Discusión sobre el artículo "Uso del análisis discriminante para desarrollar sistemas de trading"
Al autor (sin apodo por alguna razón).
El mismo problema se puede resolver de otras maneras. Hay pruebas para variables redundantes y faltantes. Podría hacer eso y comparar con tus resultados. Pero necesito todos tus archivos en formato .csv.
...necesito todos sus archivos en formato .csv.
Creo que la fuente está en el archivo masterdata.zip.
Después de haber elegido las variables, tendremos que hacer alguna relación a partir de ellas, en la que el precio será la variable dependiente (función), y los otros indicadores serán variables independientes. He aquí la ecuación esquemática:
precio precio(-1) dac(-1) dao(-1) dbears(-1) dbulls(-1) cci(-1) dframa(-1) dmacdm(-1)
-1 significa el valor anterior. Esto es natural, ya que el indicador se deriva del precio analíticamente. Tengamos en cuenta que el precio es un incremento, por lo que tomaremos los incrementos de los indicadores. Por pereza, no tomo todos los indicadores. Estimemos esta ecuación por el método de mínimos cuadrados:
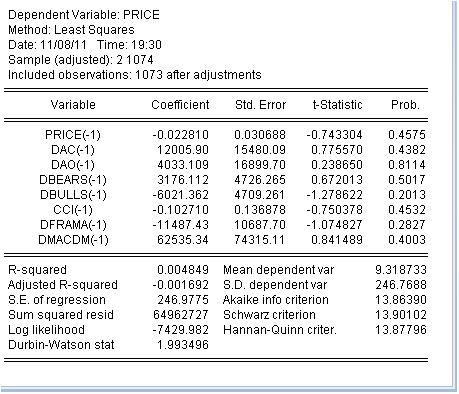
Hemos obtenido una estimación de los coeficientes de la ecuación. La última columna es muy interesante: significa la probabilidad de que el coeficiente correspondiente sea igual a cero. Esta probabilidad para todos los coeficientes es muy superior al 10% como mínimo, es decir, podemos considerar que no podemos rechazar la hipótesis de que los coeficientes correspondientes sean iguales a cero. En consecuencia, la R-cuadrado tiene un valor ridículo.
Llego a la conclusión de que es inútil ocuparse de la clasificación de los indicadores: son inútiles porque no tienen nada que ver con el incremento de los precios.
¿O me equivoco?
...¿O me equivoco?
Creo que tienes razón :-)
faa1947, tengo una pregunta para ti. Quería aclarar un par de cosas... así es como he calculado los datos de tu ecuación:
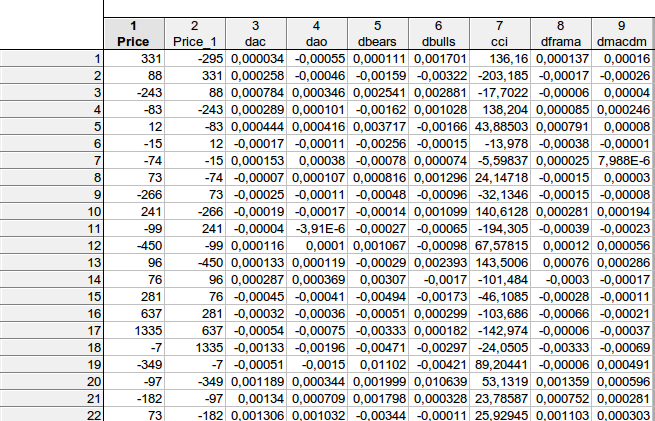
¿Coinciden los datos de la tabla con tu ecuación esquemática precio precio(-1) dac(-1) dao(-1) dbears(-1) dbulls(-1) cci(-1) dframa(-1) dmacdm(-1)?
Y obtuve el siguiente resultado
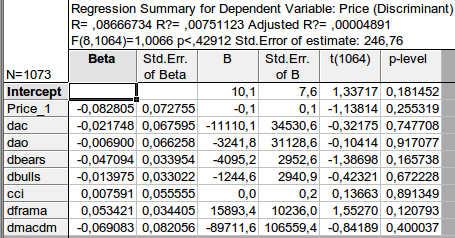
Una vez elegidas las variables, tendremos que hacer alguna relación a partir de ellas, en la que el precio será la variable dependiente (función) y los demás indicadores serán las variables independientes. He aquí una ecuación esquemática:
precio precio(-1) dac(-1) dao(-1) dbears(-1) dbulls(-1) cci(-1) dframa(-1) dmacdm(-1)
-1 significa el valor anterior. Esto es natural, ya que el indicador se deriva del precio analíticamente. Tengamos en cuenta que el precio es un incremento, por lo que tomaremos los incrementos de los indicadores. Por pereza, no tomo todos los indicadores. Estimemos esta ecuación por el método de mínimos cuadrados:
Hemos obtenido una estimación de los coeficientes de la ecuación. La última columna es muy interesante: significa la probabilidad de que el coeficiente correspondiente sea igual a cero. Esta probabilidad para todos los coeficientes es muy superior al 10% como mínimo, es decir, podemos considerar que no podemos rechazar la hipótesis de que los coeficientes correspondientes sean iguales a cero. En consecuencia, la R-cuadrado tiene un valor ridículo.
Llego a la conclusión de que es inútil ocuparse de la clasificación de los indicadores: son inútiles porque no tienen nada que ver con el incremento de los precios.
¿O me equivoco?
Por favor, indique el nombre del método estadístico que utilizó. ¿Fue la construcción de una ecuación de regresión lineal, donde la entrada son los indicadores y la salida es el precio futuro? ¿Es correcto? Esto no funcionará para Forex, ya que no es un sistema determinista lineal. El análisis discriminante tiene una tarea diferente, construye modelos para el reconocimiento de patrones basados en descripciones externas del sistema.
Si clasificar los indicadores para analizar los incrementos de precios no sirviera de nada, el análisis técnico carecería de sentido. Afortunadamente, el precio no se comporta de forma caótica, tiene memoria de acontecimientos anteriores.
Parece que tienes razón :-)
faa1947, tengo una pregunta para ti. Quería aclarar un par de cosas... así es como he calculado los datos de tu ecuación:
¿Coinciden los datos de la tabla con tu ecuación esquemática precio precio(-1) dac(-1) dao(-1) dbears(-1) dbulls(-1) cci(-1) dframa(-1) dmacdm(-1)?
Y obtuve el siguiente resultado:
Los datos brutos tienen el siguiente aspecto:
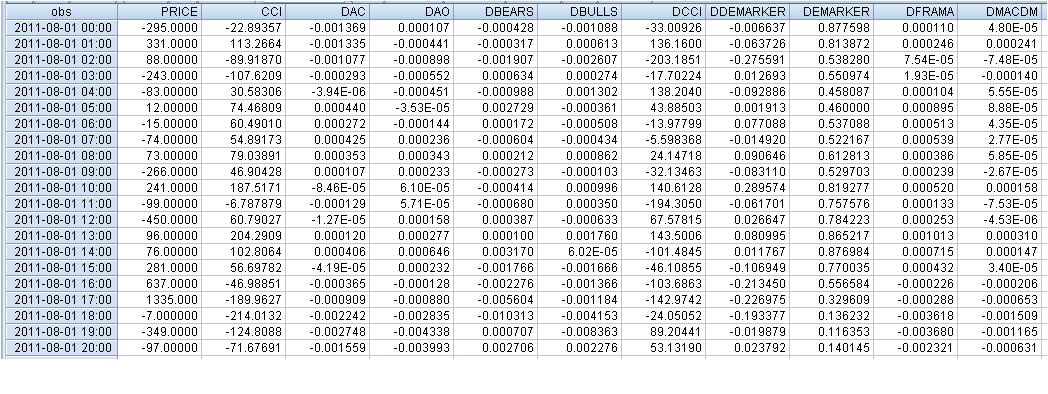
Las ecuaciones tienen el siguiente aspecto:
Ecuación de estimación:
=========================
PRICE = C(1)*PRICE(-1) + C(2)*DAC(-1) + C(3)*DAO(-1) + C(4)*DBEARS(-1) + C(5)*DBULLS(-1) + C(6)*CCI(-1) + C(7)*DFRAMA(-1) + C(8)*DMACDM(-1)
Coeficientes sustituidos:
=========================
PRECIO = -0.0228102658125*PRECIO(-1) + 12005.8974278*DAC(-1) + 4033.10946937*DAO(-1) + 3176.11232129*DBEARS(-1) - 6021.36196728*DBULLS(-1) - 0.102710105369*CCI(-1) - 11487.4273249*DFRAMA(-1) + 62535.3387412*DMACDM(-1)
No entiendo tu cálculo. Tengo el principio de utilizar el valor de retardo (valor anterior). Esto permite hacer una predicción. Si el retardo -1 corresponde a la 1ª observación, entonces la variable dependiente corresponde a una observación nueva, predicha y no observada.
¿Qué es el nivel p? Para mí, es la probabilidad de que el coeficiente correspondiente sea cero.
Indique el nombre del método estadístico utilizado. ¿Se trata de una ecuación de regresión lineal en la que la entrada son los indicadores y la salida es el precio futuro? ¿Es correcto?
La regresión se estimó utilizando el método de los mínimos cuadrados. Se puede utilizar para hacer predicciones.
Esto no funcionará para Forex, ya que no es un sistema determinista lineal.
Si es lineal, lo es en un ejemplo concreto. No es determinista porque incluso los coeficientes se tratan como variables aleatorias. Todos los coeficientes no se calculan, sino que se estiman. La segunda columna muestra el error estándar de la estimación de los coeficientes. Tenga en cuenta que es enorme.
Si la clasificación de los indicadores para analizar los incrementos de precios fuera inútil, el análisis técnico carecería de sentido.
Exactamente, y me atrevo a asegurar que no soy el único que lo piensa. El AT no es una ciencia, sino un tipo de astrología. Originalmente, hace 300 años, era un sistema para visualizar el kotir. Desde entonces ha evolucionado enormemente. Todo lo demás es para los pinocchios en el campo de los milagros. Me ha gustado tu artículo, ya que tiene un pensamiento regular y repetible.
Si la clasificación de indicadores para analizar el incremento del precio era inútil
Aquí hemos analizado un caso especial de indicadores. Siempre es necesario demostrar que un determinado indicador o su uso tiene algo que ver con una cotización. El AT nunca tiene en cuenta esta cuestión.
Afortunadamente, el precio no se comporta de forma caótica, tiene memoria de acontecimientos anteriores.
Toda la econometría se basa en el supuesto de que una cotización tiene un componente determinista (autocorrelación, memoria) y ruido.
El análisis discriminante tiene una tarea diferente, construye modelos para el reconocimiento de patrones basándose en descripciones externas del sistema.
La tarea está clara. Pero la cuestión es si el resultado obtenido es fiable. El problema no es la clasificación (eso forma parte del problema, que también hay que resolver), sino la confianza en la predicción resultante. Ese es exactamente el problema.
No entiendo su cálculo. Mi principio es utilizar el valor de retardo (valor anterior). Esto permite hacer una predicción. Si el lag -1 corresponde a la 1ª observación, entonces la variable dependiente corresponde a una nueva observación, predicha y no observada.
¿Qué es el nivel p? Para mí, es la probabilidad de que el coeficiente correspondiente sea cero.
faa1947, he dado la tabla con rezagos (para las primeras filas - no puedo ajustar toda la tabla). Pero primero he calculado las diferencias de los indicadores, por lo que el número total de filas es 1073 en lugar de 1074. Luego he adelantado un paso la variable dependiente Price.
Resultó que, en el ejemplo de la 1ª línea
331 = C(1)*(-295) + C(2)* 0,000034+ C(3)* (-0,00055) + C(4)* 0,000111 + C(5)* 0,001701+ C(6)*136,16+ C(7)* 0,000137+ C(8)*0,00016, siempre que
PRECIO = C(1)*PRECIO(-1) + C(2)*DAC(-1) + C(3)*DAO(-1) + C(4)*DBEARS(-1) + C(5)*DBULLS(-1) + C(6)*CCI(-1) + C(7)*DFRAMA(-1) + C(8)*DMACDM(-1)
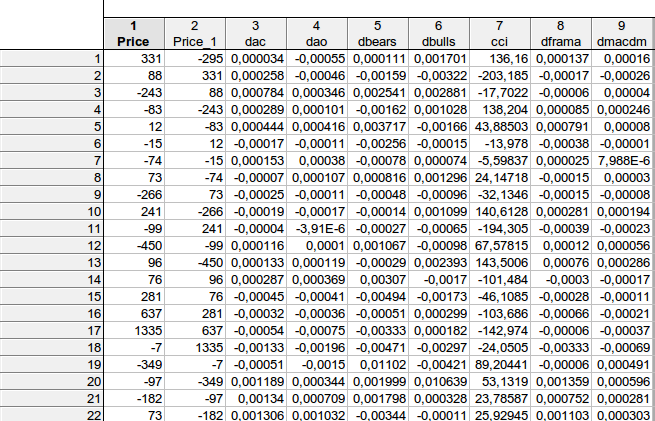
En general, obtuve aproximadamente un resultado similar: no hay forma de rechazar la hipótesis nula de que los coeficientes considerados sean iguales a cero...
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Uso del análisis discriminante para desarrollar sistemas de trading:
Al desarrollar un sistema de trading, surge normalmente un problema en relación a la elección de la mejor combinación de indicadores y sus señales. El análisis discriminante es uno de los métodos que existen para encontrar esas combinaciones. El artículo muestra un ejemplo del desarrollo de un EA para la recogida de datos del mercado y explica el uso del análisis discriminante para crear modelos de pronóstico para el mercado FOREX en el software Statistica.
Autor: ArtemGaleev