Разметка данных для нейросетей. Ваши идеи...
1) Устанавливаем субъективно строгую ожидаемую прибыль: ожидаемый ТП. Допустим, ТП = 200 п.
2) Начинаем уходить в будущее каждый бар и раздвигать Хай и Лоу в переменные макс и мин: если хай выше макс (по-умолчанию равен самой свежей цене закрытия рассматриваемого временного шага) - переписываем макс (макс = хай), и тоже самое с мин. С каждой новой итерацией в будущее на один бар проверяем Хай и Лоу, пока одна из переменных не разрастётся до размеров больше, или равному 200 пунктов. И, в зависимости от того, какая из переменных "дойдёт до финиша", в ту сторону и размечаем сет входных данных: если макс - то BUY, если min - то SELL.
3) Этот шаг и последующий — уже для темы "Что такое обучение", наверное: повторяем пп. 1 и 2, но уже с другой ожидаемой прибылью, столько раз, сколько желаем иметь ансамбль из нейросетей: допустим 3 нейросети, каждая из которых будет обучена на разметках 200 п., 400 п., и 600 п.
4) Соединяем три нейросети и устанавливаем порог (или правило): если три нейросети покажут BUY, то открываем позицию с ТП, который уже будем оптимизировать. Это для общего правила. А теперь для порога: если все три нейросети показывают > N порога (совокупного или каждая нейросеть по отдельности), то открываем позицию.
5) Подгонять разные входные данные под такой подход (эксперименты и опыты).
Немного другой тип обучения: сперва на разметке 600 п., затем ту же самую модель дообучил на разметке 200 п.
Обучаемый период 2012-2021
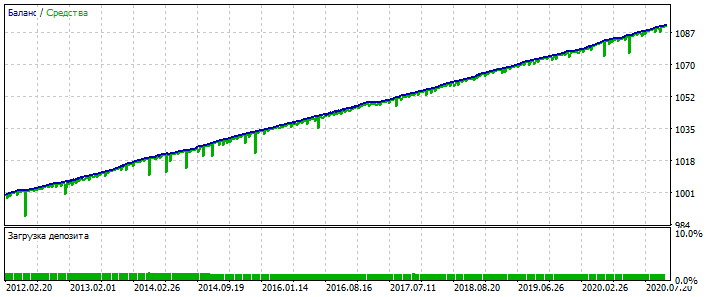
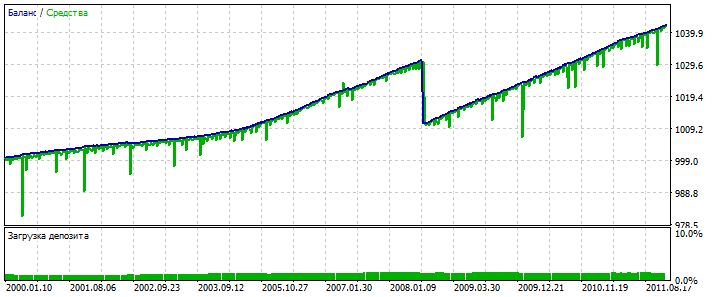
Бектест 2000-2012:
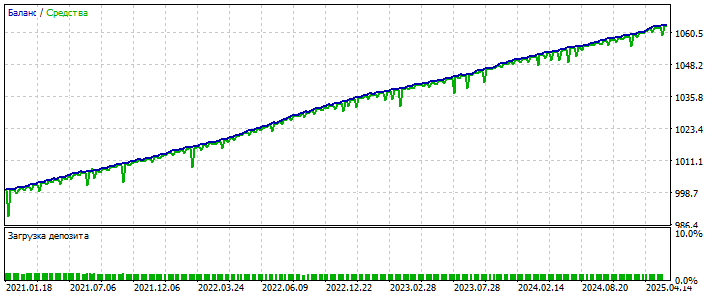
Форвард-тест 2021- по сегодняшний день:
Хороший потенциал для сеток с ИИ — как фильтр обхода нежелательных входов (из категории "повышем безопасность сеток")
Либо для ночного скальпинга: нечто подобно производить уже с другими размерами, с фильтрацией по времени и тд.
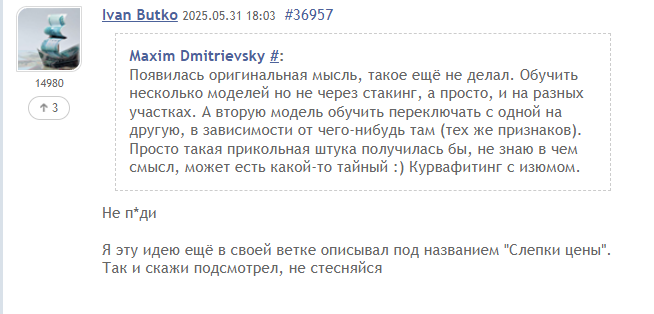
2) Начинаем уходить в будущее каждый бар и раздвигать Хай и Лоу в переменные макс и мин: если хай выше макс (по-умолчанию равен самой свежей цене закрытия рассматриваемого временного шага) - переписываем макс (макс = хай), и тоже самое с мин. С каждой новой итерацией в будущее на один бар проверяем Хай и Лоу, пока одна из переменных не разрастётся до размеров больше, или равному 200 пунктов. И, в зависимости от того, какая из переменных "дойдёт до финиша", в ту сторону и размечаем сет входных данных: если макс - то BUY, если min - то SELL.
Так и делаю много лет, с ТП и СЛ. У вас без СЛ, это эквивалентно огромному СЛ например 20000. Нужно очень много денег на балансе, чтобы секту отрытых не в ту сторону сделок держать с шагом 200. + свопы каждый день платить. Вы какой то кухне хотите 10000-100000 $ доверить? Уверены, что свои хотя бы выведете обратно?
4) Соединяем три нейросети и устанавливаем порог (или правило): если три нейросети покажут BUY, то открываем позицию с ТП
Все будет определять разметка по 600. Думаю эквивалентно одной разметке с ТП=600, СЛ=200.
Так и делаю много лет, с ТП и СЛ. У вас без СЛ эквивалентно огромному СЛ например 20000. Нужно очень много денег на балансе, чтобы секту отрытых не в ту сторону сделок держать с шагом 200. + свопы каждый день платить.
То был пример работы с пересиживателем/сеткой, а по-дефолту - идея как раз оптимизировать TP/SL уже в тестере стратегий,у обученной модели
Модель как бы "слепая" и "глухая", но она "чувствует", грубо говоря, что вот где-то тут или там вероятность того, что сходит "много" - выше. А насколько: около N пунктов. И дальше уже в тестере оптимизируем.
Все будет определять разметка по 600. Думаю эквивалентно одной разметке с ТП=600, СЛ=200.
Мечта. Маленький стоп, огрмный тейк. Самое сложное задание обычно для моделей.
Но, тут важно понимать: обучение структуре цены - это за гранью что-то. Легче обучить простой ТС — возврат к среднему, поскольку котировки чаще флетят. Поэтому нейронки лучше себя показывюат, когда ТП маленький, а СЛ большой.
Имхо, пришло время задуматься над переходом к обучению без учителя.
Вероятностное МО, например.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Что подать на вход нейросети? Ваши идеи...
И успех модели будет зависеть не только от того мусора, который мы ей подадим на вход, но и от того мусора, который мы ей размечаем.
В общем, начало положу почти такое же, как и в ветке входных данных:
— цены закрытия
— разность цен закрытия N свечей подряд
— отношение цены закрытия ко всем OHLC всех N свечей подряд
— всё вышеперечисленное с промежутками N и N*k между свечами
Сейчас же в голову пришла следующая идея:
1) Устанавливаем субъективно строгую ожидаемую прибыль: ожидаемый ТП. Допустим, ТП = 200 п.
2) Начинаем уходить в будущее каждый бар и раздвигать Хай и Лоу в переменные макс и мин: если хай выше макс (по-умолчанию равен самой свежей цене закрытия рассматриваемого временного шага) - переписываем макс (макс = хай), и тоже самое с мин. С каждой новой итерацией в будущее на один бар проверяем Хай и Лоу, пока одна из переменных не разрастётся до размеров больше, или равному 200 пунктов. И, в зависимости от того, какая из переменных "дойдёт до финиша", в ту сторону и размечаем сет входных данных: если макс - то BUY, если min - то SELL.
3) Этот шаг и последующий — уже для темы "Что такое обучение", наверное: повторяем пп. 1 и 2, но уже с другой ожидаемой прибылью, столько раз, сколько желаем иметь ансамбль из нейросетей: допустим 3 нейросети, каждая из которых будет обучена на разметках 200 п., 400 п., и 600 п.
4) Соединяем три нейросети и устанавливаем порог (или правило): если три нейросети покажут BUY, то открываем позицию с ТП, который уже будем оптимизировать. Это для общего правила. А теперь для порога: если все три нейросети показывают > N порога (совокупного или каждая нейросеть по отдельности), то открываем позицию.
5) Подгонять разные входные данные под такой подход (эксперименты и опыты).
Преимущества подхода а части разметки: