Machine learning in trading: theory, models, practice and algo-trading - page 1258
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
a lot of formulas ((
Well ) there is a link to the R package. I don't use R myself, I just understand the formulas.
if you use R, try it )
Well ) there is a link to the R package. I don't use R myself, I just understand the formulas.
If you use R, try it )
This morning's article is still open: https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
The most disappointing fact is that I could not find a Python implementation of this algorithm. The authors created an R package(BayesTrees) that had some obvious problems - mostly the lack of a "predict" function - and another, more widely used implementation called bartMachine was created.
If you have experience implementing this technique or know of a Python library, please leave a link in the comments!
So first package is useless, because it can't predict.
The second link has formulas again.
Here is an ordinary tree that is easy to understand. Everything is simple and logical. And without formulas.
Perhaps I haven't gotten to the libs yet. Trees are just a special case of a huge Bayesian topic, for example here is a bunch of examples of books and videos
I used Bayesian optimization of hyperparameters of NS according to Vladimir's articles. It works well.For example that trees... there are Bayesian neural networks
Unexpectedly!
NS work with mathematical operations + and * and may construct within themselves any indicator from MA to digital filters.
And trees are divided into right and left parts by simple if(x<v){left branch}else{right branch}.
Or is it also if(x<v){left branch}else{right branch}?
But if there are a lot of variables to optimize, it's oooo long.
Unexpectedly!
NS work with mathematical operations + and * and may construct within itself any indicator from MA to digital filters.
Trees are divided into right and left parts by simple if(x<v){left branch}else{right branch}.
Or is baisian NS also if(x<v){left branch}else{right branch}?
Yes, slowly, that's why I'm pulling from there useful knowledge so far, gives an understanding of some things
No, in Bayesian NS, the weights are simply optimized by sampling the weights from the distributions, and the output is also a distribution that contains a bunch of choices, but has a mean, variance, etc. In other words, it sort of captures a lot of variants that are not actually in the training dataset, but they are, a priori, assumed. The more samples are fed into such NS, the closer it converges to a regular one, i.e. Bayesian approaches are initially for not very large datasets. This is what I know so far.
I.e. such NS do not need very large datasets, the results will converge to conventional ones. But after training, the output will be not a point estimation, but a probability distribution for each sample.
Yes, slowly, that's why I'm pulling from there useful knowledge so far, gives an understanding of some things
No, in Bayesian NS, the weights are simply optimized by sampling the weights from the distributions, and the output is also a distribution that contains a bunch of choices, but has a mean, variance, etc. In other words, it sort of captures a lot of variants that are not actually in the training dataset, but they are, a priori, assumed. The more samples are fed into such NS, the closer it converges to the usual one, i.e. Bayesian approaches are initially for not very large datasets. This is what I know so far.
I.e. such NS do not need very large datasets, the results will converge to conventional ones. But the output after training will not be a point estimate, but a probability distribution, for each sample
You're running around like you're on speeds, one thing at a time, another thing at a time... and it's useless.
You seem to have a lot of free time, like some gentleman, you need to work, work hard, and strive for career growth, rather than from neural networks to baeses.
Believe me, no one at any normal brokerage houses will give you money for scientific verbiage and articles, only equity confirmed by the world's prime brokers.I do not rush, but I study consistently from simple to complex
If you don't have a job, I can offer you, for example, to rewrite something in mql.
I work for the landlord as well as everyone else, it's strange that you do not work, you are the landlord, the heir, the golden boy, a normal man if he loses his job in three months on the street, in six months he is dead.
If there's nothing on the subject of MO in trading - then take a walk, you'll think you're the only beggars here.)
I showed them all on the MO, honestly, without any childish secrets, as all the lame-o's are coding here, the error in the test is 10-15%, but the market is constantly changing, the trade does not go, chatter near zero
In short, go away, Vasya, I'm not interested in whining
All you do is whine, there are no results, you dig forks in the water and that's it, but you do not have the courage to admit that you are wasting your time
You should join the army or at least work at a construction site with men physically, you would improve your character.Yes, slowly, that's why I'm pulling from there useful knowledge so far, gives an understanding of some things
No, in Bayesian NS, the weights are simply optimized by sampling the weights from the distributions, and the output is also a distribution that contains a bunch of choices, but has a mean, variance, etc. In other words, it sort of captures a lot of variants that are not actually in the training dataset, but they are, a priori, assumed. The more samples are fed into such NS, the closer it converges to a regular one, i.e. Bayesian approaches are initially for not very large datasets. This is what I know so far.
I.e. such NS does not need very large datasets, the results will converge to conventional ones.
Here's from https://www.mql5.com/ru/forum/226219 comments on Vladimir's article on Bayesian optimization, how it plots the curve over multiple points. But then they don't need NS/forests either - you can just look for the answer right on this curve.
Another problem - if the optimizer is undertrained, then it will teach NS some incomprehensible crap.
 sample taught
sample taught 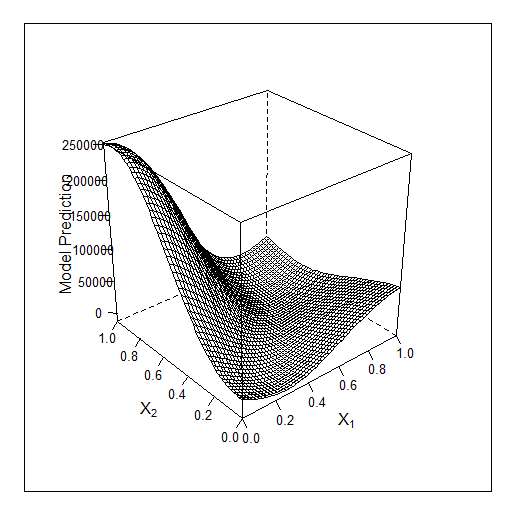
Here for 3 features Bayes work
It's the morons in this thread that make it no fun to talk about.
whining to themselves.
So what is there to talk about with you? You just collect links and different science collecting to impress the newcomers, SanSanych has already written everything in his article, you can add little, now there are all sorts of sellers and article writers smeared their pitchforks all in shame and shame even disgusting. They make "mathematicians" of themselves, "quantum" .....
If you want math try reading thishttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf
And you will not understand you are not a mathematician, but a flake.