ИИ-трейдинг: Показываем код, сомневаемся в результатах или много кода, мало толка? Проверяем "умную" стратегию ИИ.
import logging import os import sys import MetaTrader5 as mt5 import pandas as pd import numpy as np import matplotlib
-
import logging: Импортирует модуль logging для записи событий и отладочной информации.
-
import os: Импортирует модуль os для взаимодействия с операционной системой, например, создания каталогов.
-
import sys: Импортирует модуль sys, который предоставляет доступ к некоторым переменным и функциям, используемым интерпретатором Python.
-
import MetaTrader5 as mt5: Импортирует модуль MetaTrader5 для взаимодействия с платформой MetaTrader 5 (обычно для получения данных о торговле). Переименован в mt5 для краткости.
-
import pandas as pd: Импортирует библиотеку pandas для работы с табличными данными. Переименован в pd для краткости.
-
import numpy as np: Импортирует библиотеку numpy для работы с массивами и математическими операциями. Переименован в np для краткости.
-
import matplotlib: Импортирует модуль matplotlib, основную библиотеку для построения графиков.
# Use a non-interactive backend for matplotlib
matplotlib.use('Agg') -
matplotlib.use('Agg'): Устанавливает неинтерактивный бэкенд Agg для matplotlib. Это позволяет сохранять графики в файлы без необходимости отображения на экране.
import matplotlib.pyplot as plt import time import mplfinance as mpf # For candlestick charts from datetime import datetime from deap import base, creator, tools, algorithms import random import warnings from multiprocessing import cpu_count from functools import partial import gc
-
import matplotlib.pyplot as plt: Импортирует модуль pyplot из matplotlib для создания графиков. Переименован в plt для краткости.
-
import time: Импортирует модуль time для работы со временем.
-
import mplfinance as mpf: Импортирует библиотеку mplfinance для построения графиков свечей (candlestick). Переименован в mpf для краткости.
-
from datetime import datetime: Импортирует класс datetime из модуля datetime для работы с датами и временем.
-
from deap import base, creator, tools, algorithms: Импортирует классы и функции для использования генетических алгоритмов из библиотеки deap.
-
import random: Импортирует модуль random для генерации случайных чисел.
-
import warnings: Импортирует модуль warnings для управления предупреждениями.
-
from multiprocessing import cpu_count: Импортирует функцию cpu_count из модуля multiprocessing для получения количества доступных ядер процессора.
-
from functools import partial: Импортирует функцию partial из модуля functools для создания функций с предопределенными аргументами.
-
import gc: Импортирует модуль gc для сборки мусора.
import xgboost as xgb from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import cross_val_score, train_test_split, StratifiedKFold from sklearn.metrics import ( mean_squared_error, mean_absolute_error, r2_score, mean_absolute_percentage_error, classification_report, roc_auc_score )
-
import xgboost as xgb: Импортирует библиотеку xgboost для градиентного бустинга. Переименован в xgb для краткости.
-
from sklearn.preprocessing import MinMaxScaler: Импортирует класс MinMaxScaler из sklearn для масштабирования признаков.
-
from sklearn.model_selection import cross_val_score, train_test_split, StratifiedKFold: Импортирует функции для кросс-валидации, разделения данных на обучающую и тестовую выборки, а также стратифицированной кросс-валидации из библиотеки sklearn.
-
from sklearn.metrics import ( ... ): Импортирует метрики оценки моделей из sklearn:
-
mean_squared_error: Среднеквадратичная ошибка.
-
mean_absolute_error: Средняя абсолютная ошибка.
-
r2_score: Коэффициент детерминации (R-квадрат).
-
mean_absolute_percentage_error: Средняя абсолютная процентная ошибка.
-
classification_report: Отчёт о классификации.
-
roc_auc_score: ROC AUC score.
-
from ta.volatility import AverageTrueRange, BollingerBands from ta.momentum import RSIIndicator, StochasticOscillator, WilliamsRIndicator, ROCIndicator from ta.trend import MACD, EMAIndicator, CCIIndicator, ADXIndicator, IchimokuIndicator
-
from ta.volatility import ...: Импортирует классы для расчёта индикаторов волатильности из библиотеки ta:
-
AverageTrueRange: Средний истинный диапазон.
-
BollingerBands: Полосы Боллинджера.
-
-
from ta.momentum import ...: Импортирует классы для расчёта индикаторов моментума из библиотеки ta:
-
RSIIndicator: Индикатор относительной силы (RSI).
-
StochasticOscillator: Стохастический осциллятор.
-
WilliamsRIndicator: Индикатор Вильямса %R.
-
ROCIndicator: Индикатор скорости изменения цены (ROC).
-
-
from ta.trend import ...: Импортирует классы для расчёта индикаторов тренда из библиотеки ta:
-
MACD: Схождение-расхождение скользящих средних (MACD).
-
EMAIndicator: Экспоненциальная скользящая средняя (EMA).
-
CCIIndicator: Индекс товарного канала (CCI).
-
ADXIndicator: Индекс среднего направления движения (ADX).
-
IchimokuIndicator: Индикатор Ишимоку.
-
from sklearn.ensemble import StackingRegressor, RandomForestRegressor, GradientBoostingRegressor from sklearn.linear_model import LinearRegression import joblib import seaborn as sns import shap from statsmodels.tsa.stattools import adfuller from tabulate import tabulate
-
from sklearn.ensemble import ...: Импортирует классы для ансамблевых моделей из sklearn:
-
StackingRegressor: Регрессор стекинга.
-
RandomForestRegressor: Регрессор случайного леса.
-
GradientBoostingRegressor: Регрессор градиентного бустинга.
-
-
from sklearn.linear_model import LinearRegression: Импортирует класс LinearRegression для линейной регрессии.
-
import joblib: Импортирует библиотеку joblib для сохранения и загрузки моделей.
-
import seaborn as sns: Импортирует библиотеку seaborn для создания статистических графиков.
-
import shap: Импортирует библиотеку shap для интерпретации результатов машинного обучения.
-
from statsmodels.tsa.stattools import adfuller: Импортирует функцию adfuller из библиотеки statsmodels для теста Дики-Фуллера (теста на стационарность временных рядов).
-
from tabulate import tabulate: Импортирует функцию tabulate из библиотеки tabulate для создания таблиц в текстовом формате.
warnings.filterwarnings('ignore') -
warnings.filterwarnings('ignore'): Отключает отображение предупреждений, что может быть полезно для предотвращения засорения вывода.
# --------------------- Logging Configuration --------------------- class ExcludeInfoFilter(logging.Filter): def filter(self, record): exclude_keywords = ['Classification Report', 'ROC AUC Score'] return not any(keyword in record.getMessage() for keyword in exclude_keywords)
-
class ExcludeInfoFilter(logging.Filter):: Определяется класс ExcludeInfoFilter, который наследуется от logging.Filter.
-
def filter(self, record):: Определяется метод filter внутри класса, который будет фильтровать записи журнала.
-
exclude_keywords = ['Classification Report', 'ROC AUC Score']: Список ключевых слов, по которым будет производиться фильтрация.
-
return not any(keyword in record.getMessage() for keyword in exclude_keywords): Возвращает True, если сообщение журнала не содержит ни одного из ключевых слов, и False в противном случае, эффективно исключая эти записи из журнала.
# Remove existing handlers if any for handler in logging.root.handlers[:]: logging.root.removeHandler(handler)
-
for handler in logging.root.handlers[:]: Итерируется по копии списка обработчиков журнала logging.root, чтобы избежать проблем при изменении списка в процессе итерации.
-
logging.root.removeHandler(handler): Удаляет каждый обработчик журнала из корня, чтобы начать с чистой конфигурации.
# Create logger logger = logging.getLogger() logger.setLevel(logging.DEBUG) # Capture all logs
-
logger = logging.getLogger(): Создает экземпляр объекта логгера.
-
logger.setLevel(logging.DEBUG): Устанавливает уровень журнала на DEBUG, что означает, что все сообщения уровня DEBUG и выше будут записаны.
# Create FileHandler
file_handler = logging.FileHandler("strategy_optimization.log")
file_handler.setLevel(logging.DEBUG)
file_handler.setFormatter(logging.Formatter('%(asctime)s [%(levelname)s] %(message)s')) -
file_handler = logging.FileHandler("strategy_optimization.log"): Создает обработчик журнала FileHandler, который будет записывать сообщения в файл strategy_optimization.log.
-
file_handler.setLevel(logging.DEBUG): Устанавливает уровень обработчика файла на DEBUG, что соответствует уровню логгера.
-
file_handler.setFormatter(logging.Formatter('%(asctime)s [%(levelname)s] %(message)s')): Устанавливает формат сообщений журнала, который включает:
-
%(asctime)s: Время создания записи.
-
%(levelname)s: Уровень сообщения (DEBUG, INFO, WARNING, ERROR, CRITICAL).
-
%(message)s: Само сообщение.
-
# Create StreamHandler
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(logging.INFO)
stream_handler.setFormatter(logging.Formatter('%(asctime)s [%(levelname)s] %(message)s'))
stream_handler.addFilter(ExcludeInfoFilter()) -
stream_handler = logging.StreamHandler(sys.stdout): Создает обработчик журнала StreamHandler, который будет выводить сообщения в стандартный вывод (консоль).
-
stream_handler.setLevel(logging.INFO): Устанавливает уровень обработчика консоли на INFO, что означает, что только сообщения уровня INFO и выше будут выведены в консоль.
-
stream_handler.setFormatter(logging.Formatter('%(asctime)s [%(levelname)s] %(message)s')): Устанавливает формат сообщений журнала для консоли.
-
stream_handler.addFilter(ExcludeInfoFilter()): Добавляет фильтр ExcludeInfoFilter к обработчику консоли, чтобы не выводить сообщения, содержащие 'Classification Report' и 'ROC AUC Score' в консоль.
logger.addHandler(file_handler) logger.addHandler(stream_handler)
-
logger.addHandler(file_handler): Добавляет file_handler к логгеру.
-
logger.addHandler(stream_handler): Добавляет stream_handler к логгеру.
# --------------------- Parameters and Global Variables --------------------- start_date = datetime(2015, 1, 1) end_date = datetime.today() split_date = datetime(2021, 1, 1) backtest_start_date = datetime(2022, 1, 1) backtest_end_date = datetime.today()
-
start_date = datetime(2015, 1, 1): Устанавливает начальную дату для загрузки данных.
-
end_date = datetime.today(): Устанавливает конечную дату для загрузки данных (сегодняшний день).
-
split_date = datetime(2021, 1, 1): Устанавливает дату разделения данных на обучающую и тестовую выборки.
-
backtest_start_date = datetime(2022, 1, 1): Устанавливает начальную дату для бэктестинга.
-
backtest_end_date = datetime.today(): Устанавливает конечную дату для бэктестинга.
transaction_cost = 0.0002 slippage = 0.0001 risk_free_rate = 0.02 / 252 time_steps = 30
-
transaction_cost = 0.0002: Устанавливает стоимость транзакции (комиссия) как 0.02%.
-
slippage = 0.0001: Устанавливает проскальзывание как 0.01%.
-
risk_free_rate = 0.02 / 252: Устанавливает годовую безрисковую ставку как 0.02, разделённую на 252 (количество торговых дней в году).
-
time_steps = 30: Задает количество временных шагов (вероятно, используется для какого-то расчета).
timeframes_to_process = [ mt5.TIMEFRAME_D1, ]
-
timeframes_to_process = [mt5.TIMEFRAME_D1]: Список таймфреймов для обработки. Здесь указан только дневной таймфрейм mt5.TIMEFRAME_D1.
show_plots = True my_directory = '1BBa' plot_base_dir = "plots" current_date = datetime.today().strftime('%Y-%m-%d') num_cores_to_use = 6 currency_pairs = ["AUDUSD"]
-
show_plots = True: Флаг, указывающий на необходимость отображения графиков.
-
my_directory = '1BBa': Имя каталога, который будет использоваться для сохранения результатов.
-
plot_base_dir = "plots": Базовый каталог для сохранения графиков.
-
current_date = datetime.today().strftime('%Y-%m-%d'): Текущая дата в формате YYYY-MM-DD для создания подкаталогов.
-
num_cores_to_use = 6: Количество ядер процессора, которые будут использоваться для параллельных вычислений.
-
currency_pairs = ["AUDUSD"]: Список валютных пар, которые будут анализироваться. Здесь только пара AUDUSD.
timeframes_dict = {
mt5.TIMEFRAME_M1: "M1",
mt5.TIMEFRAME_M2: "M2",
mt5.TIMEFRAME_M3: "M3",
mt5.TIMEFRAME_M4: "M4",
mt5.TIMEFRAME_M5: "M5",
mt5.TIMEFRAME_M6: "M6",
mt5.TIMEFRAME_M10: "M10",
mt5.TIMEFRAME_M12: "M12",
mt5.TIMEFRAME_M15: "M15",
mt5.TIMEFRAME_M20: "M20",
mt5.TIMEFRAME_M30: "M30",
mt5.TIMEFRAME_H1: "H1",
mt5.TIMEFRAME_H2: "H2",
mt5.TIMEFRAME_H3: "H3",
mt5.TIMEFRAME_H4: "H4",
mt5.TIMEFRAME_H6: "H6",
mt5.TIMEFRAME_H8: "H8",
mt5.TIMEFRAME_H12: "H12",
mt5.TIMEFRAME_D1: "D1",
mt5.TIMEFRAME_W1: "W1",
mt5.TIMEFRAME_MN1: "MN1",
} -
timeframes_dict = { ... }: Словарь, сопоставляющий константы таймфреймов из MetaTrader5 с их строковыми представлениями.
ga_base_seed = 41 ga_pop_size = 150 ga_num_generations = 10 ga_cxpb = 0.7 ga_mutpb = 0.2 ga_mutate_indpb = 0.3 ga_mate_indpb = 0.9
-
ga_base_seed = 41: Базовое случайное зерно для генетического алгоритма.
-
ga_pop_size = 150: Размер популяции для генетического алгоритма.
-
ga_num_generations = 10: Количество поколений для генетического алгоритма.
-
ga_cxpb = 0.7: Вероятность скрещивания (кроссовера) для генетического алгоритма.
-
ga_mutpb = 0.2: Вероятность мутации для генетического алгоритма.
-
ga_mutate_indpb = 0.3: Вероятность мутации одного гена в особи для генетического алгоритма.
-
ga_mate_indpb = 0.9: Вероятность обмена генами во время скрещивания для генетического алгоритма.
xgb_n_estimators = 200 xgb_max_depth = 20 xgb_learning_rate = 0.1 xgb_random_state = ga_base_seed
-
xgb_n_estimators = 200: Количество деревьев в XGBoost.
-
xgb_max_depth = 20: Максимальная глубина дерева в XGBoost.
-
xgb_learning_rate = 0.1: Скорость обучения для XGBoost.
-
xgb_random_state = ga_base_seed: Случайное зерно для XGBoost.
# Initialize DEAP framework creator.create('FitnessMax', base.Fitness, weights=(1.0,)) creator.create('Individual', list, fitness=creator.FitnessMax)
-
creator.create('FitnessMax', base.Fitness, weights=(1.0,)): Создает класс FitnessMax для представления фитнеса (максимизация) с весом 1.0, используя функционал deap.
-
creator.create('Individual', list, fitness=creator.FitnessMax): Создает класс Individual, который является списком, с ассоциированным фитнесом типа FitnessMax, используя функционал deap.
sl_features = [ 'RSI', 'MACD', 'ATR', 'BB_High', 'BB_Low', 'EMA_14', 'SMA_14', 'DayOfWeek', 'WeekOfYear', 'Month', 'ROC_14', 'Momentum_14', 'WilliamsR', 'Ichimoku_A', 'Ichimoku_B', 'Corr_Close_RSI_14', 'Return_Lag_1', 'Return_Lag_2', 'Return_Lag_3', 'RSI_MACD', 'ATR_Close', 'Close_Stationary', 'High_Stationary', 'Low_Stationary' ]
-
sl_features = [ ... ]: Список фичей, используемых в модели прогнозирования Stop Loss (SL).
window_values_ga = np.arange(20, 252, 1) multiplier_values_ga = np.arange(0.8, 3.0, 0.1) tp_factor_values_ga = np.arange(1.2, 5.61, 0.05) sl_factor_values_ga = np.arange(0.1, 1.21, 0.05) sl_max_depth_values = [3, 5, 7] sl_learning_rate_values = [0.01, 0.05, 0.1] sl_n_estimators_values = [100, 200, 300]
-
window_values_ga = np.arange(20, 252, 1): Диапазон значений для окна (window) генетического алгоритма, созданный с помощью numpy.arange.
-
multiplier_values_ga = np.arange(0.8, 3.0, 0.1): Диапазон значений для мультипликатора генетического алгоритма.
-
tp_factor_values_ga = np.arange(1.2, 5.61, 0.05): Диапазон значений для фактора тейк-профита (take-profit) генетического алгоритма.
-
sl_factor_values_ga = np.arange(0.1, 1.21, 0.05): Диапазон значений для фактора стоп-лосса (stop-loss) генетического алгоритма.
-
sl_max_depth_values = [3, 5, 7]: Список возможных значений для максимальной глубины дерева в модели stop-loss.
-
sl_learning_rate_values = [0.01, 0.05, 0.1]: Список возможных значений для скорости обучения в модели stop-loss.
-
sl_n_estimators_values = [100, 200, 300]: Список возможных значений для количества деревьев в модели stop-loss.
window_values_ga_list = window_values_ga.tolist() multiplier_values_ga_list = multiplier_values_ga.tolist() tp_factor_values_ga_list = tp_factor_values_ga.tolist() sl_factor_values_ga_list = sl_factor_values_ga.tolist() sl_max_depth_list = sl_max_depth_values sl_learning_rate_list = sl_learning_rate_values sl_n_estimators_list = sl_n_estimators_values
-
Преобразует numpy массивы в списки для удобства использования в генетическом алгоритме.
scaler_X_selected_dict = {}
pip_scale_factor = 100000 -
scaler_X_selected_dict = {}: Словарь для хранения Scaler'ов, используемых для масштабирования данных.
-
pip_scale_factor = 100000: Масштабирующий коэффициент для пипсов, значение по умолчанию 100000.
# --------------------- Helper Functions --------------------- def get_conversion_rate(from_cur, to_cur): direct_symbol = to_cur + from_cur reverse_symbol = from_cur + to_cur symbol_info_direct = mt5.symbol_info(direct_symbol) if symbol_info_direct is not None: mt5.symbol_select(direct_symbol, True) tick = mt5.symbol_info_tick(direct_symbol) if tick is not None: if direct_symbol.startswith(to_cur): rate = 1.0 / tick.ask return rate else: return tick.ask symbol_info_reverse = mt5.symbol_info(reverse_symbol) if symbol_info_reverse is not None: mt5.symbol_select(reverse_symbol, True) tick = mt5.symbol_info_tick(reverse_symbol) if tick is not None: if reverse_symbol.startswith(to_cur): rate = 1.0 / tick.ask return rate else: return tick.ask return None
-
def get_conversion_rate(from_cur, to_cur):: Определяет функцию для получения обменного курса между двумя валютами.
-
direct_symbol = to_cur + from_cur: Строит прямое название символа (например, EURUSD).
-
reverse_symbol = from_cur + to_cur: Строит обратное название символа (например, USDEUR).
-
symbol_info_direct = mt5.symbol_info(direct_symbol): Получает информацию о символе из MetaTrader 5 для прямого символа.
-
Далее следует блок if для проверки, что информация получена, символ выбран и получена цена тика. Если да, то функция возвращает соответствующий курс.
-
Аналогичный блок if для обратного символа.
-
return None: Если курс не найден, функция возвращает None.
def apply_transformations(series): transformations = {} transformations['first_diff'] = series.diff().fillna(0) transformations['pct_change'] = series.pct_change().fillna(0) transformations['log'] = np.log(series.replace(0, np.nan)).fillna(0) return transformations
-
def apply_transformations(series):: Определяет функцию для применения различных преобразований к временному ряду.
-
transformations = {}: Инициализирует пустой словарь для хранения преобразованных рядов.
-
transformations['first_diff'] = series.diff().fillna(0): Вычисляет первую разность ряда и заполняет NaN значения нулями.
-
transformations['pct_change'] = series.pct_change().fillna(0): Вычисляет процентное изменение ряда и заполняет NaN значения нулями.
-
transformations['log'] = np.log(series.replace(0, np.nan)).fillna(0): Вычисляет логарифм ряда (с заменой 0 на NaN, чтобы избежать ошибки, и заполняет NaN значения нулями).
-
return transformations: Возвращает словарь с преобразованными рядами.
def replace_inf_nan(series): series = series.replace([np.inf, -np.inf], np.nan) series = series.fillna(method='ffill').fillna(method='bfill') return series
-
def replace_inf_nan(series):: Определяет функцию для замены бесконечностей и NaN значений в ряде.
-
series = series.replace([np.inf, -np.inf], np.nan): Заменяет бесконечности на NaN.
-
series = series.fillna(method='ffill').fillna(method='bfill'): Заполняет NaN значения методом ffill (заполнение последним валидным значением) и затем bfill (заполнение следующим валидным значением).
-
return series: Возвращает обработанный ряд.
def select_best_transformation(series, transformations): adf_results = {} for name, transformed_series in transformations.items(): transformed_series_clean = transformed_series.dropna() if len(transformed_series_clean) < 10: adf_results[name] = 1.0 continue result = adfuller(transformed_series_clean, autolag='AIC') adf_results[name] = result[1] stationary_transforms = {k: v for k, v in adf_results.items() if v < 0.05} if not stationary_transforms: logging.warning("No stationary transformation found. Using first_diff as default.") best_transform = 'first_diff' else: best_transform = min(stationary_transforms, key=stationary_transforms.get) best_series = transformations[best_transform] return best_transform, best_series
-
def select_best_transformation(series, transformations):: Определяет функцию для выбора лучшего преобразования, которое приводит временной ряд к стационарному.
-
adf_results = {}: Создаёт пустой словарь для хранения результатов теста Дики-Фуллера.
-
for name, transformed_series in transformations.items():: Итерируется по всем преобразованиям.
-
transformed_series_clean = transformed_series.dropna(): Очищает преобразованный ряд от NaN значений.
-
if len(transformed_series_clean) < 10:: Если длина ряда меньше 10, то результат adf записывается в словарь как 1.0, переходим к следующему преобразованию.
-
result = adfuller(transformed_series_clean, autolag='AIC'): Выполняет тест Дики-Фуллера на стационарность, используя параметр autolag='AIC' для автоматического выбора лага.
-
adf_results[name] = result[1]: Записывает p-value из результатов теста в словарь.
-
stationary_transforms = {k: v for k, v in adf_results.items() if v < 0.05}: Создаёт словарь только стационарных преобразований, где p-value меньше 0.05.
-
if not stationary_transforms:: Если нет стационарных преобразований, то выбирается первая разность first_diff как значение по умолчанию.
-
else: best_transform = min(stationary_transforms, key=stationary_transforms.get): В противном случае выбирается преобразование с минимальным p-value.
-
best_series = transformations[best_transform]: Получает преобразованный ряд.
-
return best_transform, best_series: Возвращает название лучшего преобразования и сам ряд.
Вы написали бы ещё рекомендуемые требования к компу для работы с Вашим кодом. Например, у меня двухядерный ноут. Я установил оболочку для Питона, импортировал в программу пару десятков строк из csv-файла и дал комманду на отрисовку файермэпа. Питон отрисовал. Но увидев, насколько долго шёл процесс, я понял, что для Пайтона нужно железо посерьёзнее моего. Пришлось отложить Пайтон в долгий ящик. Думаю, что не каждый желающий имеет железо для нормальной работы с Вашим кодом.
CPU: 12th Gen Intel(R) Core(TM) i7-12700H
Memory: ~32GB
Это обычный старый ноутбук Dell G15 5520. Компьютер работает в теплых помещениях, со сбалансированным энергопотреблением. Один тест кода для данных D1 с 2015 по 21.12.2024. заняло время с 17:31:25 до 17:42:13. Да, это не быстро, но и не очень долго. Я думаю, что на более новых и стационарных компьютерах все происходит достаточно быстро.
C:\Users\user\PycharmProjects\pythonProject1_AI\.venv\Scripts\python.exe C:\Users\user\PycharmProjects\pythonProject1_AI\121_5_forex.py Starting main function... MT5 initialized successfully. 2024-12-21 17:31:25,472 [INFO] Using 20 cores for multiprocessing. 2024-12-21 17:31:25,473 [INFO] Processing timeframe: D1 2024-12-21 17:31:25,473 [INFO] Loading and processing data for pair: AUDUSD 2024-12-21 17:31:25,473 [INFO] Loading data for AUDUSD from MT5... 2024-12-21 17:31:25,475 [INFO] Optimizing strategy for pair: AUDUSD 2024-12-21 17:32:12,201 [INFO] Using AUDUSD digits = 5. Point: 0.00001 2024-12-21 17:32:12,201 [INFO] Conversion rate from AUD to EUR: 0.5993658709085787 2024-12-21 17:32:12,205 [INFO] Using AUDUSD digits = 5. Point: 0.00001 2024-12-21 17:32:12,205 [INFO] Conversion rate from AUD to EUR: 0.5993658709085787 2024-12-21 17:32:12,620 [INFO] Initial Population Size: 150 2024-12-21 17:32:12,620 [INFO] Starting genetic algorithm optimization for Ensemble Predictions Close - GA Optimization... 2024-12-21 17:32:30,781 [INFO] Ensemble Predictions Close - GA Optimization - Generation 0: Max nan, Avg nan 2024-12-21 17:32:30,781 [INFO] Generation 0: No improvement. Patience remaining: 9 2024-12-21 17:32:47,229 [INFO] Ensemble Predictions Close - GA Optimization - Generation 1: Max 0.11610534798557089, Avg 0.06286744598243656 2024-12-21 17:32:47,229 [INFO] Generation 1: Improvement found. Resetting patience. ... 2024-12-21 17:42:10,740 [INFO] Ensemble Predictions Close - GA Optimization - Generation 29: Max nan, Avg nan 2024-12-21 17:42:10,740 [INFO] Generation 29: No improvement. Patience remaining: 3 2024-12-21 17:42:10,740 [INFO] Final Population Size: 150 2024-12-21 17:42:10,741 [INFO] Best GA Individual: [24.0, 1.5999999999999999, 2.8500000000000014, 0.9500000000000003, 3.0, 0.05, 300.0] 2024-12-21 17:42:10,893 [INFO] Best GA Individual Strategy Evaluation Complete. 2024-12-21 17:42:13,815 [INFO] Ensemble Model Performance for AUDUSD (D1): 2024-12-21 17:42:13,815 [INFO] MSE: 0.0000 2024-12-21 17:42:13,815 [INFO] MAE: 0.0038 2024-12-21 17:42:13,815 [INFO] R² Score: 0.9661 2024-12-21 17:42:13,815 [INFO] MAPE: 0.0057 2024-12-21 17:42:13,963 [INFO] MT5 shutdown successfully. MT5 shutdown successfully. Process finished with exit code 0
CPU: 12th Gen Intel(R) Core(TM) i7-12700H
Memory: ~32GB
Это обычный старый ноутбук Dell G15 5520. Компьютер работает в теплых помещениях, со сбалансированным энергопотреблением. Один тест кода для данных D1 с 2015 по 21.12.2024. заняло время с 17:31:25 до 17:42:13. Да, это не быстро, но и не очень долго. Я думаю, что на более новых и стационарных компьютерах все происходит достаточно быстро.
Ну вот открытая статистика пользователей.
https://cloud.mql5.com/ru/stats


- cloud.mql5.com
12th Gen Intel(R) Core(TM) i7-12700H - 14 ядер и 20 потоков, базовая частота – 2300 МГц . + 32 гига оперативы. Ещё и хард SSD - я о таком могу только мечтать. И Вы говорите, что комп у Вас старенький?
У меня Intel(R) Core(TM) i3 CPU M 330 @ 2.13GHz 2.13 GHz - Два ядра! Оператива = 4 гига. Хард имеет вращающийся диск.
12th Gen Intel(R) Core(TM) i7-12700H - 14 ядер и 20 потоков, базовая частота – 2300 МГц . + 32 гига оперативы. Ещё и хард SSD - я о таком могу только мечтать. И Вы говорите, что комп у Вас старенький?
У меня Intel(R) Core(TM) i3 CPU M 330 @ 2.13GHz 2.13 GHz - Два ядра! Оператива = 4 гига. Хард имеет вращающийся диск.
Ноутбук старый, больше двух лет. Но, конечно, все зависит от того, какие возможности есть у каждого читателя форума.
Могу предложить исправления в коде, которые позволят сократить время работы генетического алгоритма, а значит и время использования ресурсов ПК.
В этом коде:
window_values_ga = np.arange(20, 252, 1) multiplier_values_ga = np.arange(0.8, 3.0, 0.1) tp_factor_values_ga = np.arange(1.2, 5.61, 0.05) sl_factor_values_ga = np.arange(0.1, 1.21, 0.05)
внести изменения - уменьшить диапазон и шаг, например
window_values_ga = np.arange(20, 100, 1) multiplier_values_ga = np.arange(0.8, 2.0, 0.1) tp_factor_values_ga = np.arange(1.2, 4.00, 0.1) sl_factor_values_ga = np.arange(0.1, 1.21, 0.1)
Если вы используете таймфрейм D1, эти параметры в большей степени будут соответствовать ожидаемому результату.
А вот для меньших таймфреймов нужно увеличить значения окна и множителя, например:
window_values_ga = np.arange(50, 300, 1) multiplier_values_ga = np.arange(1.5, 5.0, 0.1) tp_factor_values_ga = np.arange(1.2, 4.00, 0.1) sl_factor_values_ga = np.arange(0.1, 1.21, 0.1)
но это будет очень ресурсоемко.
В любом случае вы всегда можете увеличить шаг (0.15; 0.2; 0.25; ...), что соответственно ускорит процесс.
+ + +
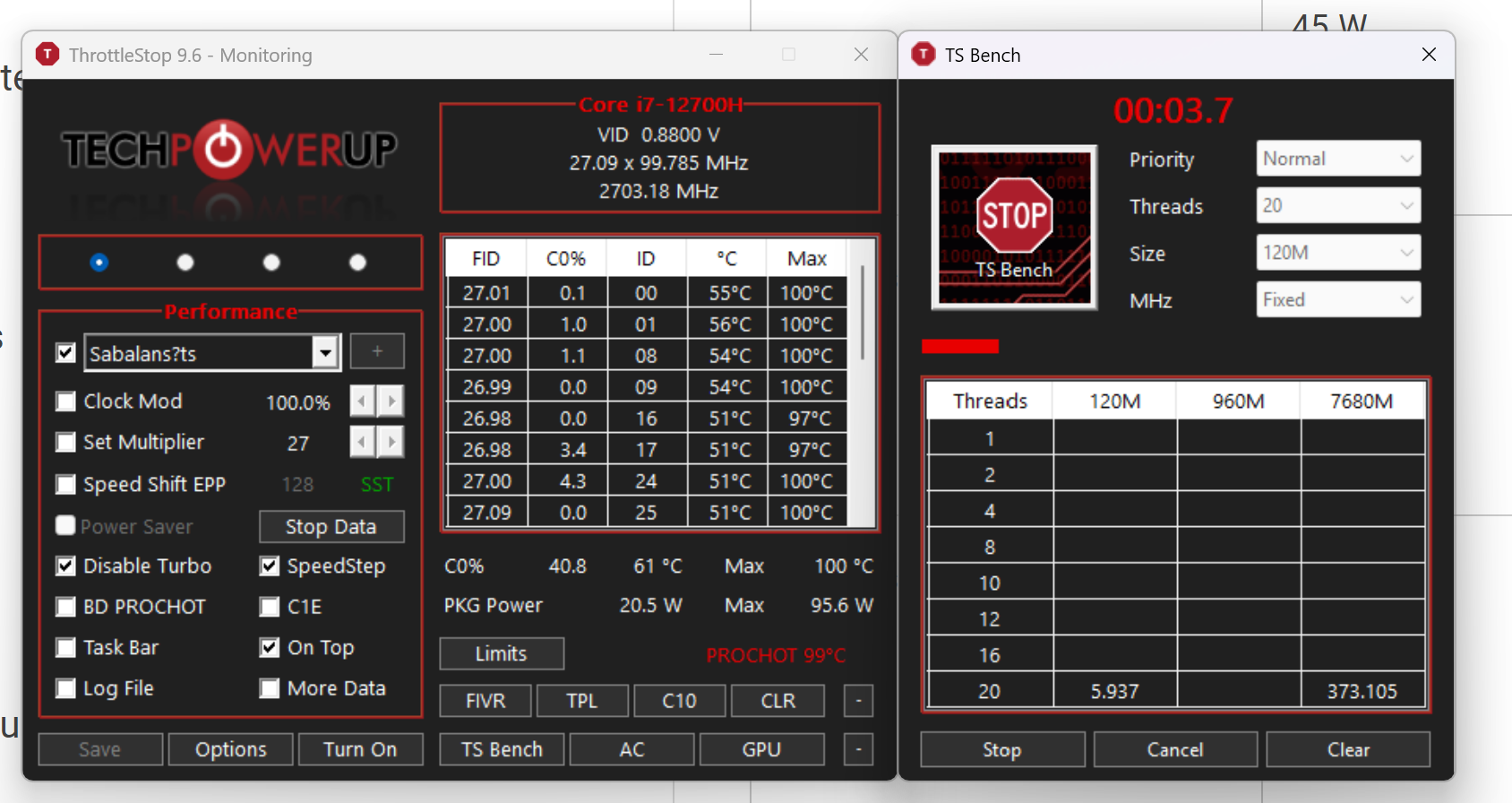
«базовая частота – 2300 МГц». Это неправда, хоть Интел и пишет, что базовый множитель равен 23, но на самом деле базовый множитель для этих процессоров равен 27. Если отредактировать «UEFI», то можно повысить как базовый множитель, так и увеличить потребляемую мощность в ваттах при сохранении тактовой частоты, без сильного троттлинга.
Как вы можете видеть на прикрепленном изображении, этот процессор работал с множителем 27 с выключенным турбо.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Код и его логика полностью написаны ИИ, описание кода и комментарии к коду также генерируются ИИ.
Приглашаю желающих включиться в обсуждение этой игрушки (кода) и, если есть возможности, улучшить ее, чтобы код не был просто игрушкой с переоптимизированными результатами.
Код выполняется в среде Python, но не пригоден для использования в MQL MetaEditor. Для запуска кода требуется Python IDE.
Общее назначение кода:
Данный код представляет собой сложную систему для оптимизации и бэктестирования торговой стратегии на финансовых рынках, используя данные, полученные из платформы MetaTrader 5 (MT5). Он включает в себя загрузку исторических данных, вычисление технических индикаторов, построение моделей машинного обучения для прогнозирования цен, реализацию торговой стратегии на основе полос Боллинджера и использование генетического алгоритма для оптимизации параметров стратегии, а также модели stop-loss. Код также генерирует различные графики и отчёты для анализа производительности стратегии.
Основные компоненты и их функциональность:
Логика работы кода:
Особенности: