¿Qué alimentar a la entrada de la red neuronal? Tus ideas... - página 52
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Si miras la foto, sí, es cálido y suave, pero en el código está bien.
Los corchetes de la imagen están mal. Debería ser así.
Ola ke tal. Pensé en aportar mis ideas.
Mi último modelo es recoger los precios normalizados de 10 símbolos y así entrenar una red de recurrencia. Para la entrada 20 barras del mes, semana y día.
Esa es la imagen que obtengo. La diferencia con el entrenamiento por separado es que el beneficio total es 3 veces menor y el drawdown.... wow, el drawdown en el período de control es de apenas 1%.
Me parece que resuelve el problema de la escasez de datos.
Ola ke tal. Pensé en aportar mis ideas.
Mi último modelo consiste en recopilar precios normalizados de 10 símbolos y así entrenar una red de recurrencia. Hay 20 barras del mes, semana y día por entrada.
Esa es la imagen que obtengo. La diferencia con el entrenamiento por separado es que el beneficio total es 3 veces menor y el drawdown.... wow, el drawdown en el periodo de control es de apenas 1%.
Me parece que resuelve el problema de la escasez de datos.
Creo que tienes un altísimo nivel de conocimiento del tema.
Me temo que no voy a entender nada. Por favor, dime qué es esta belleza en el gráfico: ¿es Python?
¿Es posible mostrar algo así en MT5?
precios normalizados de 10 símbolos
Aquí también, cómo se normalizan los precios. ¿Qué es "ante" En general, cualquier cosa que no es un secreto comercial, por favor, comparta)
Creo que tienes un nivel altísimo de dominio del tema.
Me temo que no voy a entender nada. Por favor, dígame qué es esta belleza en el gráfico: ¿es Python?
¿Es posible mostrar algo así en MT5?
Aquí también, cómo los precios normalizados. ¿Qué es "ante" En general, cualquier cosa que no es un secreto comercial, por favor, comparta).
Por supuesto que es python. En µl5 para seleccionar datos en una condición, tienes que hacer una enumeración y todo eso iff iff iff iff iff. Y en python en una sola línea para seleccionar datos de cualquier condición. No estoy hablando de la velocidad de trabajo. Es demasiado conveniente. Mcl5 es necesario para abrir operaciones con una red ya hecha.
La normalización es la más común. Menos la media, dividida por la desviación estándar. El secreto comercial aquí es el período de normalización, es importante abordarlo de tal manera que los precios son alrededor de cero durante 10 años. Pero no de forma que al principio de los 10 años estén por debajo de cero y al final estén por encima de cero. Esa no es la forma de comparar...
Dos periodos de prueba - ante y test. El período ante antes del entrenamiento es de 6 meses. Es muy conveniente. El ante siempre está ahí. Y la prueba es el futuro, no existe. Es decir, es, pero sólo en el pasado. Y en el futuro no es. Es decir, no lo es.
¿Qué le parece más importante: la arquitectura o los datos de entrada?
¿Qué le parece más importante: la arquitectura o los datos de entrada?
Creo que los datos de entrada. Aquí estoy tratando de 6 caracteres, no 10. Y no estoy pasando el período de control agosto-diciembre 2023. Por separado, también es difícil. Y un pase de 10 caracteres puede ser legítimamente elegido en base a los resultados del entrenamiento. La red es siempre recurrente en 1 capa de 32 estados, sólo se utiliza el enlace completo.
Algunos resúmenes:
Llegué a darme cuenta de que acababa de encontrar un patrón algorítmico mientras escogía varios datos de entrada, de hecho respondía parcialmente a la pregunta de mi rama "¿Qué alimentar a la entrada de la red neuronal?" Pero la red neuronal resultó ser innecesaria. Ni MLP, ni RNN, ni LSTM, ni BiLSTM, ni CNN, ni Q-learning, ni todas ellas combinadas y mezcladas.
En uno de esos experimentos optimicé 2 entradas en 3 neuronas. Como resultado, uno de los conjuntos superiores mostró la siguiente imagen
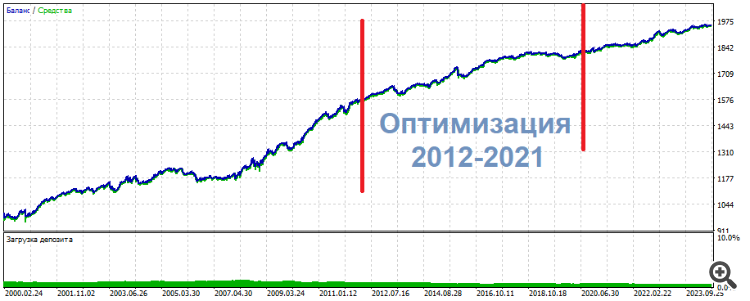
* ******* **************
UPD Aquí hay otro conjunto, lo mismo: centro - optimización, resultados - a los lados. Casi lo mismo, sólo más uniforme
**********************
Los oficios no son pips o cuero cabelludo. Más bien intradía.
Por lo tanto, mis conclusiones subjetivas para el momento actual:
Nunca he visto peores resultados que en los indicadores de suavizado en mi vida . Es como una persona vidente quedarse ciego. Justo ahora podía ver una silueta clara, y ahora no puede entender lo que - un poco de frotis en sus ojos. No hay información.
Mi opinión, como yo lo veo
La red neuronal sólo es aplicable a patrones estacionarios, estáticos, que no tienen nada que ver con la fijación de precios
¿Qué tipo de preprocesamiento, normalización haces? ¿Has probado la normalización?
I van Butko #: La red neuronal recuerda el camino. No más que eso.
Prueba los transformadores, dicen que son buenos para ti....
Ivan Butko #: ¡Los osciladores son malvados!
Bueno, no todo es tan inequívoco. Es solo que NS es conveniente para trabajar con funciones continuas, pero necesitamos una arquitectura que trabaje con funciones a trozos/intervalos, entonces NS será capaz de tomar rangos de osciladores como información significativa.
¿Qué tipo de preprocesamiento y normalización realiza? ¿Ha probado la normalización?
Pruebe Transformers, dicen que son buenos para usted....
Bueno, no todo está tan claro. Es solo que NS es conveniente para trabajar con funciones continuas, pero necesitamos una arquitectura que trabaje con funciones a trozos/intervalos, entonces NS será capaz de tomar rangos de osciladores como información significativa.
1. Y cuando cómo: si la ventana de datos, algunos incrementos, traigo en el rango -1..1. No he oído hablar de la normalización 2.
Aceptado, gracias 3. Estoy de acuerdo, no tengo plena prueba de lo contrario.
Por eso escribo desde mi propio campanario, como veo e imagino aproximadamente. El simple suavizado es un borrado de información de facto. No generalización. Borrado exactamente. Basta pensar en una fotografía: en cuanto se degrada su contenido, la información se pierde irremediablemente. Y restaurarla con IA es un esfuerzo artístico, no una restauración en el verdadero sentido. Es un redibujado arbitrario.
"Suavizado: cuando un número es el resultado de dos unidades de información independientes: el patrón -1/1, pongamos por caso, y el patrón -6/6. El valor medio de cada uno será el mismo, pero originalmente había dos patrones. Pueden o no significar algo, pueden significar señales opuestas.
Y aquí están los mashki, osciladores y demás - sólo borran/desdibujan estúpidamente la "imagen" inicial del mercado. Y en este "desdibujamiento" asustamos al NS, haciendo que intente sin cesar funcionar como debería. La generalización y el suavizado son fenómenos heterogéneos extremadamente poco amistosos.
Algunos resúmenes:
Llegué a darme cuenta de que acababa de encontrar un patrón algorítmico mientras escogía varios datos de entrada, de hecho respondía parcialmente a la pregunta de mi rama "¿Qué alimentar a la entrada de la red neuronal?" Pero la red neuronal resultó ser innecesaria. Ni MLP, ni RNN, ni LSTM, ni BiLSTM, ni CNN, ni Q-learning, ni todas ellas combinadas y mezcladas.
En uno de esos experimentos optimicé 2 entradas en 3 neuronas. Como resultado, uno de los conjuntos superiores mostró la siguiente imagen
* ******* **************
UPD Aquí hay otro conjunto, lo mismo: centro - optimización, resultados - a los lados. Casi lo mismo, sólo más uniforme
**********************
Las operaciones no son ni pips ni scalp.
Más bien intradía. Por lo tanto, mis conclusiones subjetivas en este momento:
Nunca he visto peores resultados que en los indicadores de suavizado en mi vida . Es como una persona vidente quedarse ciego. Justo ahora podía ver una silueta clara, y ahora no puede entender lo que - un poco de frotis en sus ojos. No hay información.
Mi imho, como yo lo veo
no es un débil pips.
¿Es hora de coser bolsas?