Regresión Bayesiana - ¿Alguien ha hecho un EA utilizando este algoritmo? - página 40
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Y mi alma sigue queriendo ahondar en el tema de las citas incrementales supuestamente distribuidas normalmente.
Si alguien está a favor, daré argumentos de por qué este proceso no puede ser normal. Y estos argumentos serán comprensibles para todos, a la vez que serán coherentes con el CPT. Y estos argumentos son tan triviales que no debería haber dudas.
¿Y qué expresará la probabilidad, la previsión de la próxima barra o el vector de movimiento de las próximas barras?
La probabilidad expresará la previsión del siguiente tick ( incremento). Sólo quiero hacerlo:
- calcular los valores de los futuros ticks de Ybayes para los que la probabilidad por la fórmula de Bayes será máxima.
- Compara Ybayes con las garrapatas reales de Yreal que llegan . Recoger y procesar las estadísticas .
Si la diferencia de valores está dentro de un rango razonable, entonces publicaré el código y preguntaré qué hacer a continuación. ¿Regresión? ¿Vector? ¿Escala?
La probabilidad expresará la predicción del siguiente tick ( incremento). Sólo quiero hacerlo:
¿Por qué bajar a las garrapatas? Puedes aprender a predecir las direcciones de las garrapatas en 5 minutos con un 70% de precisión, pero a 100 garrapatas de distancia, sabes que la precisión caerá.
Pruebe con incrementos de media hora o una hora antes. A mí también me interesa, quizá pueda ayudar de alguna manera.
La probabilidad expresará la predicción del siguiente tick ( incremento). Sólo quiero hacerlo:
- calcular los valores de los futuros ticks de Ybayes para los que la probabilidad por la fórmula de Bayes será máxima.
- Compara Ybayes con las garrapatas reales de Yreal que llegan . Recoger y procesar las estadísticas .
Si la diferencia de valores está dentro de un rango razonable, publicaré el código y preguntaré qué hacer a continuación. ¿Regresión? ¿Vector? ¿Curva? ¿Escala?
¿Qué tiene de malo ARIMA? En los paquetes, el número de diffs (incrementos de incrementos) se calcula automáticamente en función del flujo de entrada. Muchas sutilezas relacionadas con la estacionariedad se esconden dentro del paquete.
Si realmente quieres ir tan profundo, entonces algún ARCO...
Lo intenté una vez. El problema es este. El incremento se puede calcular fácilmente. Pero si añadimos el intervalo de confianza de este incremento al propio incremento, será de COMPRA o VENTA ya que el valor del precio anterior cae dentro del intervalo de confianza.
Sí, el enfoque clásico, como escribe SanSanych, es el análisis de datos, los requisitos de datos y los errores del sistema.
Pero este hilo es sobre Bayes y estoy tratando de pensar en términos bayesianos, como el soldado en la trinchera calculando la probabilidad posterior (después de la experiencia). Más arriba he puesto un ejemplo del soldado.
Una de las principales cuestiones es qué se debe tomar como probabilidad a priori. En otras palabras, ¿a quién debemos poner detrás de la cortina del futuro, a la derecha de la barra del cero? ¿Gauss? ¿Laplace? ¿Wiener? ¿Qué escriben aquí los matemáticos profesionales (para mí un oscuro "bosque")?
Elijo a Gauss porque tengo una idea de la distribución normal y creo en ella. Si no se "dispara" entonces es posible tomar otras leyes y sustituir Gauss en lugar de la fórmula de Bayes, o junto con Gauss como producto de dos probabilidades. Intenta hacer una red bayesiana, si lo entiendo bien.
Naturalmente, no puedo hacerlo solo. Me gustaría resolver el problema con Gauss, que formulé bajo el ramo. Si alguien está dispuesto a unirse a mí de forma voluntaria, por favor, hágalo. Aquí hay un problema real.
Dado: МТ4 generador de números aleatorios.
Necesidad: Escribir código MQL4 como función FP() convirtiendo la matriz МТ4[] formada por el RNG estándar en la matriz ND[] con distribución normal.
Vasily (no sé mi patronímico) Sokolov me mostró las fórmulas de transformación en https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
Aunque puedo ampliar los gráficos de las matrices calculadas directamente en la ventana de MT4, lo estaba haciendo en mis proyectos.
Entiendo que mucha gente aquí puede resolver este problema con un par de clics en paquetes matemáticos, pero quiero hablar en un lenguaje MQL4, que es comúnmente entendido por los comerciantes, programadores, economistas y filósofos.
Sí, el enfoque clásico, como escribe SanSanych, es el análisis de datos, los requisitos de datos y los errores del sistema.
Pero este hilo es sobre Bayes y estoy tratando de pensar en términos bayesianos, como el soldado en la trinchera calculando la probabilidad posterior (después de la experiencia). Más arriba he puesto un ejemplo del soldado.
Una de las principales cuestiones es qué se debe tomar como probabilidad a priori. En otras palabras, ¿a quién debemos poner detrás de la cortina del futuro, a la derecha de la barra del cero? ¿Gauss? ¿Laplace? ¿Wiener? ¿Qué escriben aquí los matemáticos profesionales (para mí un oscuro "bosque")?
Elijo a Gauss porque tengo una idea de la distribución normal y creo en ella. Si no se "dispara" entonces es posible tomar otras leyes y sustituir Gauss en lugar de la fórmula de Bayes, o junto con Gauss como producto de dos probabilidades. Intenta hacer una red bayesiana, si lo entiendo bien.
Naturalmente, no puedo hacerlo solo. Me gustaría resolver el problema con Gauss, que formulé bajo el ramo. Si alguien está dispuesto a unirse a mí de forma voluntaria, por favor, hágalo. Aquí hay un problema real.
Dado: МТ4 generador de números aleatorios.
Necesidad: Escribir código MQL4 como función FP() convirtiendo el array MT4[] formado por el RNG estándar en un array ND[] con distribución normal.
Vasily (no sé mi patronímico) Sokolov me mostró las fórmulas de transformación en https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
Sin embargo puedo y puedo reescalar gráficos de arrays calculados directamente en la ventana de MT4. Lo estaba haciendo en mis proyectos.
Entiendo que muchos traders pueden resolver este problema en un par de clics utilizando paquetes matemáticos, pero yo quiero utilizar el lenguaje MQL4, que es generalmente accesible para traders, programadores, economistas y filósofos.
Aquí hay un generador con diferentes distribuciones, incluida la normal:
https://www.mql5.com/ru/articles/273
Un breve análisis de la distribución en R:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Estimamos los parámetros de la distribución normal a partir de los incrementos del precio de apertura de la barra del reloj disponibles y los trazamos para comparar la frecuencia y la densidad de la serie original y la serie normal con las mismas distribuciones. Como se puede ver incluso a ojo, la serie original de incrementos de barras horarias dista mucho de ser normal.
Y por cierto, no estamos en un templo de Dios. No es necesario e incluso es perjudicial creer.
He aquí una línea curiosa del post anterior, que se hace eco de lo que escribí más arriba
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
Por lo que tengo entendido en los cuadrantes, ¡el 50% de todos los incrementos en la o son menores de 7 pips! Y los incrementos más decentes están en las colas gruesas, es decir, al otro lado del bien y del mal.
¿Cómo será el ST? Ese es el problema, no el bayesiano y otros, otros, ....
¿O debe entenderse de otra manera?
He aquí una línea curiosa del post anterior, que se hace eco de lo que escribí más arriba
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
Por lo que entiendo en los cuadrantes, ¡el 50% de todos los incrementos en el horario son menores de 7 pips! Y los incrementos más decentes están en las colas gruesas, es decir, al otro lado del bien y del mal.
¿Cómo será el ST? Ese es el problema, no el bayesiano y otros, otros, ....
¿O debe entenderse de otra manera?
SanSanych, ¡sí!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')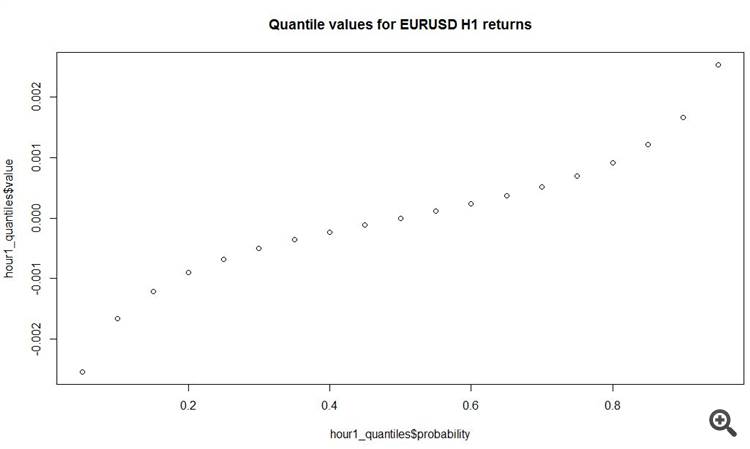
¡Y otra cosa interesante es que el incremento medio absoluto en las barras horarias es de 11 pips! Total.
Tendrá que hacerlo durante mucho tiempo, porque necesita una retransformación y... Y a Box-Cox no le gusta mucho)))) Es una pena que si no tienes
Es una pena que si no tienes buenos predictores, no tenga mucho efecto en el resultado final...