Discusión sobre el artículo "Funciones de activación neuronal durante el aprendizaje: ¿la clave de una convergencia rápida?"
Este pasaje del artículo me llamó la atención. Aunque el artículo está muy bien escrito y da detalles de cómo fue diseñado y pensado. En este pasaje hay una sutileza sobre tu comprensión del tema. Tal vez seas parcial porque todo el mundo insiste en decir ciertas cosas sobre las redes neuronales. Pero tu artículo está bien escrito y has explicado los detalles. He decidido anticipar algo que mostraré en el futuro. El artículo para esto ya está escrito, pero primero quiero terminar de explicar cómo construir el Replay / Simulador, donde sólo quedan unos pocos artículos para finalizar la publicación. Entienda lo siguiente: Las funciones de activación NO se utilizan para generar no linealidad en las ecuaciones. Más bien, sirven como una especie de filtro con el objetivo de reducir el número de capas o perceptrones dentro de la red que se está construyendo. Esto acelera el proceso de convergencia de los datos en una dirección específica. Durante este proceso podemos aspirar a clasificar o retener conocimientos. Al final, obtendremos un resultado u otro, pero nunca ambos.
En mi artículo, https://www.mql5.com/es/articles/13745, demuestro esto de una manera relativamente sencilla. Aunque allí apenas empiezo a explicar cómo entender la red neuronal. Pero como tu artículo está bien escrito y te has esforzado mucho en él, te daré un consejo. Toma algunos datos aparentemente aleatorios y elimina las funciones de activación del perceptrón. Después, empieza a intentar converger. Notarás que no se verá muy bien. PERO si empiezas a añadir capas y/o más perceptrones, la convergencia empezará a mejorar con el tiempo. Esto te ayudará a entender mejor por qué son necesarias las funciones de activación. 😁👍

- www.mql5.com
Fallos de traducción...
Este pasaje del artículo me llamó la atención. Aunque el artículo está muy bien escrito y detalla cómo se diseñó y pensó. Hay una sutileza en tu comprensión del tema en este pasaje. Quizás seas parcial porque todo el mundo insiste en decir ciertas cosas sobre las redes neuronales. Pero tu artículo está bien escrito y has explicado los detalles. Decidí anticipar lo que mostraré en el futuro. El artículo para eso ya está escrito, pero primero quiero terminar de explicar cómo construir un Replay / Simulador, donde sólo faltan unos pocos artículos para completar la publicación. Entienda lo siguiente: Las funciones de activación NO se utilizan para crear no linealidad en las ecuaciones. Más bien, sirven como una especie de filtro cuyo propósito es reducir el número de capas o perceptrones en la red que se está construyendo. Esto acelera el proceso de convergencia de los datos en una dirección determinada. Durante este proceso, podemos buscar la clasificación o la retención de conocimientos. Acabaremos obteniendo uno u otro resultado, pero nunca ambos.
La autotraducción probablemente no sea muy precisa, pero el resaltado es incorrecto. Es la no linealidad la que aumenta la potencia computacional de la red, y no sólo acelera el proceso de convergencia (cosa que tú mismo también has dicho en otra frase) sino que fundamentalmente te permite resolver problemas que no se pueden resolver sin introducir la no linealidad (no importa cuántas capas añadas). Además, sin no linealidad, cualquier red neuronal (síncrona) se puede "colapsar" en una red monocapa equivalente.
Es la no linealidad la que aumenta la potencia computacional de la red, y no sólo acelera el proceso de convergencia (cosa que tú mismo has dicho también en otra frase) sino que, fundamentalmente, permite resolver problemas que no se pueden resolver sin la introducción de la no linealidad (no importa cuántas capas añadas). Además, sin no linealidad, cualquier red neuronal (síncrona) puede "colapsarse" en una red equivalente de una sola capa.
+100500
Bien dicho. Mientras componía mi respuesta, veo que ya ha sido contestada.
Diré más, sí, cualquier función no lineal puede ser descrita por funciones lineales a trozos en número tendente a infinito con error de descripción tendente a cero. Pero por qué, si las funciones de activación no lineales sólo se utilizan para simplificar la descripción del objeto del problema.
Creo que hubo un malentendido entre lo que pretendía decir y lo que realmente puse en forma de texto.
Intentaré ser un poco más claro esta vez 🙂 Cuando queremos CLASIFICAR cosas, como imágenes, objetos, figuras, sonidos, en fin, donde reinarán las probabilidades. Necesitamos limitar los valores dentro de la red neuronal para que entren dentro de un rango determinado. Este rango suele estar entre -1 y 1. Pero también puede estar entre 0 y 1 dependiendo de la velocidad, de la tasa de acierto y del tipo de tratamiento que se le dé a la información de entrada con la que queremos que la red entre en contacto, y de cómo dirija mejor su propio aprendizaje para crear la clasificación de las cosas. EN ESTE CASO, NECESITAMOS funciones de activación. Precisamente para mantener los valores dentro de ese rango. Al final, tendremos los medios para generar valores en función de la probabilidad de que la entrada sea una cosa u otra. Esto es un hecho y no lo niego. Tanto es así que a menudo necesitamos normalizar o estandarizar los datos de entrada.
Sin embargo, las redes neuronales no sólo sirven para clasificar cosas, también pueden y sirven para retener conocimientos. En este caso, las funciones de activación deberían descartarse en muchos casos. Detalle: Hay casos en los que necesitamos limitar las cosas. Pero son casos muy concretos. Esto se debe a que estas funciones se interponen en el camino de la red para cumplir su propósito. Que es precisamente retener el conocimiento. Y de hecho estoy de acuerdo, en parte, con el comentario de Stanislav Korotky de que la red, en estos casos, se puede colapsar en algo equivalente a una sola capa, si no utilizamos funciones de activación. Pero cuando esto ocurre, sería uno de varios casos, ya que hay casos en los que un solo polinomio con varias variables no es suficiente para representar, o más bien retener, el conocimiento. En este caso tendríamos que utilizar capas extra para que el resultado pueda ser realmente replicado. O se pueden generar otras nuevas. Es un poco confuso explicarlo así, sin una demostración adecuada. Pero funciona.
El gran problema es que, debido a la moda de todo ahora, en los últimos 10 años más o menos, si la memoria no me falla, se ha relacionado con la inteligencia artificial y las redes neuronales. Aunque el negocio no ha despegado realmente hasta los últimos cinco años. Mucha gente desconoce por completo qué son en realidad. O cómo funcionan realmente. Esto se debe a que todo el mundo que veo siempre está utilizando marcos ya hechos. Y esto no ayuda en absoluto a entender cómo funcionan las redes neuronales. No son más que una ecuación multivariable. Han sido estudiadas durante décadas en círculos académicos. E incluso cuando salieron del mundo académico, nunca se anunciaron a bombo y platillo. Durante la fase inicial y durante mucho tiempo NO SE UTILIZARON FUNCIONES DE ACTIVACIÓN. Pero la finalidad de las redes, que entonces ni siquiera se llamaban redes neuronales, era otra. Sin embargo, como tres personas querían sacar provecho de ellas, se les dio una publicidad que, en mi opinión, fue un tanto equivocada. Lo correcto, al menos en mi opinión, sería que se explicaran adecuadamente. Precisamente para no crear tanta confusión en la mente de tanta gente. Pero no pasa nada, los tres están ganando mucho dinero mientras la gente está más perdida que un perro que se ha caído de un camión de mudanzas. En cualquier caso, no quiero desanimarte a escribir nuevos artículos, Andrey Dik, pero sí quiero que sigas estudiando e intentes profundizar aún más en este tema. He visto que has intentado utilizar MQL5 puro para crear el sistema. Lo cual es muy bueno por cierto. Y esto me llamó la atención, dándome cuenta de que tu artículo estaba muy bien escrito y planificado. Sólo quería llamar tu atención sobre ese punto en particular y hacerte reflexionar un poco más. De hecho, este tema es muy interesante y hay muchas cosas que poca gente sabe. Pero tú te has adelantado y lo has estudiado.
Debates em alto nível, são sempre interessantes, pois nos faz crescer e pensar fora da caixa. Brigas não nos leva a nada, e só nos faz perder tempo. 👍

- 2025.01.21
- MetaQuotes
- www.mql5.com
Se puede usar cualquier cosa como función de activación, incluso coseno, el resultado está al nivel de las populares. Se recomienda usar relu (con sesgo 0.1(nose recomienda usarlo junto con inicialización de paseo aleatorio)) porque es simple (conteo rápido) y mejor aprendizaje: Estos bloques son fáciles de optimizar porque son muy similares a los bloques lineales.La única diferenciaes que un bloque de rectificación lineal da como resultado 0 en la mitad de su dominio de definición, por lo que la derivada de un bloque de rectificación lineal sigue siendo grande en todos los lugares en los que el bloque está activo. Los gradientes no sólo son grandes, sino que también son coherentes. La segunda derivada de la operación de rectificación es cero en todas partes, y la primeraderivada es 1 en todas partes donde el bloque está activo. Esto significa que la dirección del gradiente es mucho más útil para el aprendizaje que cuando la función de activación está sujeta a efectos de segundo orden... Al inicializar los parámetros de la transformación afín, se recomiendaasignar un valor positivo pequeño atodos los elementos de b, por ejemplo 0,1. Entonces es muy probable que el bloque de rectificación lineal esté activo en el momento inicial para la mayoría de los ejemplos de entrenamiento, y la derivada será distinta de cero.
A diferencia delos bloques lineales a trozos,los bloques sigmoidalesestán cerca de la asíntota en la mayor parte de su dominio de definición - acercándose a un valor alto cuando z tiende a infinito y a un valor bajo cuando z tiende a menos infinito.Sólo tienen una sensibilidad elevadaen las proximidades de cero. Debido a la saturación de los bloques sigmoidales , el aprendizaje por gradiente se ve gravemente obstaculizado. Por lo tanto, hoy en día no se recomienda utilizarlos como bloques ocultos en redes de propagación hacia delante... Si es necesario utilizar la función de activación sigmoidal, es mejor tomar la tangente hiperbólica en lugar de la sigmoidal logística . Se parece más a la función de identidaden el sentido de que tanh(0) = 0, mientras que σ(0) = 1/2. Dado que tanh se parece a una función de identidad en la vecindad de cero, el entrenamiento de unared neuronal profundase parece al entrenamiento de un modelo lineal, siempre que las señales de activación de la red puedan mantenerse bajas.En este caso, el entrenamiento de una red con la función de activación tanh se simplifica.
Para lstm es necesario utilizar sigmoide o arctangente(se recomienda fijar el desplazamientoen 1 para el venteo de olvido): Las funciones de activación sigmoidales se siguen utilizando, pero no en redes feedforward . Las redes recurrentes, muchos modelos probabilísticos y algunos autocodificadores tienen requisitos adicionales que impiden el uso de funciones de activación lineal a trozos y hacen que los bloquessigmoidales sean más apropiados a pesar de los problemas de saturación.
Activación lineal y reducción de parámetros: Si cada capa de la red consiste únicamente en transformaciones lineales, la red en su conjunto será lineal. Sin embargo, algunas capas también pueden ser puramente lineales , lo cual está bien. Consideremos una capa de una red neuronal que tiene n entradas y p salidas. Puede sustituirse por dos capas, una con una matriz de pesos U y otra con una matriz de pesos V. Si la primera capa no tiene función de activación, esencialmente hemos descompuesto la matriz de pesos de la capa original basada en Wen multiplicadores . Si U genera q salidas, entonces U y V juntos contienen sólo (n + p)q parámetros, mientras que W contiene np parámetros. Para q pequeños, el ahorro de parámetros puede sersustancial. La contrapartida es una limitación : la transformación lineal debe tener un rango bajo, pero estos enlaces de rango bajo suelen ser suficientes. Así, los bloques ocultos lineales ofrecen una forma eficiente de reducir el número de parámetrosde la red.
Relu es mejor para redes profundas: a pesar de la popularidad de la rectificación en los primeros modelos, fue sustituida casi universalmente por la sigmoidea en la década de 1980 porque funciona mejor para redes neuronales muy pequeñas.
Pero es mejor en general: para conjuntos de datos pequeños ,utilizar no linealidades rectificadoras es incluso más importante que aprender los pesos de las capas ocultas.Los pesos aleatorios son suficientes para propagarinformación útila través de la red con rectificación lineal, lo que permiteentrenar la capa de salidaclasificadorapara asignar diferentes vectores de característicasaidentificadores declase. Si se dispone de más datos, el proceso de aprendizaje empieza a extraer tanto conocimiento útil que supera a los parámetros seleccionados aleatoriamente... el aprendizaje es mucho más fácil en las redes lineales rectificadas que en las redes profundas, cuyasfunciones de activación se caracterizan por la curvatura o la saturación bidireccional...
Creo que hubo un malentendido entre lo que quería decir y lo que realmente expuse en forma de texto.
Intentaré ser un poco más claro esta vez 🙂 Cuando queremos CATEGORIZAR cosas como imágenes, objetos, formas, sonidos, en fin, donde reinarán las probabilidades. Necesitamos restringir los valores en la red neuronal para que caigan dentro de un rango determinado. Normalmente este rango está entre -1 y 1. Pero también puede estar entre 0 y 1, dependiendo de lo rápido, a qué ritmo y de qué manera se procese la información de entrada que queremos que aprenda la red y de cómo dirija mejor su aprendizaje para crear una clasificación de las cosas. EN ESTE CASO, NECESITAREMOS funciones de activación. Se trata de mantener los valores dentro de ese rango. Terminaremos con una forma de generar valores en función de la probabilidad de que las entradas sean una u otra. Esto es un hecho, y no lo niego. Tanto es así que a menudo tenemos que normalizar o estandarizar los datos de entrada.
Sin embargo, las redes neuronales no sólo sirven para clasificar, también pueden utilizarse, y de hecho se utilizan, para retener conocimientos. En este caso, las funciones de activación deberían descartarse en muchos casos. Detalle: Hay casos en los que necesitamos restringir algo. Pero se trata de casos muy concretos. La cuestión es que estas funciones impiden que la red cumpla su propósito. Y ese es preservar el conocimiento. Y de hecho, estoy parcialmente de acuerdo con el comentario de Stanislav Korotsky de que la red en esos casos puede reducirse a algo equivalente a una sola capa si no se utilizan funciones de activación. Pero cuando esto ocurra, será uno de varios casos, porque hay casos en los que un solo polinomio con varias variables no es suficiente para representar o, mejor dicho, almacenar conocimiento. En este caso, tendremos que utilizar capas adicionales para que el resultado pueda reproducirse realmente. Otra posibilidad es generar otras nuevas. Es un poco confuso explicarlo así, sin una demostración adecuada. Pero funciona.
El gran problema es que, debido a la moda de todo ahora, en los últimos 10 años más o menos, si no me falla la memoria, todo ha girado en torno a la inteligencia artificial y las redes neuronales. Aunque el negocio sólo ha florecido realmente en los últimos cinco años. Mucha gente desconoce por completo qué son realmente estas cosas. Y cómo funcionan realmente. Esto se debe a que todo el mundo que veo siempre está utilizando frameworks "off-the-shelf". Y eso no ayuda en absoluto a entender cómo funcionan las redes neuronales. Es sólo una ecuación con algunas variables. Se han estudiado en el mundo académico durante décadas. E incluso cuando han salido del mundo académico, nunca se han anunciado con tanta pompa. Inicialmente, y durante mucho tiempo. NO SE UTILIZABAN FUNCIONES DE ACTIVACIÓN. Pero la finalidad de las redes, que entonces ni siquiera se llamaban redes neuronales, era otra. Sin embargo, como tres personas querían sacar provecho de ellas, se les dio bombo y platillo, lo cual me parece un tanto erróneo. Lo correcto, al menos desde mi punto de vista, habría sido explicar adecuadamente su esencia. Exactamente para no crear confusión en la mente de mucha gente. Pero no pasa nada, los tres ganan mucho dinero y la gente está más perdida que un perro cayéndose de un camión de basura. En fin, no quiero desanimarte a escribir más artículos, Andrew Dick, pero quiero que sigas aprendiendo e intentes profundizar aún más en este tema. Vi que trataste de usar MQL5 puro para crear un sistema. Lo cual es muy bueno, por cierto. Me llamó la atención y me di cuenta de que tu artículo está muy bien escrito y planificado. Sólo quería llamar tu atención sobre este punto y hacerte reflexionar un poco más. Este tema es realmente muy interesante y no mucha gente lo conoce. Pero tú te has ocupado de él y lo has investigado.
Sí, la no linealidad es un efecto indirecto que tienen los phs de activación. Originalmente estaban pensados para traducir de un dominio de definición de objetivos a otro, por ejemplo, para tareas de clasificación. La "no linealidad" se puede conseguir de diferentes maneras, por ejemplo aumentando el número de características o transformándolas, o mediante kernels que transforman las características.
El ejemplo más sencillo es la regresión logística, que sigue siendo lineal a pesar de la función de activación final.
Pero en las redes multicapa, la no linealidad se obtiene debido al número de capas con funciones de activación, simplemente como consecuencia de transformaciones de tipo kernel.Antecedentes históricos:
Es cierto que los conceptos subyacentes a la regresión logística y a las primeras redes neuronales son anteriores a las modernas redes neuronales profundas.
Veamos la cronología:
-
Lafunción logística se desarrolló en el siglo XIX. Su uso como modelo estadístico de clasificación (regresión logística) se popularizó a mediados del siglo XX (aproximadamente entre 1940 y 1950).
-
El primer modelo matemático de una neurona (el modelo de McCulloch y Pitts) con una función de activación apareció en 1943. Utilizaba una función umbral simple.
-
El perceptrón, una red neuronal de una sola capa, fue desarrollado por Frank Rosenblatt en 1958. Utilizaba una función de activación umbral y sólo podía resolver problemas linealmente separables.
-
Elgran avance del aprendizaje profundo y las redes multicapa se produjo con la llegada del algoritmo de retropropagación, popularizado en 1986 por Rumelhart, Hinton y Williams.
Fue este algoritmo el que hizo práctico el entrenamiento de redes neuronales multicapa y demostró que requiere no sólo umbrales, sino funciones de activación no lineales diferenciables (como la sigmoidea y, más tarde, la ReLU).
Conclusión:
Históricamente resulta que:
-
Primero hubo modelos (regresión logística, perceptrón) que eran esencialmente modelos de una capa.
-
En estos modelos, la función de activación actuaba realmente como una transformación al dominio deseado (de una suma lineal a una clase o probabilidad binaria), ya que todo el modelo seguía siendo lineal.
-
Más tarde, con la llegada de las redes multicapa, surgió un nuevo papel, fundamentalmente más importante, de la función de activación: introducir la no linealidad en las capas ocultas para que la red pudiera aprender.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Funciones de activación neuronal durante el aprendizaje: ¿la clave de una convergencia rápida?:
Imagine un río con muchos afluentes. En su estado normal, el agua fluye con libertad, creando un complejo patrón de corrientes y remolinos. Pero, ¿qué pasará si empezamos a construir un sistema de esclusas y presas? Podremos controlar el flujo de agua, dirigirla en la dirección que nos convenga y regular la fuerza de la corriente. La función de activación en las redes neuronales cumple un papel parecido: decide qué señal transmitir y cuál retrasar o atenuar. Sin ella, una red neuronal no sería más que un conjunto de transformaciones lineales.
La función de activación añade dinamismo a la red neuronal, lo cual le permite captar matices sutiles en los datos. Por ejemplo, en un problema de reconocimiento facial, la función de activación ayuda a la red a fijarse en detalles minúsculos como la curva de las cejas o la forma de la barbilla. La elección correcta de la función de activación afectará al modo en que la red neuronal gestiona las distintas tareas. Algunas funciones resultan más adecuadas para las fases iniciales del aprendizaje, ya que proporcionan señales claras y comprensibles. Algunas funciones permiten a la red captar patrones más sutiles en fases avanzadas, mientras que otras eliminan todo lo innecesario, dejando solo lo más importante.
Si no conocemos las propiedades de las funciones de activación, podríamos tener problemas. La red neuronal puede empezar a "tropezar" en tareas sencillas o a "pasar por alto" detalles sustanciales. La principal tarea de las funciones de activación consiste en introducir la no linealidad en la red neuronal y normalizar los valores de salida.
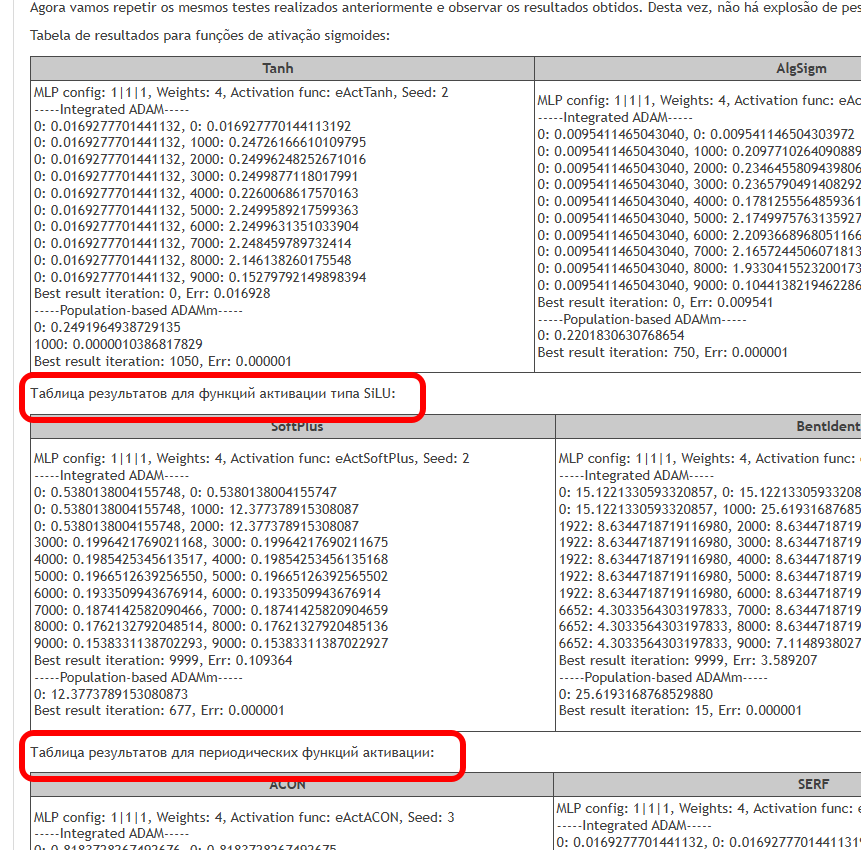
El objetivo de este trabajo es identificar los problemas asociados al uso de distintas funciones de activación y su impacto en la precisión de una red neuronal que pasa por puntos de ejemplos (interpolación) minimizando el error. También veremos si las funciones de activación afectan realmente a la tasa de convergencia, o si se trata de una propiedad del algoritmo de optimización utilizado. Como algoritmo de referencia, aplicaremos un ADAMm poblacional modificado que usará elementos de estocasticidad, y realizaremos pruebas con el ADAMm incorporado en MLP (uso clásico). Este último debería poseer intuitivamente la ventaja de tener acceso directo al gradiente de superficie de la función de aptitud debido a la derivada de la función de activación. Mientras que la población estocástica ADAMm no tendrá acceso a la derivada y desconocerá por completo la superficie del problema de optimización. Veamos qué sale de todo esto y entonces sacaremos conclusiones.
Autor: Andrey Dik