Обсуждение статьи "Критерий независимости Гильберта-Шмидта (HSIC)"
Прошу объяснить мой затык. Получается, что HSIC покажет зависимость для любой классической функции Y=F(X1, X2, ...)?
Для любой наверное нет, ведь зависимость может быть очень слабой(из-за сильного шума, например )и тогда он может ее не уловить. А вообще если в данных что-то есть значимое, тест это обнаруживает.
Взял данные другой природы.
// Y - бары символа, X1 - бары перед Y, X2 - бары перед X1. bool Fill( double &X1[], double &X2[], double &Y[], const int Size = 1000, const datetime Time = 0, const string Symb = NULL ) { int Pos = iBarShift(Symb, PERIOD_CURRENT, Time ? Time : TimeCurrent()); return((CopyClose(Symb, PERIOD_CURRENT, Pos, Size, Y) == Size) && (CopyClose(Symb, PERIOD_CURRENT, Pos += Size, Size, X1) == Size) && (CopyClose(Symb, PERIOD_CURRENT, Pos += Size, Size, X2) == Size)); }
В предложенном перестановочном скрипте сделал такую замену.
if (SData == Nonlinear_dependence){ /* double x1 []; MathRandomUniform(-5,5,data_,x1); double x2 []; MathRandomUniform(-5,5,data_,x2); double NormD[]; MathRandomNormal(0,0.1,data_,NormD); double y[]; ArrayResize(y,data_); for (int i=0;i<data_;i++){ y[i] = pow(x1[i],2)*cos(M_PI*x2[i]) + NormD[i]; // Y = X1^2 * cos(pi*X2) + Noise } */ double x1[], x2[], y[]; Fill(x1, x2, y, data_);
Результаты на EURUSD.
Test6 (EURUSD,M1) Коэффициент корреляции (X1, Y) = 0.3757 Test6 (EURUSD,M1) Коэффициент корреляции (X2, Y) = -0.4280 Test6 (EURUSD,M1) ----------------Nonlinear_dependence------------- Test6 (EURUSD,M1) Время выполнения: 12.688 seconds Test6 (EURUSD,M1) ----------------------------------- Test6 (EURUSD,M1) Number observations 1000 Test6 (EURUSD,M1) HSIC: 0.01050641 Test6 (EURUSD,M1) p-value: 0.0000 Test6 (EURUSD,M1) Critical value: 0.0010 Test6 (EURUSD,M1) Отвергаем H0: Наблюдения зависимы
Далее создал на основе рэндомных приращений кастомный символ и запустил на нем.
Test6 (RANDOM_EURUSD,M1) Коэффициент корреляции (X1, Y) = -0.6103 Test6 (RANDOM_EURUSD,M1) Коэффициент корреляции (X2, Y) = -0.4954 Test6 (RANDOM_EURUSD,M1) ----------------Nonlinear_dependence------------- Test6 (RANDOM_EURUSD,M1) Время выполнения: 12.656 seconds Test6 (RANDOM_EURUSD,M1) ----------------------------------- Test6 (RANDOM_EURUSD,M1) Number observations 1000 Test6 (RANDOM_EURUSD,M1) HSIC: 0.00900188 Test6 (RANDOM_EURUSD,M1) p-value: 0.0000 Test6 (RANDOM_EURUSD,M1) Critical value: 0.0009 Test6 (RANDOM_EURUSD,M1) Отвергаем H0: Наблюдения зависимы
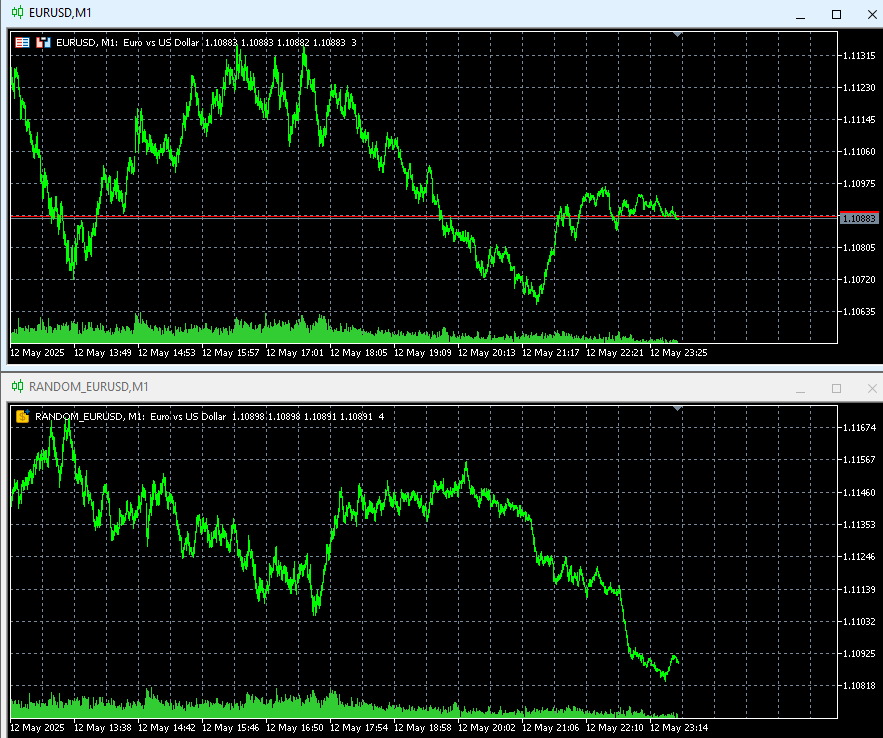
Почему во втором случае зависимость? Грубо говоря, между тремя векторами, которые являются кумулятивными суммами случайной величины, якобы зависимость.
...
Почему во втором случае зависимость? Грубо говоря, между тремя векторами, которые являются кумулятивными суммами случайной величины, якобы зависимость.
Она (зависимость) там точно есть, поскольку используется достаточно простой ГПСЧ (предполагаю, используете штатный, можно проверить на Вихре Мерсенна, к примеру).
Другой вопрос - насколько сильная зависимость, с этим у меня непонятки, прошу автора разъяснить как правильно интерпретировать полученные метрики.
Взял данные другой природы.
В предложенном перестановочном скрипте сделал такую замену.
Результаты на EURUSD.
Далее создал на основе рэндомных приращений кастомный символ и запустил на нем.
Почему во втором случае зависимость? Грубо говоря, между тремя векторами, которые являются кумулятивными суммами случайной величины, якобы зависимость.
Взял данные другой природы.
В предложенном перестановочном скрипте сделал такую замену.
Результаты на EURUSD.
Далее создал на основе рэндомных приращений кастомный символ и запустил на нем.
Почему во втором случае зависимость? Грубо говоря, между тремя векторами, которые являются кумулятивными суммами случайной величины, якобы зависимость.
Она (зависимость) там точно есть, поскольку используется достаточно простой ГПСЧ (предполагаю, используете штатный, можно проверить на Вихре Мерсенна, к примеру).
Другой вопрос - насколько сильная зависимость, с этим у меня непонятки, прошу автора разъяснить как правильно интерпретировать полученные метрики.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Критерий независимости Гильберта-Шмидта (HSIC):
В статье рассматривается непараметрический статистический тест HSIC (Hilbert-Schmidt Independence Criterion) предназначенный для выявления линейных и нелинейных зависимостей в данных. Предложены реализации двух алгоритмов вычисления HSIC на языке MQL5: точного перестановочного теста и гамма-аппроксимации. Эффективность метода демонстрируется на синтетических данных, моделирующих нелинейную связь признаков и целевой переменной.
Основная задача трейдера при работе с котировками финансовых инструментов — создание торговой системы (советника) с положительным математическим ожиданием. При проектировании таких систем часто предполагается, что в данных, используемых для обучения и последующей торговли, присутствуют скрытые зависимости. Однако, вопрос о статистической проверке этого предположения обычно не рассматривается. Считается, что косвенный ответ можно получить через результаты тестирования на вневыборочных данных (out-of-sample).
Между тем, статистически обоснованный ответ на вопрос о наличии связи между признаками и целевой переменной имеет ключевое значение. Положительный ответ дает уверенность в целесообразности использования предсказательных моделей, тогда как отрицательный заставляет задуматься: что именно пытается предсказать алгоритм?
В математической статистике на вопрос о наличии, либо отсутствии, вероятностной связи между случайными величинами отвечают критерии независимости. Одним из таких критериев является статистический тест HSIC — мощный непараметрический метод, разработанный в 2005 году статистиком Артуром Греттоном.
В отличие от коэффициента корреляции, который выявляет только линейные связи, HSIC способен обнаруживать как линейные, так и нелинейные зависимости. Благодаря этому, он широко применяется в машинном обучении для выбора признаков, анализа причинно-следственных отношений и других задач. В этой статье мы разберем принцип работы HSIC и реализуем его в среде MQL5.
Автор: Evgeniy Chernish