"Üçüncü Nesil Nöral Ağlar: Derin Ağlar" makalesi için tartışma - sayfa 2
Alım-satım fırsatlarını kaçırıyorsunuz:
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Kayıt
Giriş yap
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Hesabınız yoksa, lütfen kaydolun
Bu benim için bir soru değil. Makale hakkında söyleyeceklerin bu kadar mı?
Makaleye ne olmuş? Tipik bir yeniden yazma. Diğer kaynaklarda da aynı şeyler var, sadece biraz farklı kelimelerle. Resimler bile aynı. Yeni bir şey görmedim, yani yazara ait.
Örnekleri denemek istedim ama bu çok kötü oldu. Bölüm MQL5 için ama örnekler MQL4 için.
vlad1949
Sevgili Vlad!
Arşivlere baktım, oldukça eski R belgelerine sahipsiniz. Ekteki kopyalarla değiştirmek iyi olacaktır.
vlad1949
Sevgili Vlad!
Test cihazında neden çalıştıramadınız?
Her şey sorunsuz çalışıyor. Ancak şema bir gösterge olmadan: Uzman Danışman doğrudan R ile iletişim kurar.
Jeffrey Hinton, derin ağların mucidi: "Derin ağlar yalnızca sinyal-gürültü oranının yüksek olduğu verilere uygulanabilir. Finansal seriler o kadar gürültülü ki derin ağlar uygulanamaz. Denedik ama başarılı olamadık."
YouTube'daki derslerini dinleyin.
Jeffrey Hinton, derin ağların mucidi: "Derin ağlar yalnızca sinyal-gürültü oranının yüksek olduğu verilere uygulanabilir. Finansal seriler o kadar gürültülü ki derin ağlar uygulanamaz. Denedik ama başarılı olamadık."
Youtube'daki derslerini dinleyin.
Paralel başlıktaki gönderinizi göz önünde bulundurarak.
Gürültü, sınıflandırma görevlerinde radyo mühendisliğinden farklı anlaşılır. Bir tahmin edici, hedef değişken için zayıf bir şekilde ilişkiliyse (zayıf tahmin gücüne sahipse) gürültülü olarak kabul edilir. Tamamen farklı bir anlam. Hedef değişkenin farklı sınıfları için tahmin gücüne sahip tahmin ediciler aranmalıdır.
Ben de benzer bir gürültü anlayışına sahibim. Finansal seriler, çoğu bizim tarafımızdan bilinmeyen ve seriye bu "gürültüyü" katan çok sayıda tahmin ediciye bağlıdır. Sadece kamuya açık tahmin edicileri kullanarak, hangi ağları veya yöntemleri kullanırsak kullanalım hedef değişkeni tahmin edemeyiz.
vlad1949
Sevgili Vlad!
Test cihazında neden çalıştıramadınız?
Her şey sorunsuz çalışıyor. Gösterge olmadan doğru şema: danışman doğrudan R ile iletişim kurar.
llllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllll
İyi günler SanSanych.
Yani ana fikir, birkaç gösterge ile çoklu para birimi yapmaktır.
Aksi takdirde, elbette, her şeyi bir Uzman Danışmana paketleyebilirsiniz.
Ancak eğitim, test ve optimizasyon, ticareti kesintiye uğratmadan anında uygulanacaksa, tek Uzman Danışmanlı varyantın uygulanması biraz daha zor olacaktır.
İyi şanslar
PS. Testin sonucu nedir?
Selamlar SanSanych.
Burada İngilizce konuşulan bir forumda bulduğum optimum küme sayısını belirlemeye yönelik bazı örnekler var. Hepsini kendi verilerimde kullanamadım. Çok ilginç 11 paket "clusterSim".
--------------------------------------------------------------------------------------
Bir sonraki yazıda verilerimle hesaplamalar
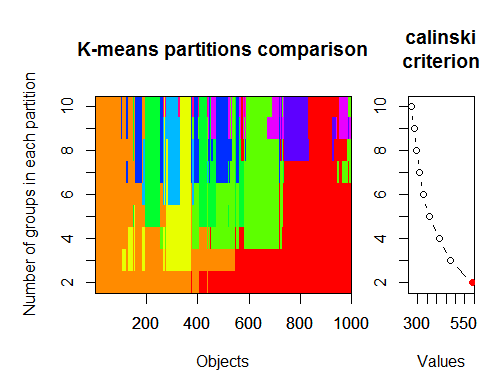
Optimum küme sayısı çeşitli paketlerle ve 30'dan fazla optimallik kriteri kullanılarak belirlenebilir. Gözlemlerime göre en çok kullanılan kriter Calinskykriteridir .
Setimizdeki ham verileri dt göstergesinden alalım . 17 tahminci, hedef y ve mum çubuğu gövdesi z içerir.
"magrittr" ve "dplyr" paketlerinin son sürümlerinde birçok yeni güzel özellik var, bunlardan biri de 'pipe' - %>%. Ara sonuçları kaydetmeniz gerekmediğinde çok kullanışlıdır. Kümeleme için ilk verileri hazırlayalım. Başlangıç matrisi dt'yi alın, ondan son 1000 satırı seçin ve sonra onlardan değişkenlerimizin 17 sütununu seçin. Daha net bir gösterim elde ederiz, başka bir şey değil.
1.
2. Calinsky kriteri: Verilere kaç kümenin uygun olduğunu teşhis etmek için başka bir yaklaşım. Bu durumda
1 ila 10 grup deniyoruz.
3. Parametrelendirilmiş Gauss karışım modelleri için hiyerarşik kümeleme ile başlatılan beklenti maksimizasyonu için Bayesian Bilgi Kriterine göre en uygun modeli ve küme sayısını belirleyin.Gauss karışım modelleri