Diskussion zum Artikel "Monte Carlo Permutationstests im MetaTrader 5"
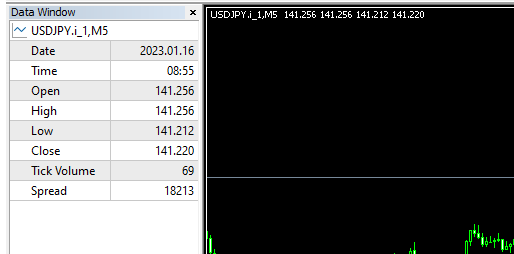
Hallo zusammen! Dieser Artikel bietet wertvolle Einblicke, und ich habe schon seit geraumer Zeit nach ihm gesucht. Allerdings bin ich bei der Verwendung des von Ihnen genannten Beispiels auf ein Problem gestoßen. Der Spread scheint aufgrund des Briefkurses recht groß zu sein. Könnten Sie mir bitte sagen, ob ich etwas übersehe oder ob es sich um einen Fehler handelt?
Soweit ich das beurteilen kann, kann ich keinen Fehler finden. Bei meinen eigenen Tests bin ich auch auf Preisreihenvariationen mit großen Spreads gestoßen. Das kann vorkommen. Wenn dies nicht akzeptabel ist, können Sie einfach mehr Permutationen durchführen und mit Serien mit realistischeren Spreads testen.
//---Tausch von Tickdaten nach dem Zufallsprinzip
tempvalue.bid_d=m_differenced[i].bid_d;
tempvalue.ask_d=m_differenced[i].ask_d;
tempvalue.vol_d=m_differenced[i].vol_d;
tempvalue.volreal_d=m_differenced[i].volreal_d;
m_differenced[i].bid_d=m_differenced[j].bid_d;
m_differenced[i].ask_d=m_differenced[j].ask_d;
m_differenced[i].vol_d=m_differenced[j].vol_d;
m_differenced[i].volreal_d=m_differenced[j].volreal_d;
m_differenced[j].bid_d=tempvalue.bid_d;
m_differenced[j].ask_d=tempvalue.ask_d;
m_differenced[j].vol_d=tempvalue.vol_d;
m_differenced[j].volreal_d=tempvalue.volreal_d; Swap(m_differenced[i], m_differenced[j]);
template < typename T> void Swap( T &Value1, T &Value2 ) { const T Value = Value1; Value1 = Value2; Value2 = Value; }
Die gleiche Bemerkung gilt für die Methoden des Logarithmus und der inversen Transformation von Strukturdaten. Und so weiter.
Die Tick-Konvertierung ist ein seltenes Thema. Normalerweise wird dies nur mit einem Preis (z.B. Bid) und auf Balken durchgeführt.
Ich bin dem Autor dankbar, dass er dieses Thema aufgegriffen hat.
Vor kurzem gab es ein Thema in einem russischsprachigen Thread zu diesem Thema. Dort wurde mit den besten Methoden des maschinellen Lernens versucht, eine Tick-Historie so zu generieren, dass sie die Marktmuster nicht verliert. Es gab ein klares Kriterium.
Leider sind alle Versuche, die Muster nicht zu verlieren, gescheitert. Es gab viel ausgefeiltere Methoden als nur das Mischen von Ticks.
Nur hier ist etwas Erfolgreiches passiert.
Форум по трейдингу, автоматическим торговым системам и тестированию торговых стратегий
Машинное обучение в трейдинге: теория, модели, практика и алготорговля
fxsaber, 2023.09.07 07:33
Ich habe mehrere Algorithmen ausprobiert. Für Klarheit, hier sind ein paar von ihnen.
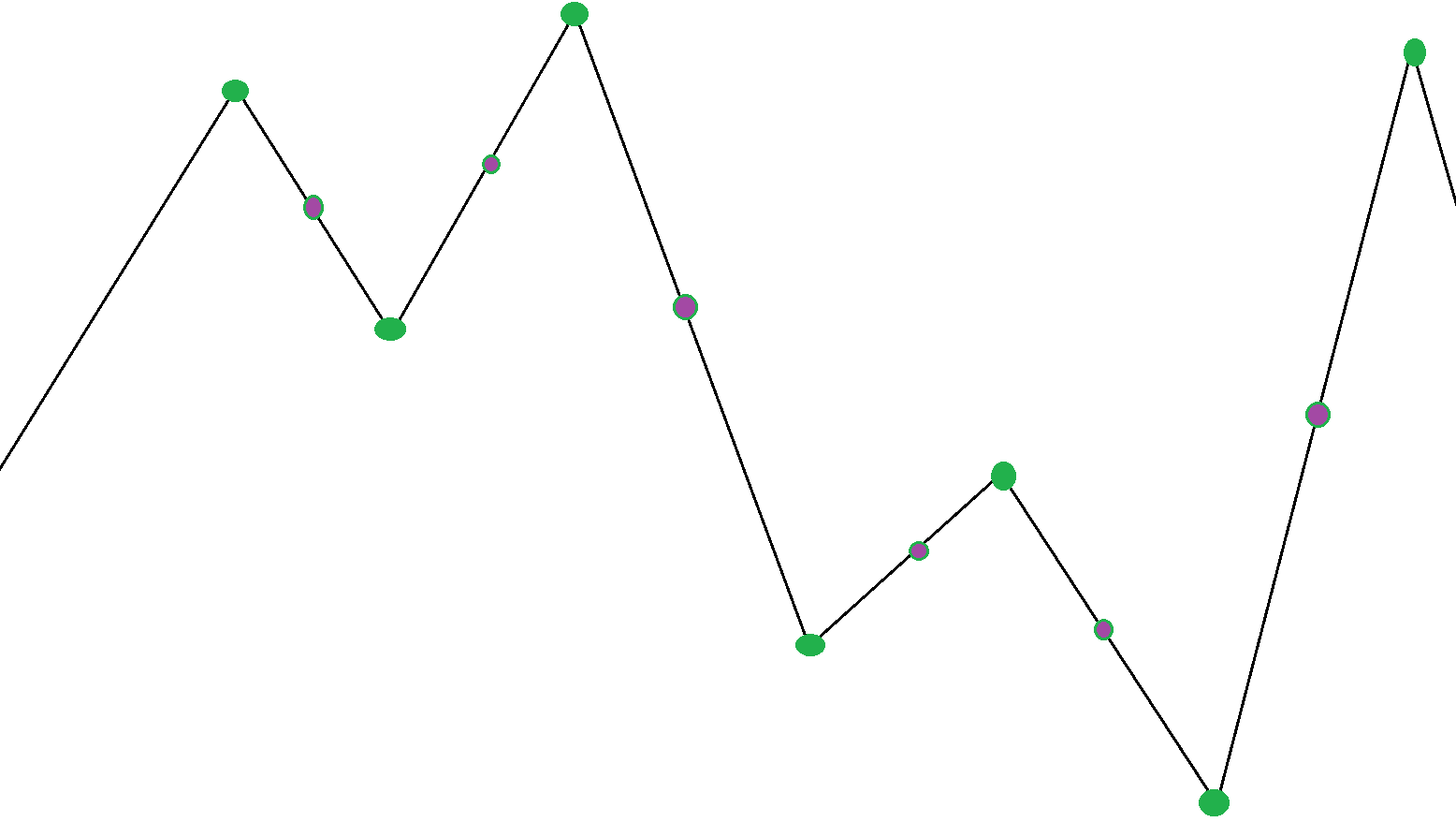
Der PO wird zum Avg-Preis mit der Bedingung gebaut, fest zu sein. min. Knie
- Grüne Punkte sind Indizesvon 3Z Scheitelpunkten im Teak-Array.
- Lila - der durchschnittliche Index zwischen den Scheitelpunkten.
Die Idee ist, das Array der Ticks zu durchlaufen und zufällig weitere Inkremente an den Stellen der gefundenen Indizes zuzuweisen.
Es stellt sich heraus, dass die Zeitstempel, die absoluten Werte der Inkremente (Avg-Preis) und die Spreads vollständig erhalten bleiben.
Entsprechend den Ergebnissen.
- Ich laufe nur auf grünen Indizes - Abfluss. Offensichtlich, wie Randomisierung begradigt (reduziert die Anzahl der ZZ) die endgültige Grafik.
- Ich laufe nur auf lila -der Gral ist stärker, je höher die minimale Bedingung.
- Ich laufe auf beiden Farben - Pflaume.
- 2023.09.03
- www.mql5.com
//+------------------------------------------------------------------+ //|Helfer-Methode zur Anwendung der Log-Transformation | //+------------------------------------------------------------------+ bool CPermuteTicks::LogTransformTicks(void) { //--bei Bedarf die Größe von m_logticks ändern if(m_logticks.Size()!=m_ticks.Size()) ArrayResize(m_logticks,m_ticks.Size()); //---nur relevante Datenelemente logarithmieren, negative und Nullwerte vermeiden for(uint i=0; i<m_ticks.Size(); i++) { m_logticks[i].bid_d=(m_ticks[i].bid>0)?MathLog(m_ticks[i].bid):MathLog(1 e0); m_logticks[i].ask_d=(m_ticks[i].ask>0)?MathLog(m_ticks[i].ask):MathLog(1 e0); m_logticks[i].vol_d=(m_ticks[i].volume>0)?MathLog(m_ticks[i].volume):MathLog(1 e0); m_logticks[i].volreal_d=(m_ticks[i].volume_real>0)?MathLog(m_ticks[i].volume_real):MathLog(1 e0); } //--- return true; }
мы хотим, чтобы p-значения были как можно ближе к нулю, в диапазоне 0,05 и ниже.
Die vollständige Formel ist unten angegeben:
z+1/r+1
wobei r die Anzahl der durchgeführten Permutationen und z die Gesamtzahl der Tests mit der besten Leistung ist.
Dieses Kriterium funktioniert in diesem Fall nicht - es wurde für das ursprüngliche Symbol optimiert und dann auf Permutationen angewendet.
Der verwendete Permutationsalgorithmus.
- Es wird ein Array mit logarithmischen Inkrementen (zwischen benachbarten Ticks) Geld/Brief erstellt.
- Dieses Array wird gemischt. Außerdem wird es stark gemischt.
- Ein neues Array von Ticks wird durch Inkremente aus Punkt 2 erstellt.
Dieser Ansatz tötet alle Regelmäßigkeiten (falls es welche gab), die in der ursprünglichen Reihe enthalten waren. Denn die Ausgabe ist ein Random Walk.
Es sollte nicht auf diese Weise gemacht werden.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Monte Carlo Permutationstests im MetaTrader 5 :
In diesem Artikel sehen wir uns an, wie wir Permutationstests auf der Grundlage von vermischten Tick-Daten für jeden Expert Advisor durchführen können, der nur Metatrader 5 verwendet.
Nachdem Sie die Datei exportiert haben, notieren Sie sich natürlich, wo sie gespeichert ist, und öffnen Sie sie mit einem beliebigen Tabellenkalkulationsprogramm. Die folgende Grafik zeigt die Verwendung des kostenlosen OpenOffice Calc, bei der eine neue Zeile am unteren Rand der Tabelle hinzugefügt wurde. Bevor Sie weitermachen, sollten Sie Zeilen mit Symbolen entfernen, die nicht in die Berechnungen einfließen sollen. Unter jeder entsprechenden Spalte wird der p-Wert mithilfe eines nutzerdefinierten Makros berechnet. Die Formel des Makros verweist auf die Leistungskennzahlen des permutierten Symbols (im gezeigten Dokument in Zeile 18) sowie auf die der permutierten Symbole für jede Spalte. Die vollständige Formel für das Makro ist in der Grafik dargestellt.
Neben einer Tabellenkalkulation könnten wir auch Python verwenden, das über eine Fülle von Modulen zum Parsen von XML-Dateien verfügt. Wenn ein Nutzer mql5 beherrscht, kann er die Dateien auch mit einem einfachen Skript parsen. Denken Sie nur daran, ein zugängliches Verzeichnis zu wählen, wenn Sie die Optimierungsergebnisse aus dem Testgerät exportieren.
Autor: Francis Dube