Что подать на вход нейросети? Ваши идеи... - страница 31
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
В качестве подтверждения - мои графики выше. Один вход, два входа, три входа - один нейрон, два нейрона, три нейрона. Всё, дальше - переобучение - запоминание пути, а не работа на новых данных.
Аналогично с деревянными моделями. С 3-5 (может до 10, но скорее до 5) входами/фичами модель еще может на форварде показать прибыль, если больше, то уже рандом или слив. Т.е. переобучение.
Эти 3-5 лучших фич получал полным перебором пар, троек и т.д. и обучением на них моделей и выбором лучших по валкинг-форварду.
И вот представьте, обычная нейросеть берёт каждое число, каждый признак - и тупо суммирует, дополнительно помножив на вес, в одну кучу мусора, называемую сумматором.
Деревья тоже используют среднее значение листьев.Если лес - то усредняет с др. деревьями, если буст, то суммирует с уточняющими деревьями.
Т.е. что с нейросетями, что с деревянными моделями одинаковая ситуация. Все усредняют. Когда много шума, то нормально обучиться можно только на 3-5 фичах. Усредняться с шумом - это переобучение на шум.
П.С. Вместо 20+летней NeuroPro можно что-то поновее использовать. R, Питон, или если сложно разбираться с ними, то используйте EXE Катбуста, как тут https://www.mql5.com/ru/articles/8657 Можно автоматически запускать EXE прямо из советника, т.е. полностью автоматизировать процесс. Пример https://www.mql5.com/ru/forum/86386/page3282#comment_49771059
П.П.С Ночью лучше спать. Здоровье не купишь, даже если миллионы на этих сетях заработаете.
Аналогично с деревянными моделями. С 3-5 (может до 10, но скорее до 5) входами/фичами модель еще может на форварде показать прибыль, если больше, то уже рандом или слив. Т.е. переобучение.
Эти 3-5 лучших фич получал полным перебором пар, троек и т.д. и обучением на них моделей и выбором лучших по валкинг-форварду.
Деревья тоже используют среднее значение листьев.Если лес - то усредняет с др. деревьями, если буст, то суммирует с уточняющими деревьями.
Т.е. что с нейросетями, что с деревянными моделями одинаковая ситуация. Все усредняют. Когда много шума, то нормально обучиться можно только на 3-5 фичах. Усредняться с шумом - это переобучение на шум.
П.С. Вместо 20+летней NeuroPro можно что-то поновее использовать. R, Питон, или если сложно разбираться с ними, то используйте EXE Катбуста, как тут https://www.mql5.com/ru/articles/8657 Можно автоматически запускать EXE прямо из советника, т.е. полностью автоматизировать процесс. Пример https://www.mql5.com/ru/forum/86386/page3282#comment_49771059
П.П.С Ночью лучше спать. Здоровье не купишь, даже если миллионы на этих сетях заработаете.
Благодарю за пост
Грааль мне видится не в суммировании, а в расщеплении числа
UPD
И задача нейронов не получать множество чисел, а получить одно число на вход. Умножить на вес и пустить через нелинейную функцию. Тогда получится анализ данных, а не варка супа.
То есть, имеется одно число (входное значение, либо выход нейрона), и это число расщепляется двумя и более нейронами следующего слоя. Они должны быть независимыми от других нейронов.
Этакий отдел, который занимается своим делом.
Затем все эти отделы должны отчитаться перед начальником - выходным нейроном. Он делает вывод на основе выходов всех конечных нейронов. Со своими весами.
Таким образом мы уменьшаем искажение информации и увеличиваем её чтение.
Грааль мне видится не в суммировании, а в расщеплении числа
Ну листья получают разделением данных, хоть на 1000000 разных частей/листьев. Но результат/ответ листа - среднее входящих в него примеров/строк.
Так что расщепление есть, но и суммирование тоже. Можно поделить до 1 примера в листе, но это 100% переобучение на шум. Деревья так же в условиях шума, не должны глубоко делиться, для хорошего форварда (это как у вас число нейронов лучше - небольшое).
Уткнулся в такую вещь, как спред и комиссия. Ломают нейросеть быстро.
Спасибо МТ5, ты умеешь отрезвлять. Давно надо было пересесть на тебя с МТ4
Прав был @Andrey Dik много лет назад - грааль ещё лежит в районе спреда с комиссией.
Как только их убираешь - нейронка граалит на форвардах.
Ну листья получают разделением данных, хоть на 1000000 разных частей/листьев. Но результат/ответ листа - среднее входящих в него примеров/строк.
Так что расщепление есть, но и суммирование тоже. Можно поделить до 1 примера в листе, но это 100% переобучение на шум. Деревья так же в условиях шума, не должны глубоко делиться, для хорошего форварда (это как у вас число нейронов лучше - небольшое).
Блин, какая тема обширная. Теперь листья гуглить. Лет через 5 дойду до ветки МО, но перечитывать её не буду
Пересел с Тойоты на старый спортивный автомобиль
Поскольку МТ5 ограничен в количестве оптимизируемых параметров, пересел на программу NeuroPro 1999 года, из здешней статьи - Нейросети бесплатно и сердито - соединяем NeuroPro и MetaTrader 5
Увеличил архитектуру в количестве: в МТ5 было 5-5-5, а здесь уже 10-10-10 и обучение уже настоящее (точнее сказать - стандартное, методом обратного распространения ошибки и прочих там внутренних прибамбасов внутри программы. Автор которой наплевал на неё и не собирается даже обновлять раритет - исходя из его ответов на мои вопросы, у него нет интереса развивать NeoroPro, внедрять многопоточность, современные методы и тд
Уткнулся в такую вещь, как спред и комиссия. Ломают нейросеть быстро.
Спасибо МТ5, ты умеешь отрезвлять. Давно надо было пересесть на тебя с МТ4
Прав был @Andrey Dik много лет назад - грааль ещё лежит в районе спреда с комиссией.
Как только их убираешь - нейронка граалит на форвардах.
Любопытное явление.
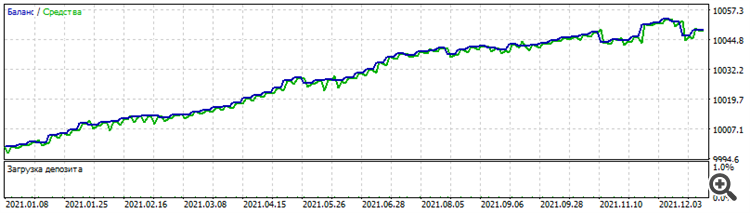
Обучение по архитектуре "расширение", когда первый слой состоит из 1 нейрона, затем 2-ой слой из 2-х, 3-ий из 3-х и тд дало такой забавный и всё-же любопытный сет:
Результаты сета на периоде оптимизации EURUSD точно такие же и на других долларовых парах:
Оптимизация за 2021 год на EURUSD
Тест на GBPUSD за 2021 год
Тест на AUDUSD за 2021 год
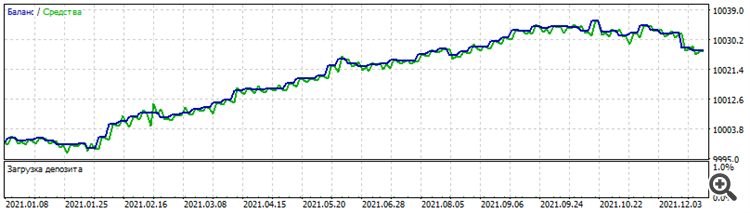

Тест на NZDUSD за 2021 год
Почему только любопытные? Да потому что это мёртвый сет, не работает ни до, ни после. Но, сам факт, что работает на нескольких долларовых парах на том же периоде, учитывая, что между ними хоть и есть какая-то корреляция, ценообразование у каждой пары всё-таки разное.
Любопытное явление.
Обучение по архитектуре "расширение", когда первый слой состоит из 1 нейрона, затем 2-ой слой из 2-х, 3-ий из 3-х и тд дало такой забавный и всё-же любопытный сет:
Результаты сета на периоде оптимизации EURUSD точно такие же и на других долларовых парах:
Оптимизация за 2021 год на EURUSD
Тест на GBPUSD за 2021 год
Тест на AUDUSD за 2021 год
Тест на NZDUSD за 2021 год
Почему только любопытные? Да потому что это мёртвый сет, не работает ни до, ни после. Но, сам факт, что работает на нескольких долларовых парах на том же периоде, учитывая, что между ними хоть и есть какая-то корреляция, ценообразование у каждой пары всё-таки разное.
да нет, разные
на всех, кроме евро, одна треть баланса в конце топчется на одном месте