Разработка трендовых стратегий - помощь в реализации / сотрудничество - страница 4
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Пример использования методов L1-фильтрации тренда в языке MQL5 для вектров float и double на модельных данных броуновского движения.
Основная цель L1-фильтрации тренда (L1 Trend Filtering) заключается в выделении тренда во временном ряде таким образом, чтобы:
В отличие от классических методов сглаживания, этот способ не предполагает гладкость тренда и позволяет получать кусочно-линейную аппроксимацию, что особенно важно при анализе финансовых временных рядов.
Пример использования методов L1-фильтрации тренда в языке MQL5 для double на модельных данных броуновского движения.
Используются значения параметра регуляризации, заданные в единицах λmax. lambda_factors = {1.0,0.8,0.5,0.2,0.1,0.01,0.001};
Скейлинговые свойства λmax
Параметр λmax играет ключевую роль при использовании L1-фильтрации, поскольку он задаёт верхнюю границу регуляризации, при которой решение вырождается в глобальную линейную аппроксимацию. Интересным свойством этой величины является её масштабная зависимость от длины временного ряда.
Численные эксперименты показывают, что λmax растет по степенному закону от числа наблюдений:
где: T — длина временного ряда, α — показатель степени.
Для случайного блуждания (броуновского движения) можно показать, что показатель степени должен быть близок к α≈2.5. Амплитуда отклонений броуновского движения растёт как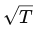 , оператор второй разности масштабируется как
, оператор второй разности масштабируется как 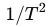 . При вычислении λmax фактически оценивается максимум величины, связанной с интегралом кривизны ряда.
. При вычислении λmax фактически оценивается максимум величины, связанной с интегралом кривизны ряда.
В результате совокупный масштаб приводит к зависимости:
что соответствует показателю степени α ≈ 2.5.
Таким образом, при увеличении длины временного ряда значение λmax растет значительно быстрее линейного роста.
Численный эксперимент для броуновского движения
Для проверки масштабного закона был проведён численный эксперимент.
Для различных длин временного ряда T генерировались реализации броуновского движения, после чего вычислялось среднее значение λmax.
Использовалась логарифмическая аппроксимация:
что позволяет оценить показатель степени α методом линейной регрессии.
Результат:
График (в дважды логарифмическом масштабе) показывает наличие степенной зависимости функции λmax от количества данных для броуновского движения.
Степенная зависимость LambdaMax для броуновского движения
Результаты моделирования показывают:
Таким образом, эксперимент подтверждает теоретическую зависимость:
График в двойном логарифмическом масштабе демонстрирует линейную зависимость между log(λmax) и log(T).
Скейлинг для финансовых временных рядов
Аналогичный эксперимент был проведён для котировок рынка FOREX. Для различных валютных пар и таймфреймов вычислялся показатель степени α.
Результаты показывают, что для реальных финансовых данных значение α также находится в диапазоне α≈2.45–2.60, что очень близко к теоретическому значению для броуновского движения. Это означает, что масштабное поведение λmax практически универсально и сохраняется для различных рынков и таймфреймов.
Скрипт TestScalingLambdaMaxSymbol.mq5 производит расчет показателя степени λmax для заданного символа для стандартных таймфреймов M1-H1.
Результат расчета для EURUSD:
Результаты для EURUSD (стандартные таймфреймы M1-H1) приведены на рис.4.
Степенная зависимость LambdaMax для различных таймфреймов EURUSD
Аналогичным образом можно рассмотреть другие валютные пары.
Для USDJPY:
Результаты для USDJPY также хорошо аппроксимируются степенной зависимостью.
Степенная зависимость LambdaMax для различных таймфреймов USDJPY
Для GBPUSD:
Аналогичная ситуация для котировок GBPUSD:
Степенная зависимость LambdaMax для различных таймфреймов GBPUSD
Для рассмотренных котировок EURUSD, USDJPY и GBPUSD полученные значения показателя степени также близки к 2.5.
Линейные зависимости в log-log масштабе для функции λmax для множества таймфреймов и различных валютных пар свидетельствуют о степенной зависимости λmax от количества данных.
Практическое значение скейлинга
Наличие степенной зависимости λmax имеет важное практическое следствие.
Поскольку λmax∝T^2.5, абсолютное значение параметра λ сильно зависит от:
Поэтому использование абсолютного значения λ неудобно для практических задач.
Гораздо более устойчивым является использование относительного параметра λ=c⋅λmax, где c лежит в диапазоне 0<c<1.
Такой подход:
Именно поэтому удобнее использовать параметр λ в единицах λmax.
Метод L1-фильтрации тренда
Основная идея L1-фильтрации заключается в поиске тренда, который близок к исходным данным, но содержит как можно меньше изменений наклона. В отличие от классических методов сглаживания, которые минимизируют квадрат кривизны, L1-подход минимизирует сумму модулей вторых разностей.
Это приводит к принципиально другому результату:
Таким образом, L1-фильтр не пытается сделать тренд гладким, а ищет минимальное число структурных изменений, объясняющих наблюдаемые данные. Это делает метод особенно удобным для финансовых временных рядов, где динамика часто состоит из последовательности квазилинейных фаз роста и падения.
В методе L1-фильтрации тренд определяется как решение выпуклой задачи оптимизации:
В матричной форме:
где:
Использование L1-нормы приводит к принципиально иному результату: многие вторые разности становятся равными нулю, а значит тренд является кусочно-линейным.
Вторая разность определяется как:
Если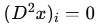 , то точки
, то точки 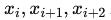 лежат на одной прямой.
лежат на одной прямой.
Следовательно, нулевая вторая разность означает линейный участок тренда, а ненулевая вторая разность соответствует излому. L1-норма способствует разреженности вектора Dx, то есть большинство вторых разностей становятся равными нулю. Это означает, что на соответствующих интервалах тренд является линейным. Точки, где вторые разности ненулевые, интерпретируются как точки излома тренда.
Таким образом, метод L1 Trend Filtering автоматически строит тренд как набор линейных сегментов, соединённых в точках структурных изменений.
Основные свойства L1-фильтрации тренда:
Роль параметра регуляризации λ
Параметр λ управляет балансом между точностью аппроксимации и сложностью тренда:
Зависимость L1-тренда от параметра регуляризации λ
Таким образом, λ контролирует число и расположение изломов тренда.
Геометрическая интерпретация задачи
Искомый тренд x можно рассматривать как точку в n-мерном пространстве. Первый член функционала, отвечающий за точность аппроксимации данных, задаёт евклидовый шар с центром в точке наблюдений y: чем ближе x к y, тем меньше ошибка.
Регуляризующий член с L1-нормой вторых разностей задаёт выпуклое многогранное множество (полиэдр). В отличие от гладких эллипсоидов, возникающих при L2-регуляризации, этот полиэдр имеет острые вершины. Эти вершины соответствуют ситуациям, когда некоторые вторые разности тренда равны нулю.
Именно наличие острых углов у L1-нормы приводит к разреженным решениям: оптимальное решение стремится попасть в вершину полиэдра, где активны лишь некоторые ограничения. Это означает, что большая часть вторых разностей обнуляется, а тренд автоматически принимает кусочно-линейную форму.
Оптимальное решение соответствует первой точке касания евклидового шара и L1-полиэдра. В этой точке тренд состоит из линейных сегментов, соединённых в ограниченном числе точек излома.
Параметр λmax соответствует ситуации, когда евклидовый шар касается L1-полиэдра не в вершине, а вдоль подпространства линейных функций. В этом случае все вторые разности равны нулю, и тренд является строго линейным.
При λ≥λmax ни одно из ограничений L1-нормы не становится активным, поэтому дальнейшее увеличение регуляризации не изменяет решение задачи и тренд остаётся линейным.
Пример L1-разложения изображения при различных lambda, картинка a из архива в #15
Таким образом, при уменьшении параметра регуляризации λ детализация увеличивается (как в примерах с временными рядами в #31 и #32).
Таким образом, метод L1 Trend Filter формирует компактное разреженное описание данных, тот же принцип используется во многих современных методах обработки данных.
и традиционно "лаг в полокна" :-)
"рисует" ? рисует.. даже в gif-ке это видно
и традиционно "лаг в полокна" :-)
"рисует" ? рисует.. даже в gif-ке это видно
1. Вопрос с лагом важный.
При lambda=0 фильтр полностью совпадает с входным сигналом, "лаг" отсутствует полностью и любые SMA с периодом period запаздывают относительно него на величину (period-1)/2.
Для расчета лага между сигналами можно использовать корреляционную функцию, ее максимум покажет сдвиг между сигналами.
Определенные таким образом задержки выглядят так:
Видно, что все эти SMA запаздывают относительно него на величину lag (в примере lambda=0.001*lambda_max).
2. Перерисовка похоже зависит от lambda, а сами отклонения во многом определяются данными. В целом, чем больше lambda, тем меньше изменения, т.к. при lambda>=lambda_max получается одна прямая.
Нужно отметить, в обучении нейросетей используется тот же принцип работы с разреженными данными, т.е. в процессе обучения они как скульптор последовательно формируют структуры данных на основе геомерических контуров.
Определение тренда дадите