文章 "无需 Python 或 R 语言知识的 Yandex CatBoost 机器学习算法" - 页 3 12345678 新评论 Aleksey Vyazmikin 2020.11.11 11:08 #21 Andrey Dibrov: 啊,试着重复同样的实验,只是在训练样本中再添加一两个月的历史数据,然后比较两次测试的结果。神经网络是否会保持稳定,最近的价格变动对这个模型有什么影响...... 小心--这不是神经网络,而是梯度脉冲 法--一种非常不同的寻找模式的方法,尽管两者都是机器学习方法。 我确信短样本的数据很少,但为了满足读者的好奇心,我现在正在训练样本: 1. 不同树数的一年窗口 - 让我们来比较一下结果。(没有使用对照样本) 2.不同树木数量的第 3 年窗口 - 比较结果。(未使用对照样本) 3.一年的窗口,每月添加新数据,树的数量不同 - 比较结果。(不使用控制样本) 您需要等待计算过程完成--有许多模型正在构建中。 Valeriy Yastremskiy 2020.11.11 11:25 #22 Aleksey Vyazmikin:让我们从抽象转向数字。一扇小窗户能发挥多大作用?问题的关键在于,你建议跟着市场行情跳,而我建议利用关于不同市场行情的知识。以历史为支撑的知识越多,建立在历史基础上的模式变化就越慢。 然后,你如何在小样本上定义超参数--至少需要多少次训练迭代。我认为到处都一样。 宽度至少要和稳定状态的宽度一样宽,这样才能获得收益。我并不是建议这样做,我意识到这对今天来说很难。我的想法是,学习在稳定状态下是有成效的。也就是说,在稳定的 BP 状态上进行训练的结果会比在相同数量的数据上更好,但 BP 状态会由不同稳定状态的几个片段组成。 Aleksey Vyazmikin 2020.11.11 11:33 #23 Valeriy Yastremskiy:宽度至少应与您可以获利的稳定状态的宽度相同。我并不是建议这样做,我意识到这对今天来说很困难。从条款中可以看出,在稳定状态下学习是有效的。也就是说,在稳定的 BP 状态上进行训练的结果会比在相同数量的数据上更好,但 BP 状态会由不同稳定状态的几个片段组成。 因此,只有在检测到新的市场状态后,我们才能找出最佳宽度。 在本文中,我们并没有使用纯粹形式的时间序列,因为数据收集是基于某种市场状态的,而且不同状态之间有不同的条数。 Andrey Dibrov 2020.11.11 13:22 #24 Aleksey Vyazmikin:小心--这不是神经网络,而是梯度剔除法--一种非常不同的寻找模式的方法,尽管这两种方法都与机器学习有关。我相信短样本的数据是稀缺的,但我现在正在训练样本,以满足读者的好奇心:1. 不同树数的一年窗口 - 让我们来比较一下结果。(没有使用对照样本)2.不同树木数量的第 3 年窗口 - 比较结果。(未使用对照样本)3.一年的窗口,每月添加新数据,树的数量不同 - 比较结果。(未使用对照样本)我们必须等待计算过程完成--有许多模型正在构建中。 没错...对我来说,有趣的问题是--梯度突变 能否用来寻找模式,在此基础上采样数据以训练神经网络?这就是如何利用根据不同市场模式训练的神经网络找到对冲交易解决方案的问题... Aleksey Vyazmikin 2020.11.11 13:44 #25 Andrey Dibrov:没错...对我来说,有趣的问题是--梯度突变能否用来寻找模式,在此基础上采样数据以训练神经网络?这就是如何利用在不同市场模式下训练的神经网络找到对冲交易解决方案的问题...在不对样本进行神经网络实验的情况下,您打算如何得到问题的答案?我们可以估算预测器在一段时间内的表现,例如来自 "外面的东西 "的收盘百分比--您可以在图表中看到,偏差在各行(样本的每行 N 行)中各不相同--如果我们取样本的 1/10,当指标横向移动时,我们将无法获得足够的信息(例如,它取决于顶部 TF 的全球趋势)。 顺便提一下,图中显示了如何以 SatBoost 网格的形式对数据进行分区(量化)。 Aleksey Vyazmikin 2020.11.11 16:12 #26 到目前为止,第一个版本已经完成: 1. 不同树木数量的年份窗口 - 让我们来比较一下结果。(不使用对照样本) 400 棵树不够,1600 棵树太多。 曲线的动态相似,有什么原因吗? Valeriy Yastremskiy 2020.11.11 16:28 #27 Aleksey Vyazmikin:初稿已经准备就绪:1. 树木数量不同的一年的窗口 - 让我们比较一下结果。(不使用对照样本) 400 棵树不够,1600 棵树太多。曲线的动态相似,有什么原因吗? 200 棵树的信息量不够,而 1600 棵树的信息量有损失,或者说无法识别重要信息。 Aleksey Vyazmikin 2020.11.11 19:47 #28 Valeriy Yastremskiy:200 是信息缺失,1600 是信息丢失,或无法识别重要信息。 在训练过程中,信息是稳定不变的,但记忆条件的记忆量是不同的。我认为,前十棵树的相似性决定了模型行为的基本逻辑,再往后只有改进,这就是为什么曲线的断点相似。 Aleksey Vyazmikin 2020.11.11 21:21 #29 2.第 3 年的窗口,树的数量不同 - 比较结果。(未使用对照样本) 我们再次观察到 800 次迭代是最佳的,因此对于第三个变量,我没有做更多的迭代。令人困惑的是,在 2020 年 3 月出现了严重的失败--这究竟是危机的影响超出了模型的范围,还是采样错误--我是在粘合时进行训练的,可能由于过渡到新的期货合约而出现了间隙,这在现实生活中并没有发生。从积极的方面看,学习效果明显好于 12 个月(见上一张图表中的这一时间段!),这是很好的现象,也再次说明 12 个月并不能适应市场的所有变化。 3. 窗口期为一年,每月添加新数据,树的数量不同 - 让我们比较一下结果。(不使用对照样本) 从图中可以看出,迭代 400 次的模型增长较快,或者说是一致的,但随着样本量的增加,趋势发生了变化,迭代 800 次的模型开始拉开距离,误差更小,月份封闭性更好。显然,我们需要动态地增加模型规模。 从这项研究中,我们可以得出结论,文章中概述的方法和获得的结果并非侥幸。 是的,我同意价格行为会发生重大变化,而且旧的行为不会重复,相应地,在一个大周期内取样会阻止你在新数据上赚钱。在模型上识别价格行为的可变性有待进一步研究,但我更倾向于使用尽可能多的价格信息,尽管这些信息稍显过时。 Aleksey Vyazmikin 2020.11.11 23:15 #30 下图提供了有关召回的信息--蓝色柱状图是样本累积模型,红色柱状图是 12 个月固定窗口模型。 可以看出,12 个月的模型试图适应当前的市场形势,在一些低波动期的召回率较高,而明确在 2020 年进行积累的模型则利用了 2014-2016 年波动加剧的经验,能够识别 2020 年危机期间的强烈波动。 12345678 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
啊,试着重复同样的实验,只是在训练样本中再添加一两个月的历史数据,然后比较两次测试的结果。神经网络是否会保持稳定,最近的价格变动对这个模型有什么影响......
小心--这不是神经网络,而是梯度脉冲 法--一种非常不同的寻找模式的方法,尽管两者都是机器学习方法。
我确信短样本的数据很少,但为了满足读者的好奇心,我现在正在训练样本:
1. 不同树数的一年窗口 - 让我们来比较一下结果。(没有使用对照样本)
2.不同树木数量的第 3 年窗口 - 比较结果。(未使用对照样本)
3.一年的窗口,每月添加新数据,树的数量不同 - 比较结果。(不使用控制样本)
您需要等待计算过程完成--有许多模型正在构建中。
让我们从抽象转向数字。一扇小窗户能发挥多大作用?
问题的关键在于,你建议跟着市场行情跳,而我建议利用关于不同市场行情的知识。以历史为支撑的知识越多,建立在历史基础上的模式变化就越慢。
然后,你如何在小样本上定义超参数--至少需要多少次训练迭代。我认为到处都一样。宽度至少要和稳定状态的宽度一样宽,这样才能获得收益。我并不是建议这样做,我意识到这对今天来说很难。我的想法是,学习在稳定状态下是有成效的。也就是说,在稳定的 BP 状态上进行训练的结果会比在相同数量的数据上更好,但 BP 状态会由不同稳定状态的几个片段组成。
宽度至少应与您可以获利的稳定状态的宽度相同。我并不是建议这样做,我意识到这对今天来说很困难。从条款中可以看出,在稳定状态下学习是有效的。也就是说,在稳定的 BP 状态上进行训练的结果会比在相同数量的数据上更好,但 BP 状态会由不同稳定状态的几个片段组成。
因此,只有在检测到新的市场状态后,我们才能找出最佳宽度。
在本文中,我们并没有使用纯粹形式的时间序列,因为数据收集是基于某种市场状态的,而且不同状态之间有不同的条数。
小心--这不是神经网络,而是梯度剔除法--一种非常不同的寻找模式的方法,尽管这两种方法都与机器学习有关。
我相信短样本的数据是稀缺的,但我现在正在训练样本,以满足读者的好奇心:
1. 不同树数的一年窗口 - 让我们来比较一下结果。(没有使用对照样本)
2.不同树木数量的第 3 年窗口 - 比较结果。(未使用对照样本)
3.一年的窗口,每月添加新数据,树的数量不同 - 比较结果。(未使用对照样本)
我们必须等待计算过程完成--有许多模型正在构建中。
没错...对我来说,有趣的问题是--梯度突变 能否用来寻找模式,在此基础上采样数据以训练神经网络?这就是如何利用根据不同市场模式训练的神经网络找到对冲交易解决方案的问题...
没错...对我来说,有趣的问题是--梯度突变能否用来寻找模式,在此基础上采样数据以训练神经网络?这就是如何利用在不同市场模式下训练的神经网络找到对冲交易解决方案的问题...
在不对样本进行神经网络实验的情况下,您打算如何得到问题的答案?
我们可以估算预测器在一段时间内的表现,例如来自 "外面的东西 "的收盘百分比--您可以在图表中看到,偏差在各行(样本的每行 N 行)中各不相同--如果我们取样本的 1/10,当指标横向移动时,我们将无法获得足够的信息(例如,它取决于顶部 TF 的全球趋势)。
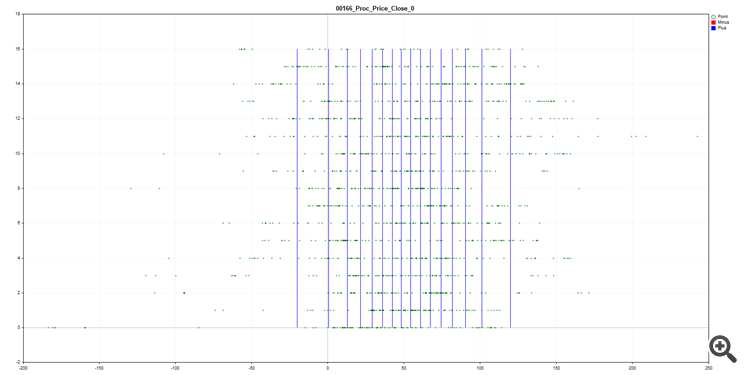
顺便提一下,图中显示了如何以 SatBoost 网格的形式对数据进行分区(量化)。到目前为止,第一个版本已经完成:
1. 不同树木数量的年份窗口 - 让我们来比较一下结果。(不使用对照样本)
400 棵树不够,1600 棵树太多。
曲线的动态相似,有什么原因吗?
初稿已经准备就绪:
1. 树木数量不同的一年的窗口 - 让我们比较一下结果。(不使用对照样本)
400 棵树不够,1600 棵树太多。
曲线的动态相似,有什么原因吗?
200 棵树的信息量不够,而 1600 棵树的信息量有损失,或者说无法识别重要信息。
200 是信息缺失,1600 是信息丢失,或无法识别重要信息。
在训练过程中,信息是稳定不变的,但记忆条件的记忆量是不同的。我认为,前十棵树的相似性决定了模型行为的基本逻辑,再往后只有改进,这就是为什么曲线的断点相似。
2.第 3 年的窗口,树的数量不同 - 比较结果。(未使用对照样本)
我们再次观察到 800 次迭代是最佳的,因此对于第三个变量,我没有做更多的迭代。令人困惑的是,在 2020 年 3 月出现了严重的失败--这究竟是危机的影响超出了模型的范围,还是采样错误--我是在粘合时进行训练的,可能由于过渡到新的期货合约而出现了间隙,这在现实生活中并没有发生。从积极的方面看,学习效果明显好于 12 个月(见上一张图表中的这一时间段!),这是很好的现象,也再次说明 12 个月并不能适应市场的所有变化。
3. 窗口期为一年,每月添加新数据,树的数量不同 - 让我们比较一下结果。(不使用对照样本)
从图中可以看出,迭代 400 次的模型增长较快,或者说是一致的,但随着样本量的增加,趋势发生了变化,迭代 800 次的模型开始拉开距离,误差更小,月份封闭性更好。显然,我们需要动态地增加模型规模。
从这项研究中,我们可以得出结论,文章中概述的方法和获得的结果并非侥幸。
是的,我同意价格行为会发生重大变化,而且旧的行为不会重复,相应地,在一个大周期内取样会阻止你在新数据上赚钱。在模型上识别价格行为的可变性有待进一步研究,但我更倾向于使用尽可能多的价格信息,尽管这些信息稍显过时。
下图提供了有关召回的信息--蓝色柱状图是样本累积模型,红色柱状图是 12 个月固定窗口模型。
可以看出,12 个月的模型试图适应当前的市场形势,在一些低波动期的召回率较高,而明确在 2020 年进行积累的模型则利用了 2014-2016 年波动加剧的经验,能够识别 2020 年危机期间的强烈波动。