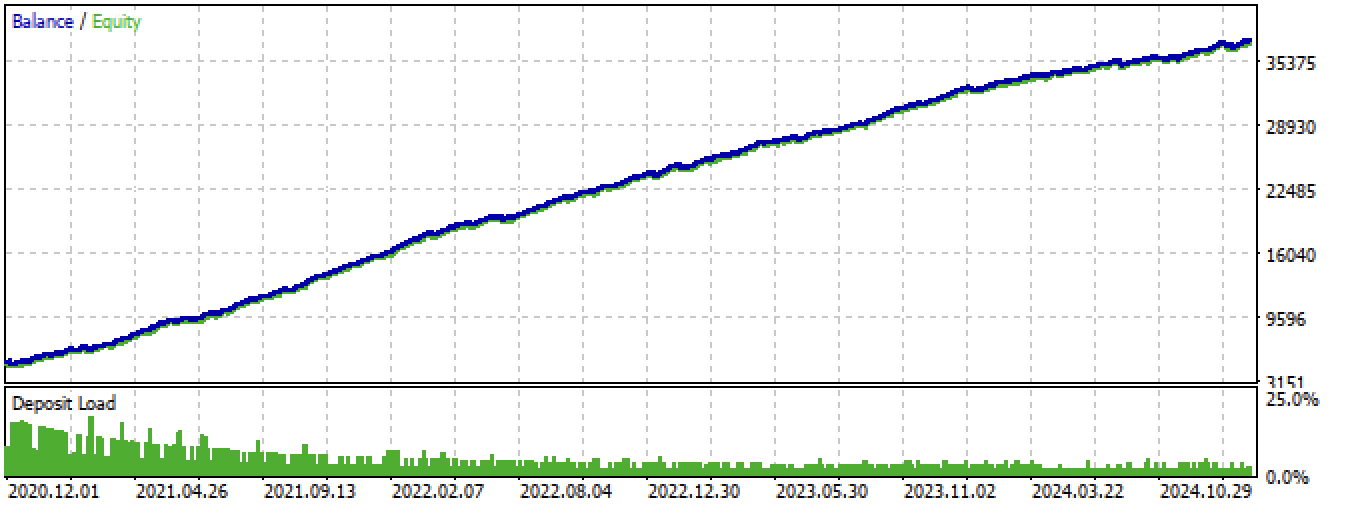
Fig. 14. Prueba del mejor modelo en el terminal MetaTrader 5 para todo el período
El archivo MQL5 files.zip contiene archivos para el terminal MetaTrader 5
Por favor, haga un estándar para publicar los correspondientes tst-files de backtest resultados publicados en los artículos. Muchas gracias.
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Artículo publicado Modelos ocultos de Márkov en sistemas comerciales de aprendizaje automático:
La biblioteca hmmlearn es un conjunto de algoritmos en Python para el aprendizaje no supervisado (modelos de Márkov ocultos). Está diseñado para proporcionar herramientas simples y eficientes para trabajar con SMM, siguiendo la API de la biblioteca scikit-learn, lo cual facilita la integración en proyectos de aprendizaje automático existentes y simplifica el proceso de aprendizaje para los usuarios familiarizados con scikit-learn. Hmmlearn está construido sobre bibliotecas científicas fundamentales de Python como NumPy, SciPy y Matplotlib.
Las principales capacidades de hmmlearn incluyen la implementación de varios modelos HMM con diferentes tipos de distribuciones de emisión, entrenamiento de parámetros del modelo a partir de los datos observados, inferencia de las secuencias más probables de los estados ocultos, generación de muestras a partir de los modelos entrenados y capacidad de guardar y cargar modelos entrenados. La amplia variedad de modelos implementados permite a los usuarios elegir el tipo de distribución de emisiones más apropiado dependiendo de la naturaleza de sus datos. El tipo de datos (continuos, discretos, contadores) determina qué distribución de probabilidad describe mejor el proceso de generación de observaciones en cada estado oculto.
Autor: dmitrievsky