Bu kaosun bir düzeni var mı? Hadi bulmaya çalışalım! Belirli bir örnek üzerinde makine öğrenimi. - sayfa 21
Alım-satım fırsatlarını kaçırıyorsunuz:
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Kayıt
Giriş yap
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Hesabınız yoksa, lütfen kaydolun
Bu örneklemden iki yıl daha kestim ve Sınav ortalaması şimdiden -485 oldu ( 1214 idi) ve 3000 puan sınırını geçen model sayısı 884 oldu ( geçen sefer 277 idi).
Ancak, test örneğindeki sonuçlar ortalama 2115 puandan 186 puana, yani önemli ölçüde kötüleşmiştir. Bu nedir - tren örneğinde test örneğine benzer daha az örnek mi var?
Ortalama ağaç sayısı 10'dan 7'ye düşmüştür.
Grafikteki sıfır kırılması denge dağılımını merkeze kaydırmıştır.
Sonucun teste benzer olması gerektiği ifadesinin temeli nedir? Örneklerin homojen olmadığını varsayıyorum - içlerinde karşılaştırılabilir sayıda benzer örnek yok ve kuantlar üzerindeki olasılık dağılımlarının biraz farklı olduğunu düşünüyorum.
Traine. İyi örüntülerin olduğu verilerden bahsediyorum. Çarpım tablosunun 1000 varyantını eğitime sokarsanız, traine ile asla eşleşmeyen (ancak traine sınırları içinde olan) yeni varyantlar da oldukça iyi hesaplanacaktır. 1 ağaç en yakın varyantı verecektir, rastgele bir orman en yakın yüz tanesinin ortalamasını alacak ve büyük olasılıkla 1 ağaçtan daha doğru bir cevap verecektir.
Piyasa için düzenli tahminciler bulunabilirse, OOS da bir izlemeye benzer olacaktır. Ancak şu anki gibi modellerin yarısından fazlası eksi ve üçte biri artı değil. Tüm başarılı modeller rastgele tohumdan şans eseri bu hale geldi.
Tohum, modelin başarısını sadece biraz değiştirmeli ve genel olarak hepsi başarılı olmalıdır. Şimdi hiçbir model bulunmadığı ortaya çıktı (aşırı eğitim / yetersiz eğitim).
Yalnızca eğitimin durdurulmasını kontrol etmek için kullanılır, yani tren üzerinde eğitim yapılırken test üzerinde herhangi bir gelişme olmazsa, eğitim durur ve ağaçlar test modelinde en son gelişmenin olduğu noktaya kadar kaldırılır.
O zaman testlerin de neden iyi olduğu anlaşılır. Bu aslında teste uyum sağlamaktır. Bunu 1 eğitim için yapmayı bıraktım. İleriye doğru değerleme yapıyorum, tüm OOC'leri birbirine yapıştırıyorum, ardından yapıştırılmış OOC'lerin birçok varyantından en iyi model hiperparametrelerini (derinlik, ağaç sayısı vb.) seçiyorum. Sınavın, tüm OOS'lerin seçilen yapıştırılmasıyla yaklaşık aynı olacağını varsayıyorum. Bu varyantta 5 yıl boyunca, haftada bir kez yeniden eğitim aldım - bu yüzlerce OOS eğitimi ve parçası.
Görünüşe göre kullandığım örneği açıkça belirtmemişim - bu, burada açıklanan deneyin altıncı (son) örneği, dolayısıyla sadece 61 tahminci var.
Özellikle düz piyasa alanlarında ilkel stratejiler.Bu 61 taneyi 5000'den fazla kişi arasından seçtiniz. Benim toplam sayım daha az ve seçilenlerin sayısı daha az. Ve her seferinde 1 eklerken, seçilen 3-4 taneden sonra, daha fazla işaret eklenmesi yalnızca OOS üzerindeki sonucu kötüleştirir.
Genel olarak, daha fazla tahminci ekleyebilirim, çünkü şimdi sadece 3 TF ile kullanılıyorlar, birkaç istisna dışında - birkaç bin tane daha eklenebileceğini düşünüyorum, ancak 61 tahminci için 10000 tohum varyantının böyle bir yayılma sağladığı göz önüne alındığında.... hepsinin eğitimde düzgün kullanılıp kullanılmayacağı şüphelidir.
Ve tabii ki tahmin edicileri önceden taramanız gerekir, bu da eğitimi hızlandıracaktır.
Hepsi hemen hemen aynıysa, sonucu ciddi şekilde iyileştiren bir şey bulunması pek olası değildir. Tamamen yeni veriler veya benzersiz göstergeler deneyebilirsiniz.
Ön tarama da uzun bir iştir, her seferinde bir tane eklemek birçok kez daha uzundur, hatta 3 özelliğe kadar ve 10'a kadar ise, birçok gündür. Ancak bunun bir anlamı yoktur, 3-4 özellikten sonra genellikle hiçbir gelişme olmaz. Ancak bazen var, ancak artış küçük. Orada atılımlar bulunmadı (benim deneylerimde, birisi bulabilir).
Aykırı değerlerin aykırı değer olması mantıklıdır, ben sadece bunların beyaz gürültüyü ortadan kaldırarak öğrenilmesi gereken verimsizlikler olduğunu düşünüyorum. Diğer alanlarda, özellikle düz piyasa alanlarında basit ilkel stratejiler genellikle işe yarar.
Alttaki resim karlı, ancak 5 yıl içinde 2017'de güçlü büyümeye sahip sadece 2 dönem vardı (görünüşe göre güçlü bir öngörülebilir eğilim vardı), model en çok parayı bu 2 dönemde kazandı. Ve zaman içinde tekdüze bir büyümeye sahip olmak güzel olurdu. Böyle bir modeli bir aylık hareketsizlikten sonra kapatırdım.
Elbette bir EA yapabilirsiniz - beyaz kuğuları beklemek. Ama aktif ticareti tercih ederim.
Bu örneklemden iki yıl daha çıkarıldığında Sınav ortalaması şimdiden -485 ( -1214 idi) ve 3000 puan sınırını aşan model sayısı 884 ( geçen sefer 277 idi) olmuştur.
Ancak, test örneğindeki sonuçlar ortalama 2115 puandan 186 puana, yani önemli ölçüde kötüleşmiştir. Bu nedir - tren örneğinde test örneğine benzer daha az örnek mi var?
Ortalama ağaç sayısı 10'dan 7'ye düşmüştür.
Grafikteki sıfır kırılması denge dağılımını merkeze kaydırmıştır.
İlk gönderideki dosyaları gönderebilir misiniz, ben de bir fikir denemek istiyorum.
Traine. İyi örüntülerin olduğu verilerden bahsediyorum. Çarpım tablosunun 1000 varyantını eğitim için gönderirseniz, traine ile asla çakışmayan (ancak traine sınırları içinde) yeni varyantlar da iyi hesaplanacaktır. 1 ağaç en yakın varyantı verecektir, rastgele bir orman en yakın yüz tanesinin ortalamasını alacak ve büyük olasılıkla 1 ağaçtan daha doğru bir cevap verecektir.
Piyasa için düzenli tahminciler bulunabilirse, OOS da bir ize benzer olacaktır. Ancak şu anda olduğu gibi modellerin yarısından fazlası eksi ve üçte biri artı değil. Tüm başarılı modeller rastgele bir tohumdan kazara bu hale geldi.
Tohum, modelin başarısını çok az değiştirmeli ve genel olarak hepsi başarılı olmalıdır. Şimdi hiçbir modelin bulunmadığı ortaya çıktı (aşırı eğitim / yetersiz eğitim).
Kimse iyi verilerle her şeyin büyük olasılıkla mükemmel çalışacağını iddia etmiyor. Ancak, böyle bir veri elde edemezsiniz, bu yüzden elinizdekilerden ne çıkarabileceğinizi düşünmeniz gerekir.
Yeni veriler üzerinde etkili olacak etkili modelleri rastgele elde etmenin mümkün olması, bu rastgeleliğin nasıl azaltılacağını, yani modelin tutarlı bir şekilde inşa edildiği kuantum segmentleri için herhangi bir düzenli metrik olup olmadığını merak etmeme neden oluyor. Yani hedef üzerindeki açgözlülükten başka ek metriklerden bahsediyoruz. Bu tür bağımlılıklar kurulabilirse, modeller daha yüksek başarı olasılığı ile de oluşturulabilir. Elbette bu farklı örnekler üzerinde çalışmalıdır.
O zaman testlerin de neden iyi olduğunu anlayabiliyorum. Bu aslında teste uymaktır. Bunu 1 çalışma için yapmayı bıraktım. İleriye doğru değerleme yapıyorum, tüm OOC'leri birbirine yapıştırıyorum, ardından yapıştırılmış OOC'lerin birçok varyantı arasından en iyi model hiperparametrelerini (derinlik, ağaç sayısı, vb.) seçiyorum. Sınavın, tüm OOS'lerin seçilen yapıştırılmasıyla yaklaşık aynı olacağını varsayıyorum. Bu varyantta 5 yıl boyunca haftada bir kez yeniden eğitim aldım - bu yüzlerce OOS eğitimi ve yığını anlamına geliyor.
Önemli olan son sınav bölümünü ayırmamaktır.
Hiperparametreleri uydurmak ve sonucu neye göre değerlendirmek? Mantığınızı takip edersek, bunun bir ortalama unsuru ile aynı uydurma olduğunu düşünüyorum.
CatBoost'taki mantık, modeli iyileştirmek mümkün değilse (Logloss ile), daha fazla eğitimin bir anlamı olmadığıdır. Bu durumda elbette modelin iyi çıkacağına dair hiçbir garanti yoktur.
5000'den fazla arasından seçtiğin 61 tanesi. Elimde hem toplam sayı hem de seçilenlerin sayısı var. Ve her seferinde 1 eklerken, 3-4 seçilmiş olandan sonra, özelliklerin daha fazla eklenmesi sadece OOS üzerindeki sonucu kötüleştirir.
Hayır, onları ben seçmedim - tüm tahmin ediciler üzerinde eğitim yaparken onları modelden aldım.
Bakın, ben genellikle tahmin ediciyi bir kuantum segmentleri kümesi olarak görüyorum. Ve bu nedenle kuantum segmentlerini seçiyorum, genel olarak tüm tahmin edicileri ikili olanlara bile ayırabilirim - sonuç biraz daha kötü, ancak karşılaştırılabilir. Belki de ikili boşaltılmış tahmin ediciler için özel bir eğitim yöntemi gereklidir.
Hepsi hemen hemen aynıysa, sonucu ciddi şekilde iyileştiren herhangi bir şeyin zaten bulunması pek olası değildir. Tamamen yeni veriler veya benzersiz göstergeler deneyebilirsiniz.
"Yaklaşık aynı" derken neyi kastediyorsunuz, sanırım metriklerden mi bahsediyorsunuz? Elbette farklı veriler deneyebilir, örneğin farklı bir araç kullanabilirsiniz.
Ön eleme de uzun bir iş, tek tek eklemek çok daha uzun sürüyor, 3 özelliğe kadar bile, 10'a kadar ise günler sürüyor. ama bir anlamı yok, 3-4 özellikten sonra genelde bir gelişme olmuyor. Ama bazen var, ama artış küçük. Orada atılımlar bulunmadı (benim deneylerimde, birisi bulabilir).
Bahsettiğiniz varyant uzun bir oyun, bu yüzden oynamıyorum (yani, tam otomasyonum yok). Ancak, hiçbir etkisi olmadığına katılmıyorum - grupların azaltılmasıyla gruplar halinde bırakmalar yaptım - sonuç olumluydu. Ancak yine de bu eylemleri uydurmaya veya rastgeleliğe bağlıyorum - tahmin edicilerin seçimi için hiçbir gerekçe yok.
Alttaki rakam karlı, ancak 5 yıl içinde 2017'de güçlü büyümeye sahip sadece 2 dönem vardı (görünüşe göre güçlü bir öngörülebilir eğilim vardı), model en çok parayı bu 2 dönemde kazandı. Ve zaman içinde tekdüze bir büyümeye sahip olmak güzel olurdu. Böyle bir modeli bir ay kullanılmadığında kapatırdım.
Elbette, beyaz kuğuları bekleyen bir Uzman Danışman yapabilirsiniz. Ama ben aktif ticareti tercih ederim.
Bu nedenle, her birinin kendi sık olmayan modellerini yakalayabileceğini anladığım için model kümelerini kullanmaktan yanayım.
Genel olarak amaç, traine ve testteki hatanın yaklaşık olarak aynı olmasıdır. Burada Sınavınız traine ve teste doğru hareket ediyor, yani yukarı ve onlar teste doğru, yani aşağı. Aşırı antrenman azalır.
Peki hangi ölçüte göre benzerler?
Örneğin, Precision metriğini alıyoruz, test örneğindeki bu göstergeyi train'den çıkarıyoruz, - delta (y ekseni) elde ediyoruz ve x ile sınav örneğindeki kara bakıyoruz.
Özel bir bağımlılık yok mu, yoksa ne?
Aşağıda her örnek için iki metrik yer almaktadır - veriler modele yeni ağaçlar eklendikçe alınmaktadır.
İşte bu modelin özellikleri
Ve işte iki örnekte kayıpları olan başka bir modelin metrikleri
İşte modelin özellikleri
Forum tarzında cevap vermek, birçok kez cevapla butonuna tıklamak sakıncalı. Aşağıda cevaplarım renkli olarak vurgulanmıştır.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> Uzun zaman önce kuantumların nasıl oluşturulduğunu izledim, temel varyantlar. İlk olarak, sütun sıralanır.
1) aralığa göre, çift adımlı (örneğin 0'dan 1'e kadar tam olarak 0,1 değer adımıyla toplam 10 kuanta 0,1, 0,2, 0,3 ... 0.9)
2) yüzdelik dilim - yani örnek sayısına göre. Eğer 10 kuanta bölersek, o zaman her kuantuma tüm satırların sayısının %10'unu koyarız, eğer çok sayıda çift varsa, o zaman bazı kuantumlar %10'dan fazla olacaktır, çünkü çiftler diğer kuantumlara düşmemelidir, örneğin, eğer çiftler örneğin %30'u ise, o zaman bu kuantumda hepsi düşecektir. Her bir kuantumdaki örnek sayısına bağlı olarak dağılım 0.001, 0.12,0.45,0.51,0.74, .... şeklinde olabilir. 0.98.
3) her iki türün bir kombinasyonu vardır
Yani kuanta oluşturmanın süper zekice bir yanı yok. Bu niceleme yöntemlerinin her ikisini de kendim için yaptım. Ve her zaman olduğu gibi bir şeyi daha iyi olduğunu düşündüğüm şekilde yaptım. Belki bir hata yapmışımdır. Ve genellikle hesaplamaları nicelleştirme olmadan, ancak değişken veriler üzerinde yaparım.
Tüm tahmin edicileri ikili yaparsanız, yalnızca 2 kuantum olacaktır, biri tüm 0'lara ve diğeri tüm 1'lere sahip olacaktır.
Hiperparametreleri uyduruyorsunuz ve sonucu neye göre değerlendiriyorsunuz? Mantığınızı takip ederseniz, bunun bir ortalama elemanı ile aynı uydurma olduğunu düşünüyorum.
> Denge grafiklerine ve düşüşlere bakıyorum. Seçimi henüz otomatikleştiremedim. Evet, uyum daha iyi OOS yapıştırma içindir. Ancak modelin kendisi değil (yani iz değil), modelin en iyi hiperparametrelerinin seçimi.
"Yaklaşık aynı" derken neyi kastediyorsunuz, sanırım bazı metriklerden mi bahsediyorsunuz? Elbette başka verileri deneyebilir, örneğin başka bir araç kullanabilirsiniz.
> Bunların hepsi fiyatlar ve mashuplar üzerinden yapılır.
Eski bir soru üzerine.
Sonucun trenle benzer olması gerektiği ifadesinin dayanağı nedir? Örneklerin homojen olmadığını varsayıyorum - karşılaştırılabilir sayıda benzer örnek yok ve kuantların olasılık dağılımlarının biraz farklı olduğunu düşünüyorum.
> Örnekler burada https://www.mql5.com/ru/articles/3473
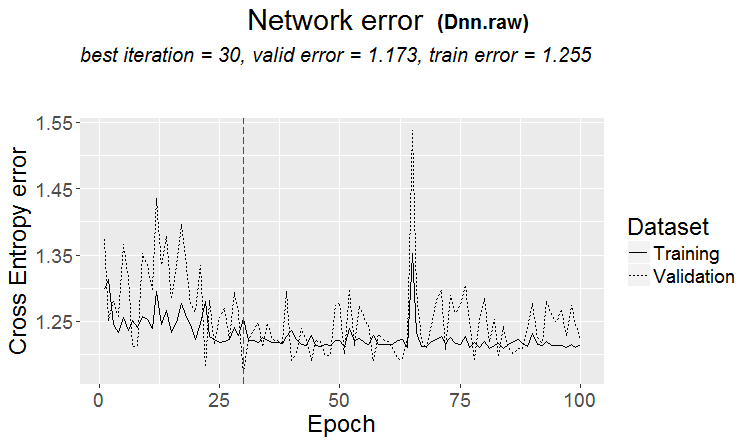
Bir model bulunduğunda iyi bir varyant: üçlü ve test neredeyse aynı hataya sahiptir
Piyasalarda daha sık şöyle bir şey olur: iyi bir test, ancak eğitimin bir adımından sonra (şekilde 3. adımdan sonra) yeniden eğitim başlar ve test hatası büyümeye başlar. Resimler sinir ağlarına atıfta bulunuyor, ancak model aşırı eğitildiğinde ormanlar ve güçlendirmelerde de buna benzer bir şey var.
Hangi ölçütlere göre benziyorlar?
Ancak bu, metriklerinizin kötü olduğu anlamına gelmez.
Yani kuantum yapısında süper zekice bir şey yok. Bu iki kuantizasyon yöntemini de kendim için yaptım. Ve her zaman olduğu gibi bir şeyi daha iyi olduğunu düşündüğüm şekilde yaptım. Belki bir hata yapmışımdır. Ve genellikle hesaplamaları niceleme yapmadan, ancak değişken verileri kullanarak yapıyorum.
Elbette farklı yöntemler var, şu anda yaklaşık 900 kuantum tablosu kullanıyorum.
Önemli olan yöntem değil, ikili hedefin ortalama değerinin örnekten daha yüksek olduğu tahminci aralığını seçmektir (şimdi örnek sayısına minimum %5 artı kriter koyuyorum - yine minimum %5), bu da tahmincide yararlı bilgiler olduğunu gösterir. Böyle bir bilgi yoksa, birkaç bölünmede ortaya çıkacağını umabilirsiniz, ancak bunun daha az olası olduğunu düşünüyorum.
Aslında, bu tür 1-2 grafik olduğu, nadiren gerçekten çok sayıda olduğu görülür. Ve burada ya sadece bu grafikleri alabilir ya da en iyi kuantum tablosunu seçerek sadece bu tür grafikleri olan tahmin edicileri alabilirsiniz.
Şahsen, tahmin edicilerin, en azından benimkilerin, yumuşak olasılık geçişlerine sahip olmadığını gördüm, bunun yerine süreksiz olarak gerçekleşiyor ve ters sapmaya dönüşüyor, yani +5 idi ve hemen -5 oldu. Hatta bu olasılıklar sıralanırsa, aralıklar üzerinde eğitildikleri için modelin eğitilmesinin daha kolay olacağını düşünüyorum. Bilgilendirici olmayan alanları hariç tutmanın ve çelişkili olanları ayırmanın mantıklı olmasının nedeni budur.
Tüm tahmin edicileri ikili yaparsanız, yalnızca 2 kuanta olacaktır, biri tüm 0'lara ve diğeri tüm 1'lere sahiptir.
Aslında bir tane olacak - 0,5 :) Ancak, bu şekilde tahmin ediciyi yararlı (potansiyel olarak yararlı bilgiler içeren) aralıklara ayırabilirsiniz.
> Denge grafiklerine ve düşüşlere bakıyorum. Seçimi otomatikleştirmek henüz işe yaramadı. Evet uydurma - en iyi OOS yapıştırma için. Ancak modelin kendisi değil (yani iz değil), modelin en iyi hiperparametrelerinin seçimi.
Anlaşılabilir, ancak kanonik değil - model ölçümlerinin de önemli olduğunu düşünüyorum.
> Tüm bunlar fiyatlar ve mashuplar üzerinden yapılır.
Teoride evet, ve eğer sinir ağları kullanırsanız, ama aslında - hayır - çok karmaşık bağımlılıklar farklı hesaplamalarla aranmalıdır, çünkü bunun için sıradan kullanıcıların hesaplama gücü yoktur.
Eski bir soru üzerine.
> Örnekler burada https://www.mql5.com/ru/articles/3473
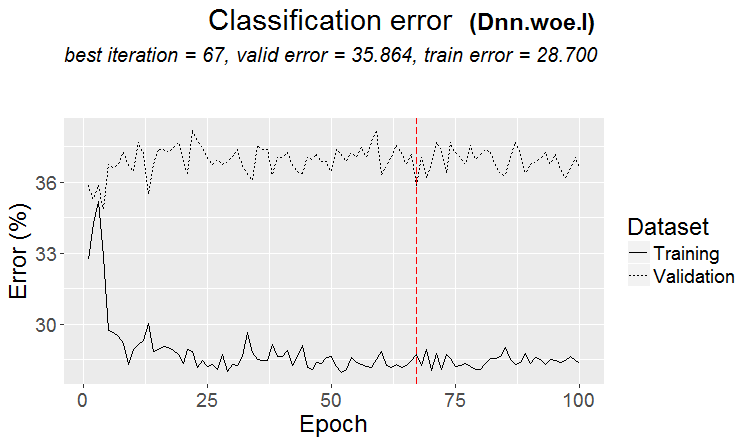
Bir model bulunduğunda iyi bir varyant: üçlü ve test neredeyse aynı hataya sahiptir
Piyasalarda daha sık şöyle bir şey olur: iyi bir test, ancak bir eğitim adımından sonra (şekilde 3.'den sonra) yeniden eğitim başlar ve test hatası artmaya başlar. Resimler sinir ağlarına atıfta bulunuyor, ancak model aşırı eğitildiğinde ormanlar ve güçlendirmelerde de böyle bir şey var.
Düzenlilik her zaman bulunur - prensip budur - soru bu düzenliliğin ortaya çıkmaya devam edip etmeyeceğidir.
Ne tür bir örneğe sahip olduğunuzu bilmiyorum. Testin eğitimden daha hızlı öğrendiği durumlar oldu, ancak daha sıklıkla tam tersi oluyor ve aralarında fark edilebilir bir delta var. İdeal koşullarda bu fark elbette küçük olacaktır.
Örnekler çok benzer olmadığı için modellerin yetersiz eğitildiğini ve herhangi bir gelişme olmadığında eğitimin durduğunu kesin olarak söyleyebilirim.
Bir gün size yeniden eğitilmiş örneğin grafiksel olarak nasıl göründüğünü göstereceğim - köşelerle ayrılmış iki şişkinlik....
Eğitim örneğini yarıya indirin.
Sadece 306 model var, sınava göre ortalama kar -2791 puan.
Ama bu modeli aldım
Bu özellikleri ile
Mat beklentisi kesinlikle düştü, ancak Recall iki kat büyüdü - bu ve çok sayıda anlaşma içeren böyle bir grafik nedeniyle.
Bu tür öngörücüler kullanılmıştır:
Ve örneklemdekinden 9 tane daha az var - sadece onları almaya ve tüm örneklem üzerinde (tüm tren hatlarında) eğitim vermeye çalışacağım.
Bölmeler sadece kuantuma kadar yapılır. Kuantum içindeki her şey aynı değerler olarak kabul edilir ve daha fazla bölünmez. Neden kuantumda bir şey aradığınızı anlamıyorum, ana amacı hesaplamaları hızlandırmaktır (ikincil amaç, modeli yüklemek / genelleştirmektir, böylece daha fazla bölme olmaz, ancak sadece float verilerinin derinliğini sınırlayabilirsiniz) Ben kullanmıyorum, sadece float verileri üzerinde modeller yapıyorum. Nicelleştirmeyi 65000 parça üzerinde yaptım - sonuç kesinlikle nicelleştirmesiz modelle aynı.
Kişisel olarak, tahmin edicilerin, en azından benimkinin, yumuşak olasılık geçişlerine sahip olmadığını, bunun yerine aniden gerçekleştiğini ve ters sapmaya dönüştüğünü gördüm, yani +5 idi ve hemen -5 oldu.
Ayrıca şöyle bir şey de fark ettim. Derinliği 1 arttırmak karlılığı dramatik bir şekilde değiştiriyor, bazen + bazen -.
Aslında, bir tane - 0,5 olacak :) Ancak, bu şekilde tahmin ediciyi yararlı (potansiyel olarak yararlı bilgiler içeren) aralıklara bölmek mümkün olacaktır.
Verileri 2 sektöre bölen 1 bölme olacak - birinde tüm 0'lar, diğerinde tüm 1'ler olacak. Kuanta denilen şeyin ne olduğunu bilmiyorum, sanırım kuanta nicelleştirmeden sonra elde edilen sektör sayısıdır. Belki de sizin kastettiğiniz gibi bölünme sayısıdır.