Bu kaosun bir düzeni var mı? Hadi bulmaya çalışalım! Belirli bir örnek üzerinde makine öğrenimi. - sayfa 18
Alım-satım fırsatlarını kaçırıyorsunuz:
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Kayıt
Giriş yap
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Hesabınız yoksa, lütfen kaydolun
Rastgele sabittir :) Görünüşe göre bu tohum zor bir şekilde hesaplanıyor, yani model oluşturma için izin verilen tüm tahminciler muhtemelen dahil oluyor ve sayılarını değiştirmek seçim sonucunu da değiştiriyor.
Başlangıç tohumu sabittir. Ve sonra HSC'nin her çağrısında yeni bir sayı ortaya çıkar. Bu nedenle farklı tahminci sayılarında ve DST'lerin sayısı, tam tahminci sayısında olduğu gibi aynı tahminciye düşmeyecektir.
Bu neden uyuyor ya da daha doğrusu bunu neye bağlıyorsunuz? Test örnekleminin sınavdan, sınavın eğitimden daha farklı olduğunu düşünme eğilimindeyim, yani tahmin edicilerin farklı olasılık dağılımları var.
Sınavda iyi olacaklarını umarak en iyi sınav varyantlarını alırsınız. Tahmin edicileri en iyi sınava göre seçersiniz. Ama onlar sadece sınav için en iyiler.
"err_" metriği nedir?
err_ oob - OOB'de hata (sınavınız var), err_trn - trende hata. Formüle göre her iki örnek saha için ortak bir hata elde edeceğiz.
Bu arada, tartışmada test ve sınavı değiştirdik. İlk başta test üzerinde ara kontroller ve sınav üzerinde nihai kontroller planladık. Ancak isimler değişmiş olsa da bağlam neyin ne olduğunu açıkça ortaya koyuyor.
Başlangıç numarası sabittir. Ve sonra DST'nin her çağrısında yeni bir sayı ortaya çıkar. Bu nedenle, farklı tahminci sayılarında ve DST sayılarında, tam tahminci sayısında olduğu gibi aynı tahminciye düşmeyecektir.
Hayır, eğitim için kullanılan tahmin ediciler aynı sayıda bırakılırsa varyantlar orada yeniden üretilir.
Sınavda iyi olacaklarını umarak en iyi sınav varyantlarını alırsınız. Tahmin ediciler en iyi sınav tarafından seçilir. Ama onlar sadece sınav için en iyiler.
Öyle oldu ki, bu varyant en dengeli olanıydı - test ve sınavda makul bir karla. Aşağıdaki resimde başlangıçta seçilen model - "Was" ve 10 bin eğitimden sonra en iyi dengeli model - "Became". Genel olarak, sonuç daha iyidir ve daha az tahminci kullanılır, böylece gürültü ortadan kaldırılır. Ve burada soru, eğitimden önce bu gürültünün nasıl önleneceğidir.
Dolayısıyla mantık, eğitimin testte sona erdiği yönündedir, bu nedenle eğitime hiç katılmayan örneğe kıyasla burada pozitif sonuç çıkma olasılığı daha yüksek olmalıdır, bu nedenle ikincisine vurgu yapılmaktadır.
err_ oob - OOB'de hata (sınavınız var), err_trn - trn'de hata. Formüle göre, her iki örnek site için ortak bazı hatalar elde edeceğiz.
Yani, "hata" nasıl sayılıyor bilmiyorum - Doğruluk mu? Ve neden test değil de sınav, çünkü temel yaklaşım sınavında bilemeyeceğiz.
Bu arada, tartışmada test ve sınavı değiştirdik. İlk başta ara testlerin testte ve final testlerinin sınavda olması planlanmıştı. Ancak isimleri değiştirmiş olsalar da bağlam itibariyle neyin ne olduğu açıktır.
Hiçbir şeyi değiştirmedim (belki kendimi bir yerde tarif etmişimdir?) - sadece olduğu gibi - trende - eğitim, test - eğitimi durdurmanın kontrolü ve sınav - herhangi bir eğitime dahil olmayan bölüm.
Ben sadece yaklaşımın etkinliğini, ortalama kar da dahil olmak üzere tüm modellerin ortalamasına göre değerlendiriyorum - iyi sonuç veren kenarlardan daha fazla elde edilmesi muhtemeldir.
Bir de eğitime başlamadan önce bu gürültüden nasıl kaçınılacağı sorusu var.
Görünüşe göre yapamazsınız. Bu, gürültüyü filtrelemek ve doğru verilerden öğrenmek için bir görevdir.
Yani "hata "nın nasıl değerlendirildiğini bilmiyorum - Doğruluk mu?
Bu, bir test ile bir hat üzerinde birleştirilmiş/özetlenmiş bir hata elde etmenin bir yoludur. Her türlü hata toplanabilir. Ve (1-accuracy) ve RMS ve AvgRel ve AvgCE vb.
Hiçbir şeyi değiştirmedim(belki kendimi bir yerde tarif ettim?) - bu böyle - trende - eğitim, test - eğitimi durdurmanın kontrolü ve sınav - herhangi bir eğitime dahil olmayan bölüm.
Resimlerden bana sınav test demek gibi geldi
Örneğin burada.
Ve yukarıdaki tabloda sınav sonuçları testten daha iyi. Bu kesinlikle mümkün, ancak bunun tam tersi olmalı.
Görünüşe göre öyle değil. Gürültüyü kesmek ve doğru verilerden öğrenmek işte bu kadar zor.
Hayır, bir yolu olmalı, aksi takdirde hepsi işe yaramaz/rastgele olur.
Bu, bir test ile bir hat üzerindeki birleştirilmiş/özetlenmiş hatayı elde etmenin bir yoludur. Her türlü hata toplanabilir. Ve (1- doğruluk) ve RMS ve AvgRel ve AvgCE vb.
Anladım, bu benim verilerimde çalışmıyor - en azından bir korelasyon olmalı :)
Resimlerden sınavın test anlamına geldiği anlaşılıyordu
Örneğin burada
Ve yukarıdaki tabloda sınav sonuçları testten daha iyidir.
Evet, sınavın modelciler için daha fazla para kazanma olasılığının daha yüksek olduğu ortaya çıkıyor - durumu kendim tam olarak anlamıyorum.
Ne yazık ki, şimdi bir noktada toplam örneği (satırları) karıştırdığımı fark ettim ve şimdi 2022'den örnekler trende :(.
Her şeyi yeniden yapacağım - sanırım sonucu birkaç hafta içinde alacağım - bakalım genel resim değişecek mi?
Ne yazık ki, şimdi bir noktada toplam örneği (satırları) karıştırdığımı fark ettim ve şimdi tren 2022'den örnekler içeriyor :(
Yeniden yapacağım - sanırım birkaç hafta içinde sonucu alacağım - genel resmin değişip değişmediğine bakın.
Sınav ya da test ile değerlendirilmiş olması fark etmez. Önemli olan, değerlendirme sitesinin ne eğitimde ne de ilk değerlendirmede kullanılmamış olmasıdır.
2 hafta. Dayanıklılığınıza hayran kaldım. Ben de 3 saatlik hesaplamalardan rahatsız oluyorum..... Ve MO'da toplam 5 yıl geçirdim, yaklaşık olarak sizinle aynı.
Kısacası emeklilikte bir şeyler kazanmaya başlayacağız)))) Olabilir.
Ne yazık ki, bir noktada genel örneği (satırları) karıştırdığımı ve şimdi trenin 2022'den örneklerle doldurulduğunu fark ettim :(
Her şeyi 1 sıralı diziye yapıştırdım. Ve sonra doğru miktarı ondan ayırıyorum. Bu şekilde hiçbir şey karışmıyor.
Sınav ya da test ile değerlendirilmiş olması fark etmez. Önemli olan, değerlendirme sitesinin ne eğitimde ne de ilk değerlendirmede kullanılmamış olmasıdır.
Son eğitimi Maxim gibi yapmanın daha iyi olup olmadığını merak ediyorum - kontrol için tarih öncesi bir örnek almak mı, yoksa mevcut tüm örneği alıp en iyi modellerde ortalama olarak olduğu gibi ağaç sayısını sınırlamak mı daha iyi?
2 hafta... Dayanıklılığına hayran kaldım. Ben de 3 saatlik hesaplamaları can sıkıcı buluyorum..... Ve MO'da toplam 5 yıl geçirdim, yaklaşık olarak seninle aynı.
Elbette, her zaman daha hızlı sonuç almak istersiniz. Donanımı, hesaplamalarımın başka şeylerle karışmaması için yüklemeye çalışıyorum - genellikle ana çalışma bilgisayarını kullanmıyorum. Paralel olarak diğer fikirleri kodda uygulayabilirim - fikirleri kodda kontrol etmek için zamanımdan daha hızlı buluyorum.
Kısacası emeklilikte bir şeyler kazanmaya başlayacağız )))) Olabilir.
Katılıyorum - beklenti üzücü. Araştırmamda yavaş da olsa bir ilerleme görmeseydim, muhtemelen şimdiye kadar çalışmayı bitirmiş olurdum.
Her şeyi 1 sıralı diziye yapıştırdım. Ve sonra bu diziden doğru miktarı ayırıyorum. Bu şekilde hiçbir şey karışmıyor.
Evet, örneği ikili bir dosyaya dönüştürdüm ve komut dosyasına yanlışlıkla, görünüşe göre, örneği karıştırmaktan sorumlu bir onay kutusu koydum - bu yüzden bir sorun değil ve CatBoost 3 ayrı örnek gerektiriyor - yerleşik bir çapraz doğrulamaya sahip olmalarına rağmen satır aralığında seçim yapmadılar.
Ayrıca son eğitimi Maxim gibi yapmanın daha iyi olup olmadığını merak ediyorum - kontrol için tarih öncesi bir örnek almak mı, yoksa mevcut tüm örneği alıp en iyi modellerde ortalama olarak olduğu gibi ağaç sayısını sınırlamak mı daha iyi?
Benim için ön eğitim ve testler, ortalama olarak en iyi hiperparametreleri (ağaç sayısı vb.) ve tahmin edicileri seçmek için bir fırsattır. Ve bir test olmadan bile, bunlar üzerinde trende eğitim verebilir ve hemen ticarete geçebilirsiniz.
Tarih öncesi örnekleme fikri, kalıplar değişmezse işe yarayacaktır, belki de öyle. Ancak değişme riski de var. Bu yüzden risk almamayı ve gelecekteki örneklemeler üzerinde test yapmayı tercih ediyorum.
Bir başka soru da bu tarih öncesi örneklemin ne kadar zaman önce yapıldığıdır: altı ay önce mi yoksa 15 yıl önce mi? Altı ay önce işe yarayabilir, ancak 15 yıl önceki piyasa şimdikiyle aynı değil. Ama bu kesin değil. Belki de onlarca yıldır işe yarayan modeller vardır.Burada açıkladığım aynı algoritmayı kullanarak, ancak örneklem karıştırılmadan, yani kronolojik sırada kalarak elde edilen sonuçları açıklayacağım.
Değiştirdiğim tek şey, 10000 modelin eğitiminin artık dışlanan tahmin edicilerin yer aldığı tüm örneklem üzerinde değil, dışlanan tahmin edicilerin bulunduğu sütunların kaldırıldığı yeniden oluşturulmuş bir örneklem üzerinde gerçekleştirilmiş olmasıydı, bu da eğitim sürecini hızlandırdı (görünüşe göre büyük bir dosyayı pompalamak çok zaman alıyor). Bu değişiklikler sayesinde 6 adımlı tahminci taramasını tutarlı bir şekilde gerçekleştirebildim.
Şekil 1: Örneklemin tüm tahmin edicileri üzerinde 100 model eğitildikten sonra örneklem sınavındaki kârın histogramı.
Şekil 2: Seçilen örnek tahmin ediciler üzerinde 10 bin model eğitildikten sonra sınav örneğindeki kâr histogramı - adım 1.
Şekil3. Seçilen örnek tahminciler üzerinde 10 bin model eğitildikten sonra sınav örneğindeki kârın histogramı - adım 2.
Şekil 4: Seçilen örnek tahminciler üzerinde 10 bin model eğitildikten sonra sınav örneği için kar histogramı - adım 3.
Şekil 5: Seçilen örnek tahminciler üzerinde 10 bin model eğitildikten sonra sınav örneği için kar histogramı - adım 4.
Şekil 6: Seçilen örnek tahminciler üzerinde 10 bin model eğitildikten sonra sınav örneği için kar histogramı - adım 5.
Şekil 7: Seçilen örnek tahminciler üzerinde 10 bin model eğitildikten sonra sınav örneği için kar histogramı - adım 6.
Şekil 8. Azalan sayıda öngörücü (özellik) ile sonraki örnekleri oluşturmak için seçilen modellerin özelliklerini içeren tablo.
Öngörücü seçiminin 6. adımında elde edilen aşağıdaki özelliklere sahip modeli ele alalım.
Şekil 9: Model özellikleri.
Şekil 10. Modelin örnek sınav üzerinde sınıflandırma olasılığı üzerinde bir dağılım olarak görselleştirilmesi - x ekseni - modelden elde edilen olasılıklar ve y - tüm örneklerin yüzdesi.
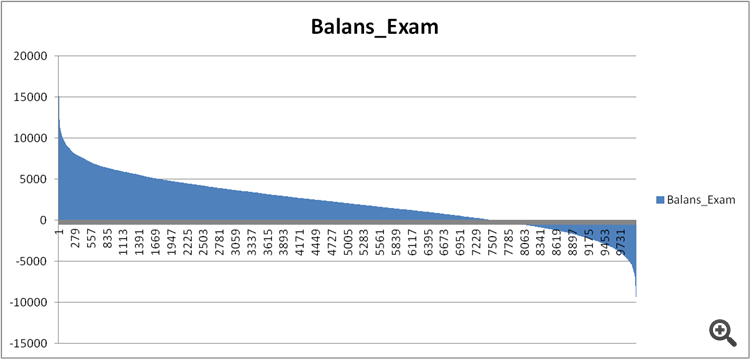
Şekil 11. Modelin sınav örneği üzerindeki dengesi.
Şimdi tahminci seçiminin 6. adımında elde edilen makul derecede iyi ve aşırı kötü modellerdeki tahmincileri karşılaştıralım.
Şekil 12. Modellerin özelliklerinin karşılaştırılması.
Şimdi hangi tahmin edicilerin finansal sonuç üzerinde bu kadar kötü bir etkiye sahip olduğunu ve eğitimi bozduğunu görebilir miyiz?
Şekil 13. İki modeldeki tahmin edicilerin ağırlıklandırılması.
Şekil 13, biri hariç mevcut tahmin edicilerin neredeyse tamamının kullanıldığını göstermektedir, ancak sorunun kaynağının bu olduğundan şüpheliyim. Yani mesele kullanımdan ziyade modelin oluşturulmasındaki kullanım sırası mı?
İki tabloyu karşılaştırdım, bir endeks yerine sıralı bir anlamlılık sayısı atadım ve bu anlamlılığın modellerde ne kadar farklı sıralandığını gördüm.
Şekil 14: İki modeldeki tahmin edicilerin anlamlılığını (kullanımını) karşılaştıran tablo.
Daha iyi görselleştirme için kuyu ve histogram - eksi sapmalar, ikinci (kârsız) modelin tahmin edicisinin daha sonra ve artı - daha önce kullanıldığı anlamına gelir.
Şekil 15. Modellerdeki yordayıcıların anlamlılık sapmaları.
Güçlü sapmalar olduğu görülebilir, belki de durum budur, ancak bunu nasıl bulabilirim / kanıtlayabilirim? Belki de modelleri kıyaslama ölçütü ile karşılaştırmak için karmaşık bir yaklaşıma ihtiyaç vardır - herhangi bir fikriniz var mı?
Genel yanlılığı tanımlamak için, belki de ilk model için tahmin edicilerin önemini dikkate alan - yani azalan katsayılı - bir tür karışıklık endeksi var mı?
Ne gibi sonuçlar çıkarılabilir?
Benim tahminim bu:
1. Geçmiş örneklemde sonuçlar çok daha iyiydi, bunun nedeninin örneklemin kronolojisini karıştırarak gelecekteki olaylar hakkında "sızan" bilgiler olduğunu varsayıyorum. Asıl soru, modellerin karışık bir örneklemle mi yoksa normal bir örneklemle mi daha istikrarlı olacağıdır.
2. Modellerde daha fazla uygulanabilmeleri için tahmin edicilerin öneminin bir yapısını oluşturmak gerekir, yani sayıların yanı sıra mantığı da ortaya koymak gerekir, aksi takdirde modellerin sonuçlarının dağılması az sayıda tahmin edicide bile çok büyük olur.